Umbriel to mój serwer. W pliku crontab są następujące nastawy:
## co 120s */2 * * * * /home/tomek/bin/mevo_get.sh ## Codziennie 2:33 po północy 33 2 * * * /home/tomek/bin/mevo_process_yesterday.sh ## Raz w miesiącu 2:43 (musi być po mevo_process_yesterday.sh) 43 3 1 * * /home/tomek/bin/mevo_process_lastmonth.sh
Uruchamiany co 2 minuty mevo_get.sh pobiera (mevo_get_store.pl) ze strony plik locations.js, wyciąga z niego najważniesze dane, które dopisuje do pliku YYYYMMDD_log.csv
Uruchamiany raz dziennie mevo_process_yesterday.sh agreguje (robi to skrypt mevo_yesterday_f.pl) dane z pliku YYYYMMDD_log.csv, które zapisuje do pliku MEVO_DAILY_BIKES.csv.
Zawartość MEVO_DAILY_BIKES.csv jest następująca:
day;bikes;zb;dist.total;ga;gd;sop;tczew;rumia;s10111;s10111d;s10112;s10112d;zstat;sstat;\ gd0p;ga0p;sop0p;tczew0p;rumia0p;gd1p;ga1p;sop1p;tczew1p;rumia1p;slope3;\ slope5;stage2;stage4;stage6;stage8;stage10;stage12;stage14;stage16;stage18;stage20;stage99
gdzie:
bikes -- łączna liczba rowerów dostępnych/wykazanych w ciągu dnia w plikach locations.js;
