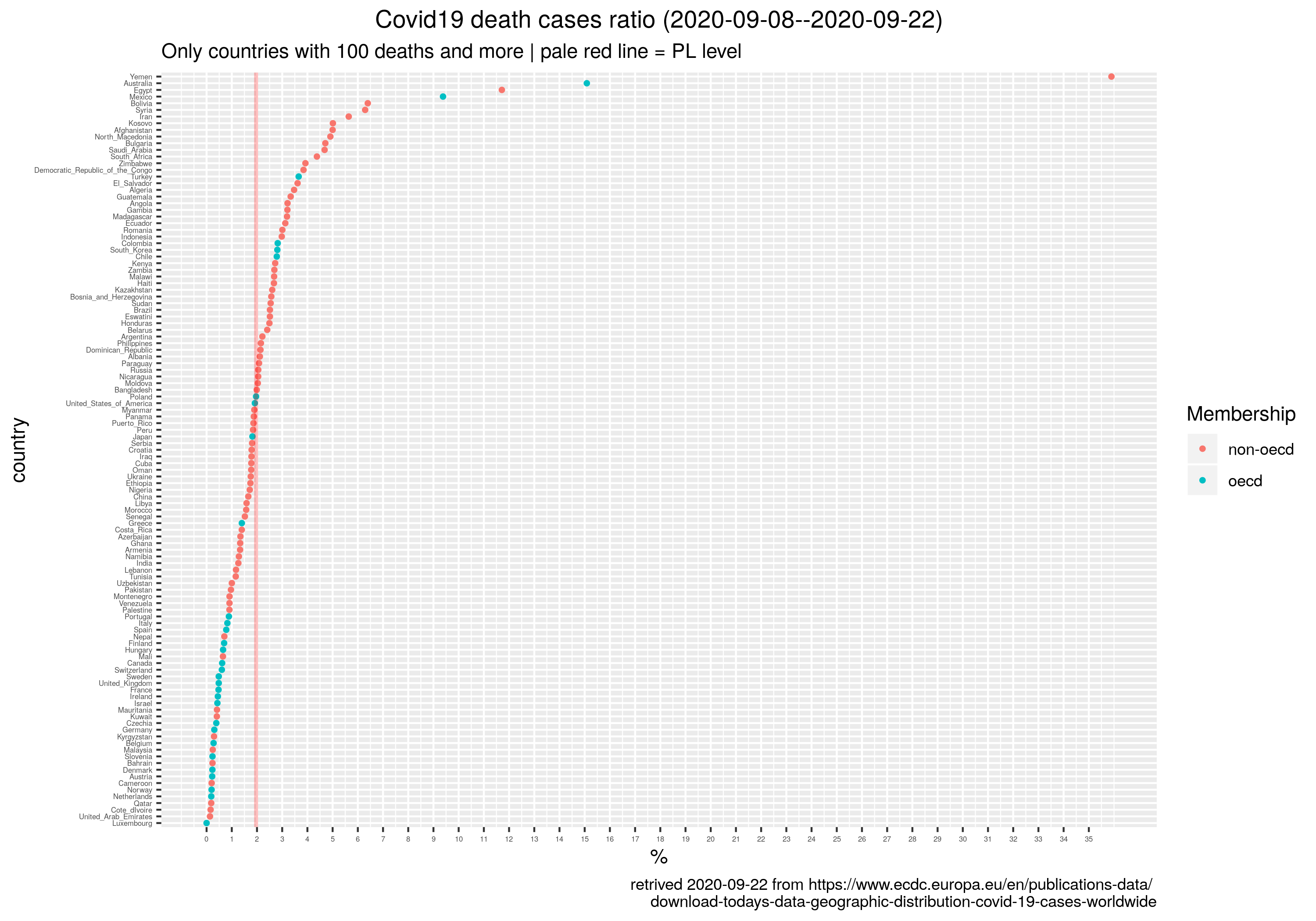