zb -- łączna liczba rowerów wykazanych, które nie były używane (zero-bikes);
dist.total -- dystans łącznie (liczony po prostej);
ga/gd/sop/tczew/rumia -- dystans łącznie (liczony po prostej dla miast; jeżeli rower przejechał z miasta do miasta to każde miasto dostaje połowę);
s10111/s10112 --przeciętna liczba rowerów na stacjach s10111/s10112 liczona jako $\sum_{i=1}^N r_i / N$ (N -- liczba pobrań pliku locations.js, jeżeli pobrano wszystkie to $24 \times 30 = 720$);
s10111d/s10112d -- przeciętna liczba rowerów na stacjach s10111/s10112 w godzinach 5--23;
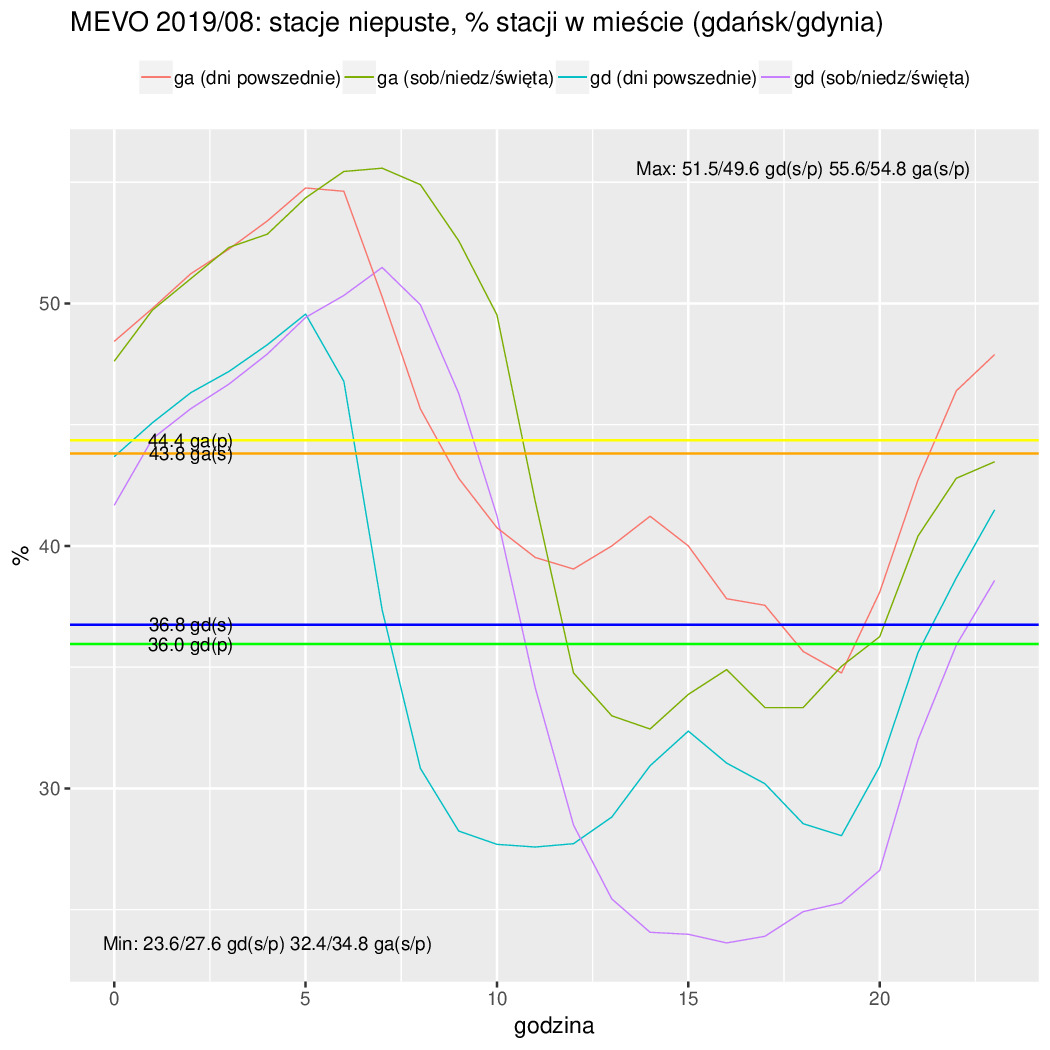
zstat -- przeciętny odsetek stacji bez rowerów (zero-stations), liczony jako $\sum_{i=1}^N s_i / (S \times N)$ (N -- liczba pobrań pliku locations.js, $S$ -- liczba stacji w systemie);
sstat -- przeciętny odsetek stacji z maksimum jednym rowerem (single-stations), liczony jako $\sum_{i=1}^N s_i / (S \times N)$;
gd0p/ga0p/sop0p/tczew0p/rumia0p -- przeciętny odsetek stacji bez rowerów (zero-stations) dla miast (gd/ga/sop/tczew/rumia). Liczony jak zstat tylko $S$ -- liczba stacji w danym mieście oczywiście;
gd1p/ga1p/sop1p/tczew1p/rumia1p -- przeciętny odsetek stacji z maksimum jednym rowerem (single-stations) dla miast (gd/ga/sop/tczew/rumia). Liczony jak sstat tylko $S$ to liczba stacji w danym mieście oczywiście a nie ogółem;
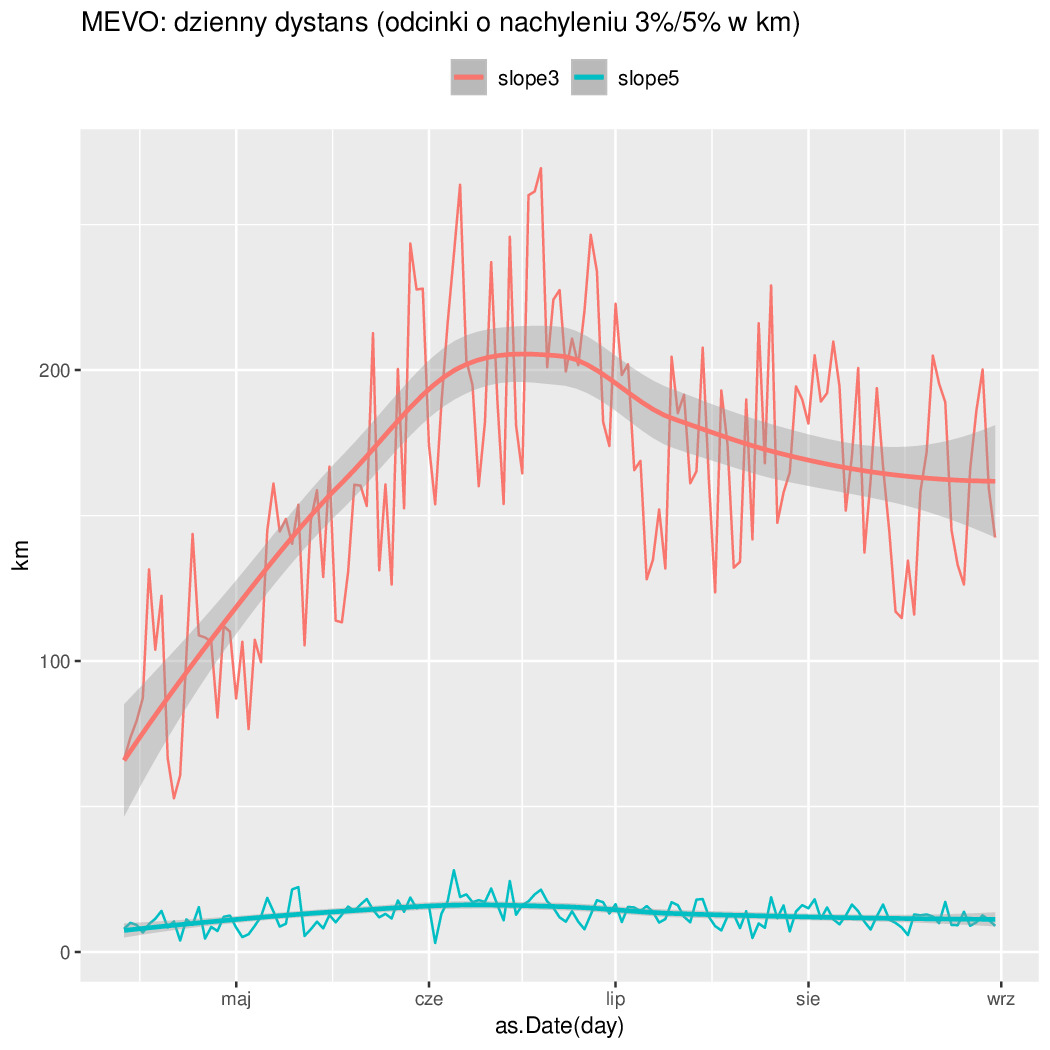
slope3/slope5 -- łączny dystans przejechanych odcinków o nachyleniu przeciętnym 3%/5%;
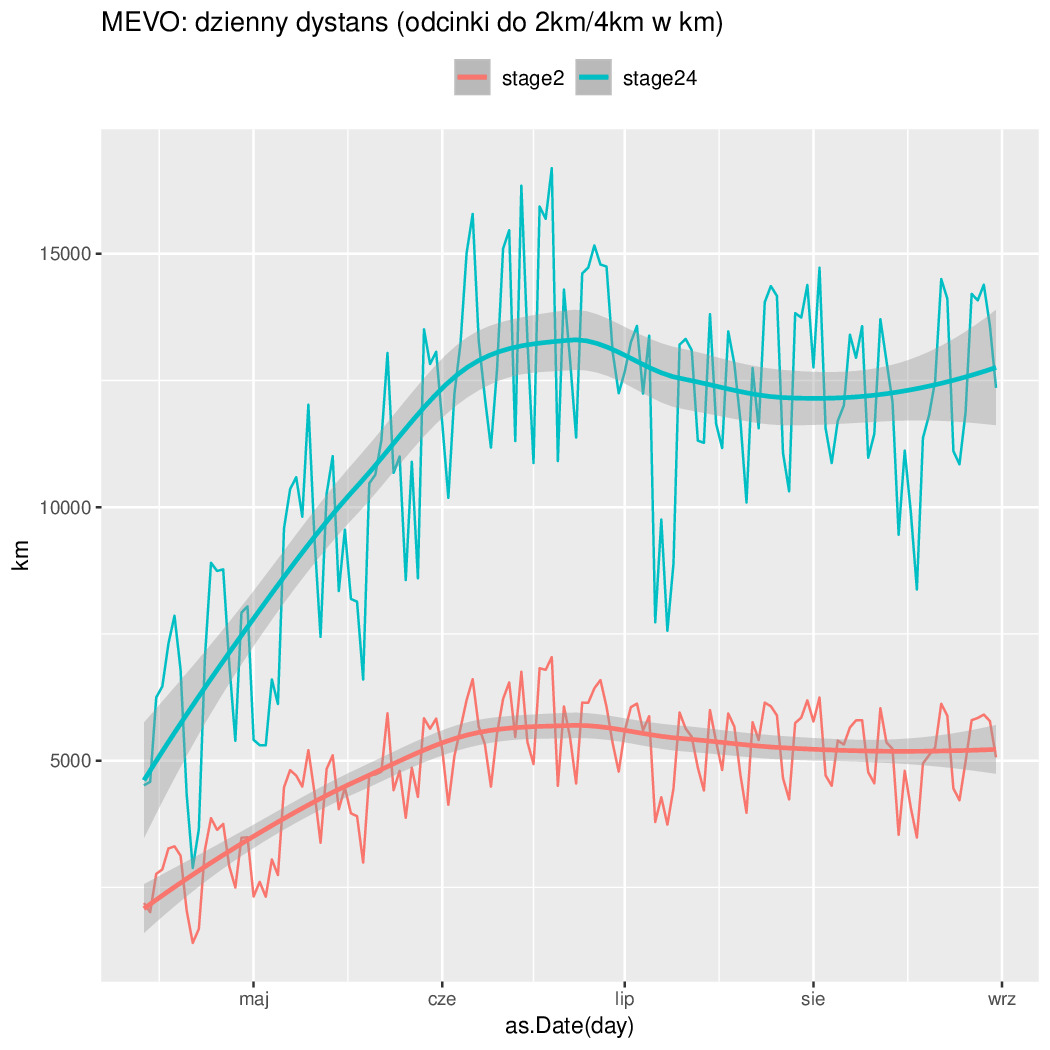
stage2/stage4 itd -- łączny dystans przejechanych odcinków o dlugości 0--2km, 2--4km itd...
Następnie uruchamia skrypt mevo_daily_report.pl, który z pliku MEVO_DAILY_BIKES.csv wyciąga ostatni i przedostatni dzień; kompiluje raport dzienny tj. oblicza podstawowe statystyki, tworzy raport tekstowy (ograniczony do 280 znaków bo Twitter więcej nie potrafi) tworzy bardziej obszerny raport w formacie TeXa, konwertowany później do obrazka (za pomocą XeTeXa/converta) Publikuje na twitterze (twitter_post.py) obrazek i ww raport tekstowy.
Następnie uruchamia skrypt mevo_yesterday_hr_f.pl, który agreguje dane z pliku YYYYMMDD_log.csv w ujęciu godzinowym. Zapisuje wynik do pliku MEVO_STAT_BIKES_HRS_YYYYMM.csv (plik przechowuje zagregowane dane godzinowe dla miesiąca). Ten skrypt niczego nie publikuje na twitterze
Plik MEVO_STAT_BIKES_HRS_YYYYMM.csv ma następującą zawartość:
day;hr;bikes;nzstations;bikesGD;bikesGA;bikesSP;nzsGD;nzsGA;nzsSP
day/hr -- dzień i godzina;
bikes -- przeciętna liczba rowerów na wszystkich stacjach (definiowana jako suma rowerów/suma pomiarów);
nzstations -- przeciętna liczba stacji z minimum jednym rowerem (non-zero stations);
bikesGD/bikesGA/bikesSP -- przeciętna liczba rowerów na stacjach w mieście
nzsGD/nzsGA/nzsSP -- przeciętna liczba stacji z minimum jednym rowerem w mieście
Wykonywany raz w miesiąc mevo_process_lastmonth.sh uruchamia mevo_monthly_report.pl, który agreguje w skali miesiąca dane z pliku MEVO_DAILY_BIKES.csv; kompiluje raport miesięczny tj. oblicza podstawowe statystyki, tworzy raport tekstowy i obrazek (w sposób analogiczny jak raport dzienny) publikuje na Twitterze (twitter_post.py) obrazek i raport tekstowy.
Następnie uruchamia skrypt mevo_stat_bikes_hrs.pl, który konwertuje/łączy MEVO_DAILY_BIKES.csv i MEVO_STAT_BIKES_HRS_YYYYMM.csv do pliku MEVO_HRS.csv. Na podstawie danych z pliku MEVO_HRS.csv tworzone są wykresy, do czego wykorzystywany jest R.
Plik MEVO_HRS.csv ma następującą zawartość:
dow;dowNN;hr;bikes;bikesGd;bikesGa;bikesSp;stats;statsGd;statsGa;statsSp;\ pbikes;pbikesGd;pbikesGa;pbikesSp;pstats;pstatsGd;pstatsGa;pstatsSp
gdzie:
dow -- dzień tygodnia (0 -- powszedni; 1 -- święta, soboty i niedziele)
dowNN -- liczba dni powszednich i niepowszednich (w miesiącu)
hr -- godzina
bikes/bikesGd/bikesGa/bikesSp -- przeciętna liczba rowerów na wszystkich stacjach i na stacjach w mieście;
stats/statsGd/statsGa/statsS -- przeciętna liczba stacji z minimum jednym rowerem ogółem i w mieście;
pbikes/pbikesGd/pbikesGa/pbikesSp -- przeciętna % rowerów na stacjach ogółem i w mieście (% średniej dobowej);
pstats/pstatsGd/pstatsGa/pstatsSp -- przeciętny % stacji z minimum jednym rowerem ogółem i w mieście (% średniej dobowej);
Konkretnie zaś uruchamiany jest R ze skryptem mevo_hrly.R, który generuje wykresy do pliku Mevo_hrly_YYYYMM.pdf. Następnie Mevo_hrly_YYYYMM.pdf jest konwertowane (convert) do formatu JPG (Mevo_hrly_YYYYMM-0.jpg, Mevo_hrly_YYYYMM-1.jpg i Mevo_hrly_YYYYMM-2.jpg).
Publikuje na twitterze (twitter_post.py) Mevo_hrly_YYYYMM-*.jpg
Uruchamia R ze skryptem mevo_daily_bikes.R. Uruchamia R ze skryptem mevo_daily_zstats.R. Skrypty generują wykresy do plików mevo_daily_bikes.pdf i mevo_daily_zstats.pdf. Pliku mevo_daily_bikes.pdf/mevo_daily_zstats.pdf są zamieniane na format JPG. Publikuje na twitterze (twitter_post.py) mevo_daily_bikes.jpg/mevo_daily_zstats.jpg.
Reasumując tworzone/wykorzystywane są następujące pliki danych: YYYYMMDD_log.csv (dzienny log dopisywany co 2min); MEVO_DAILY_BIKES.csv (dzienny log aktualizowany co 24h (o 2:33)); MEVO_STAT_BIKES_HRS_YYYYMM.csv (dzienny log godzinowy aktualizowany co 24h (o 2:33)) MEVO_HRS.csv (plik tymczasowy z MEVO_DAILY_BIKES.csv/MEVO_STAT_BIKES_HRS_YYYYMM.csv (raz w m-cu))
Przy okazji się okazało że XeTeX na Debiana 4.9.51-1 (chyba Stretch) w wersji Armel jest epicko spieprzony. Konkretnie nie może znaleźć fontów systemowych, bo szuka jakiś dziwnych obciętych nazw. Przykładowo Iwona-Reg.otf nie znajduje, bo szuka Iwona-Reg.. Dziwaczny błąd. Zrobiłem link ln -s Iwona-Reg. Iwona-Reg.otf i działa bo mi się nie chciało tracić czasu na poprawienie tego lepiej.
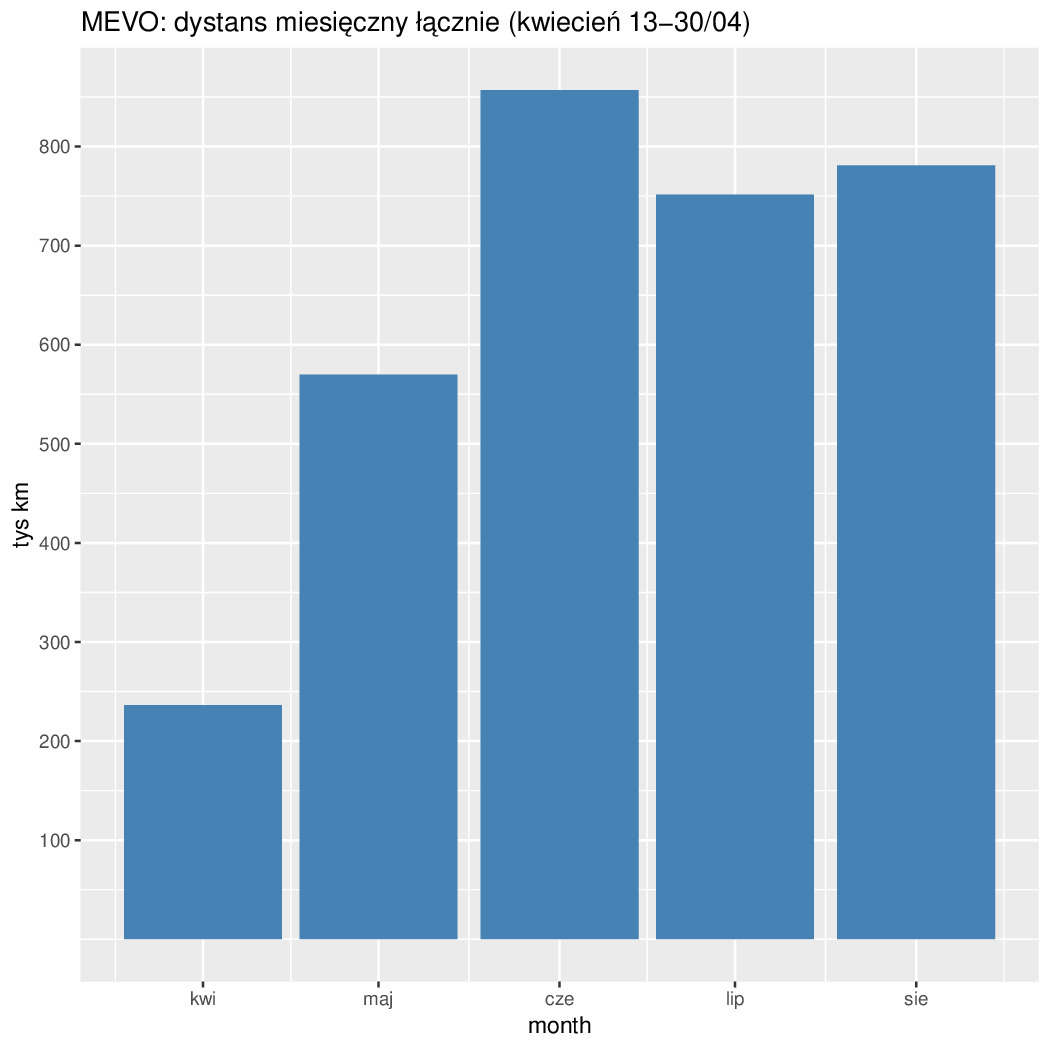
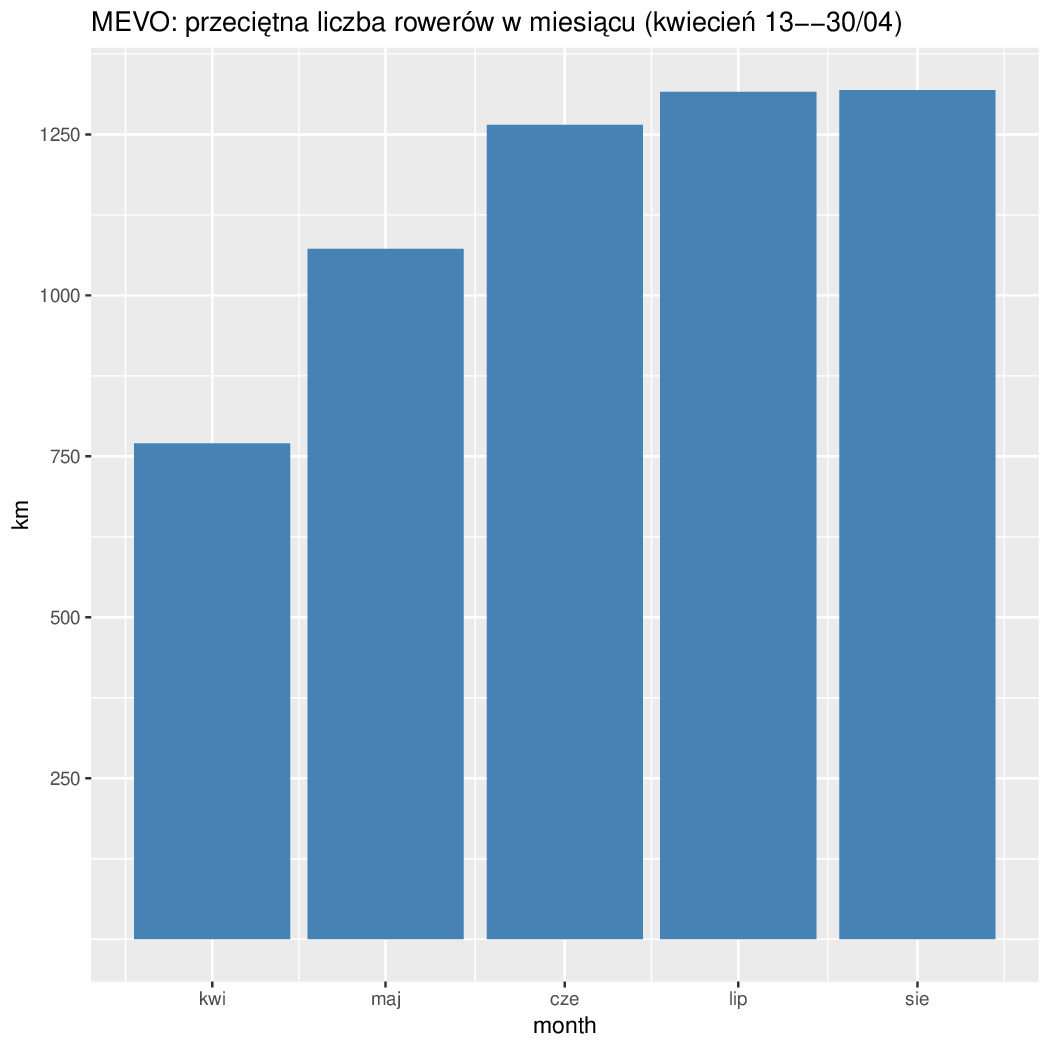
Anyway za 4 ostatnie miesiące zbiorcza statystyka wygląda następująco (dystanse w tys km za wyjątkiem Dist/r -- miesięczny średni przebieg roweru w km):
YYMM Days Dist %Change Dist/r GD %Change GA %Change SOP %Change ------------------------------------------------------------------------ 201905 31 569.8 241.1 531.5 359.5 235.6 126.6 267.3 42.9 244.3 201906 30 856.9 150.4 677.4 501.4 139.5 220.5 174.2 76.2 177.7 201907 31 751.4 87.7 570.9 438.8 87.5 187.9 85.2 69.0 90.5 201908 31 781.0 103.9 592.3 466.5 106.3 180.3 96.0 73.3 106.3 ------------------------------------------------------------------------
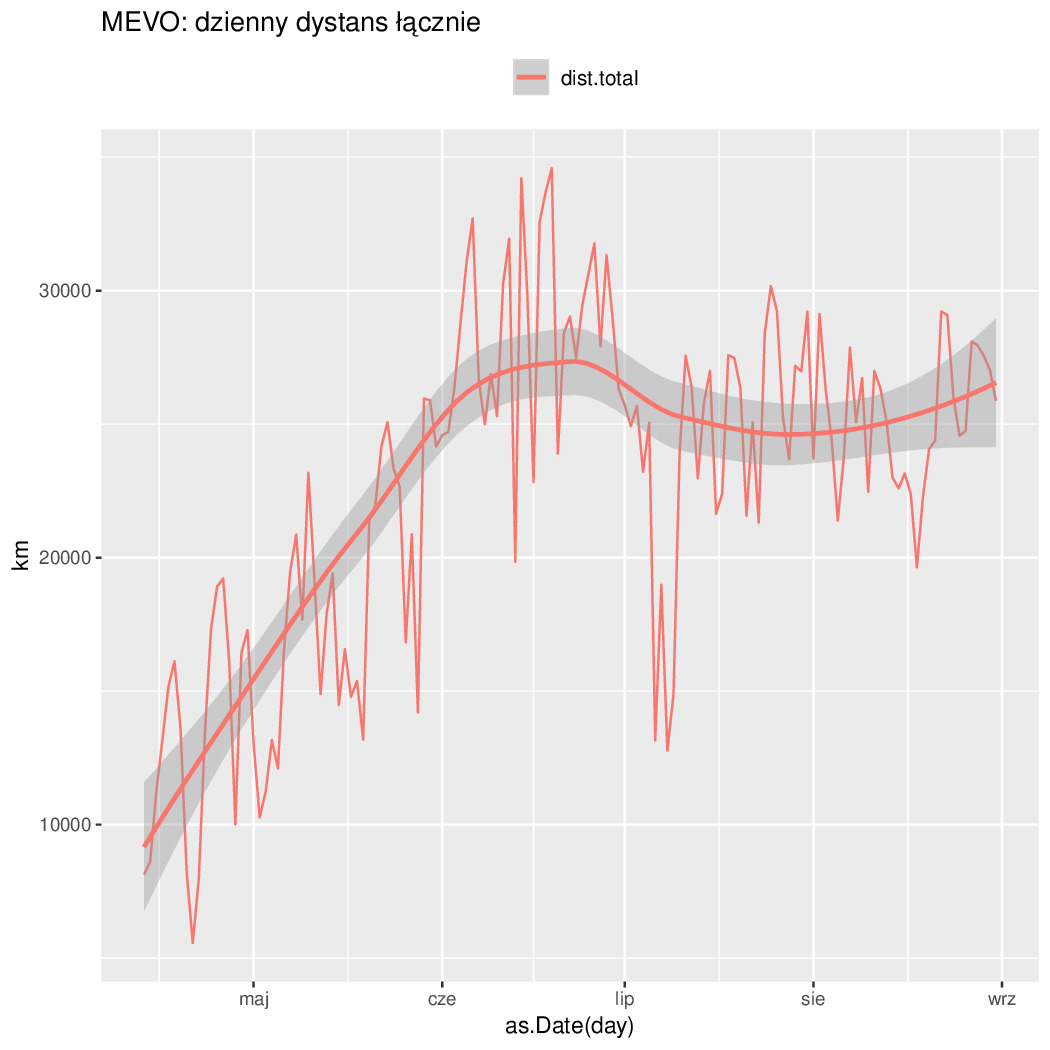
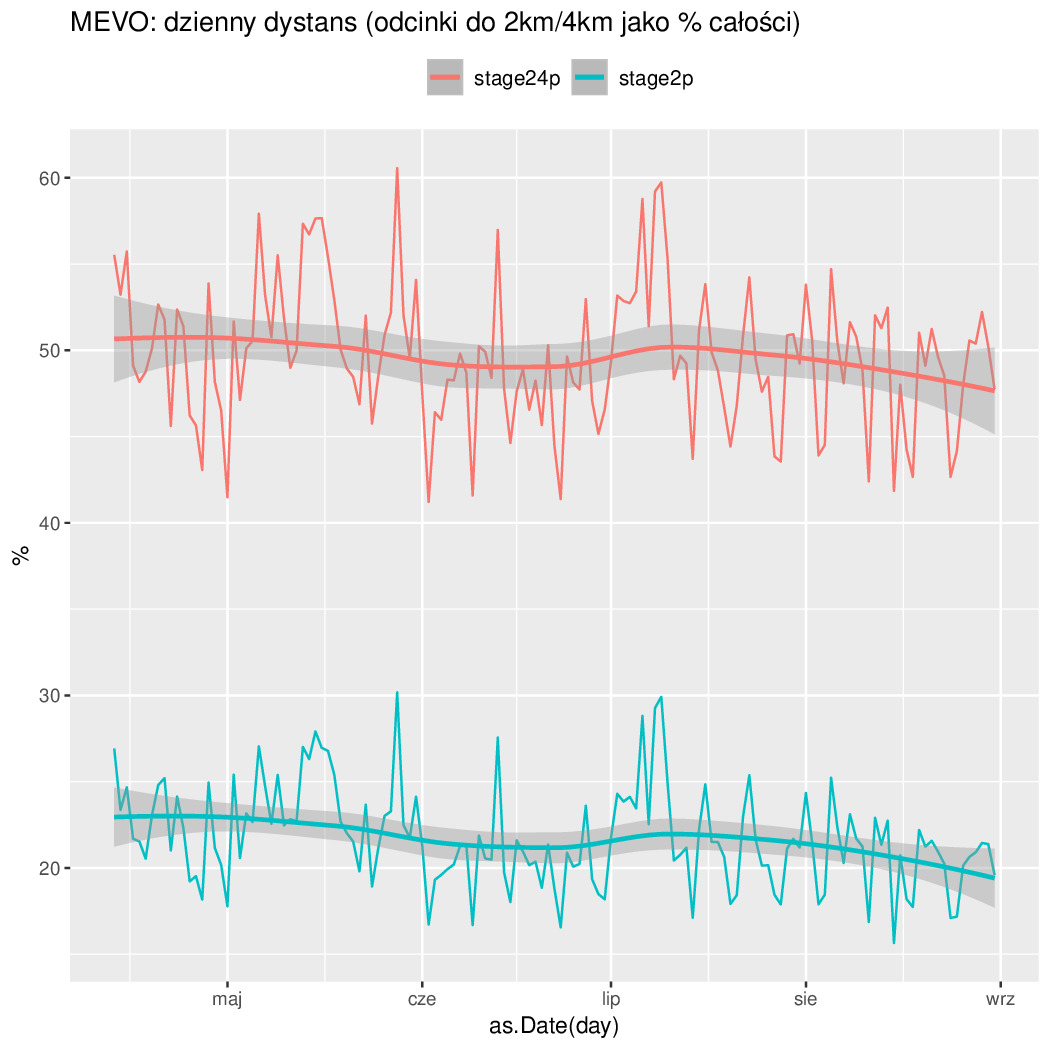
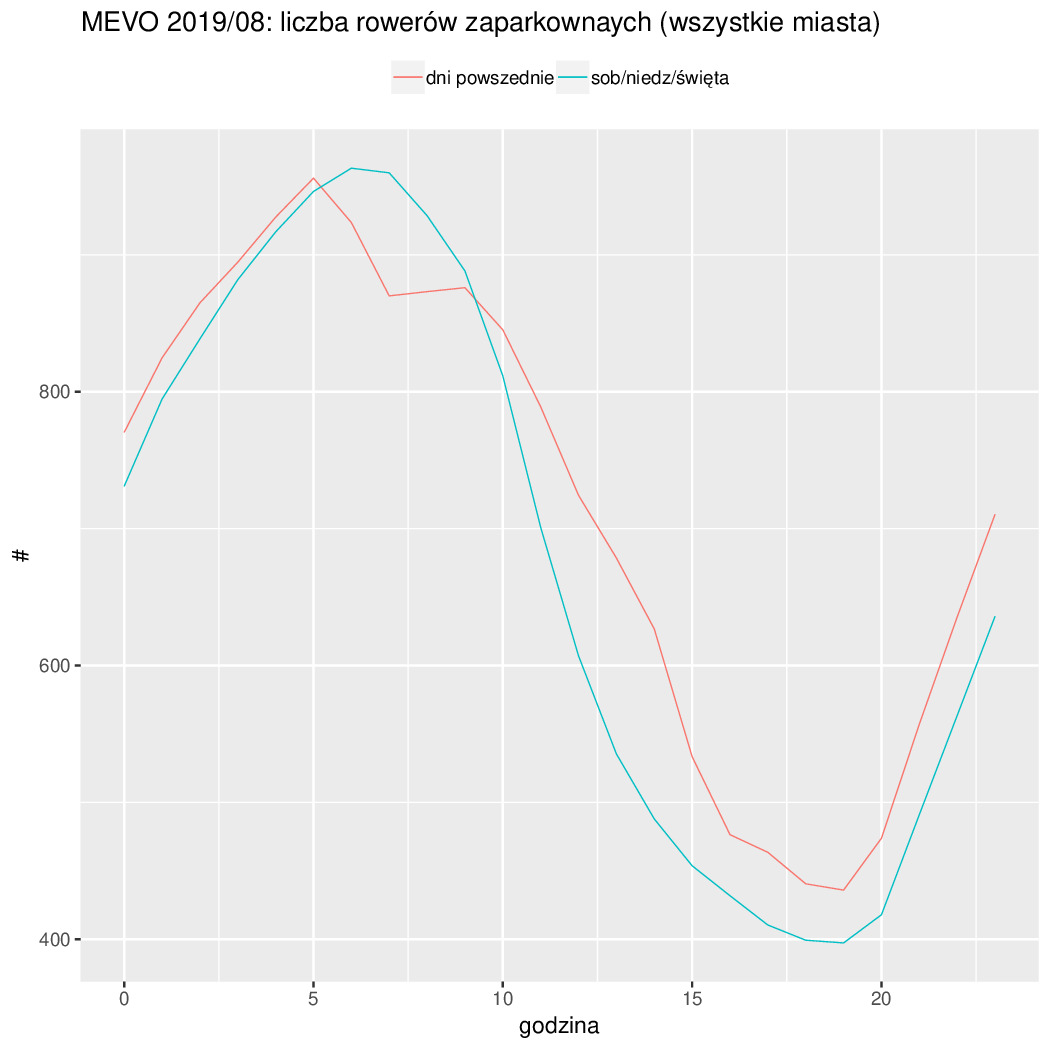
Czyli najlepiej było w Czerwcu, bo jeżdżą wcale nie przyjezdni tylko miejscowi do roboty. Potwierdza to też zmienność tygodniowa (mniej się jeździ w soboty i niedziele). Połowa odcinków ma mniej niż 4km (liczone w linii prostej przypominam). Długość odcinków o nachyleniu 3% jest śladowa (a 5% to już ślad w śladzie). Resztę na wykresach widać...
Warto jest zapoznać się z tak ciekawymi informacjami.
OdpowiedzUsuń