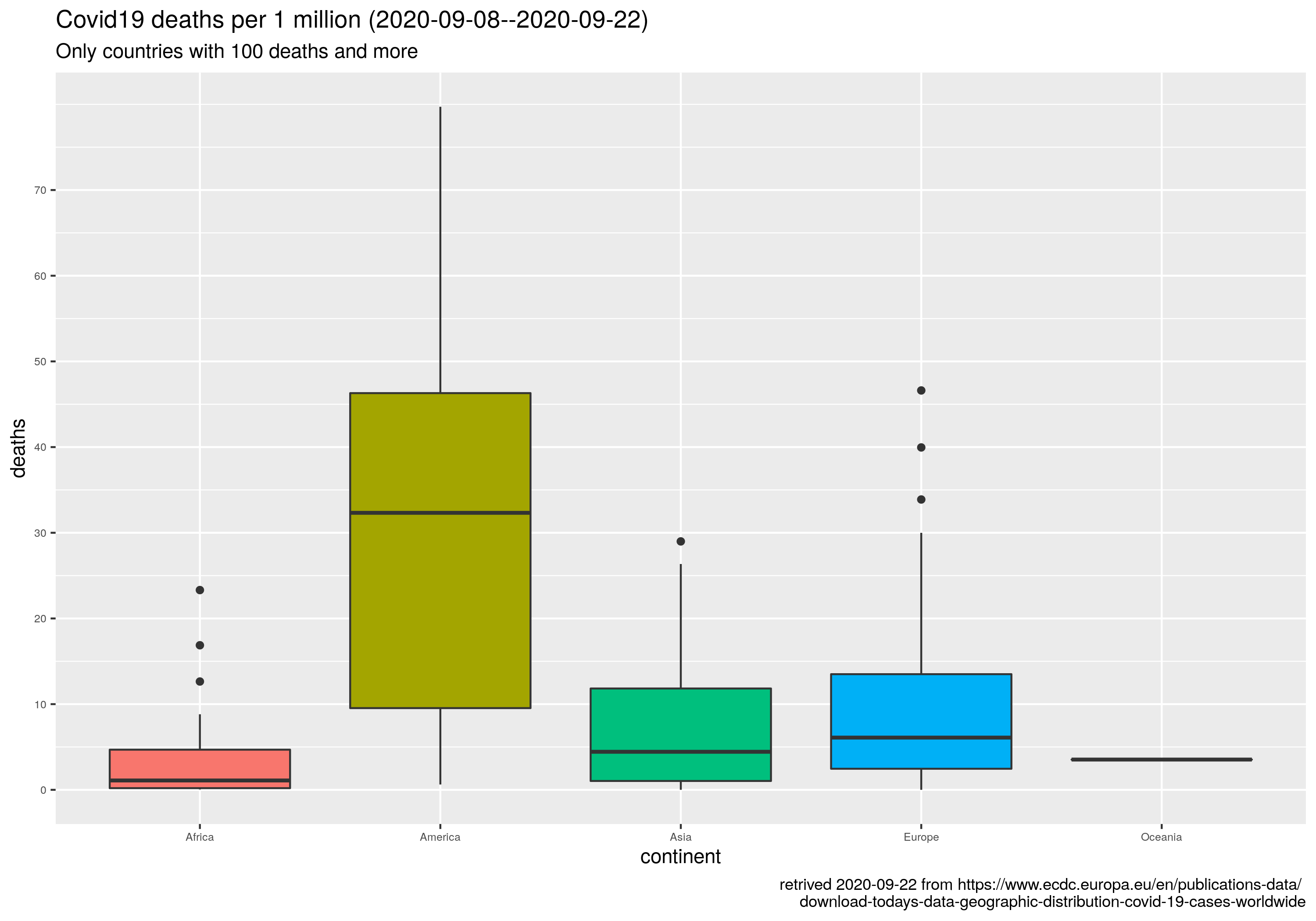
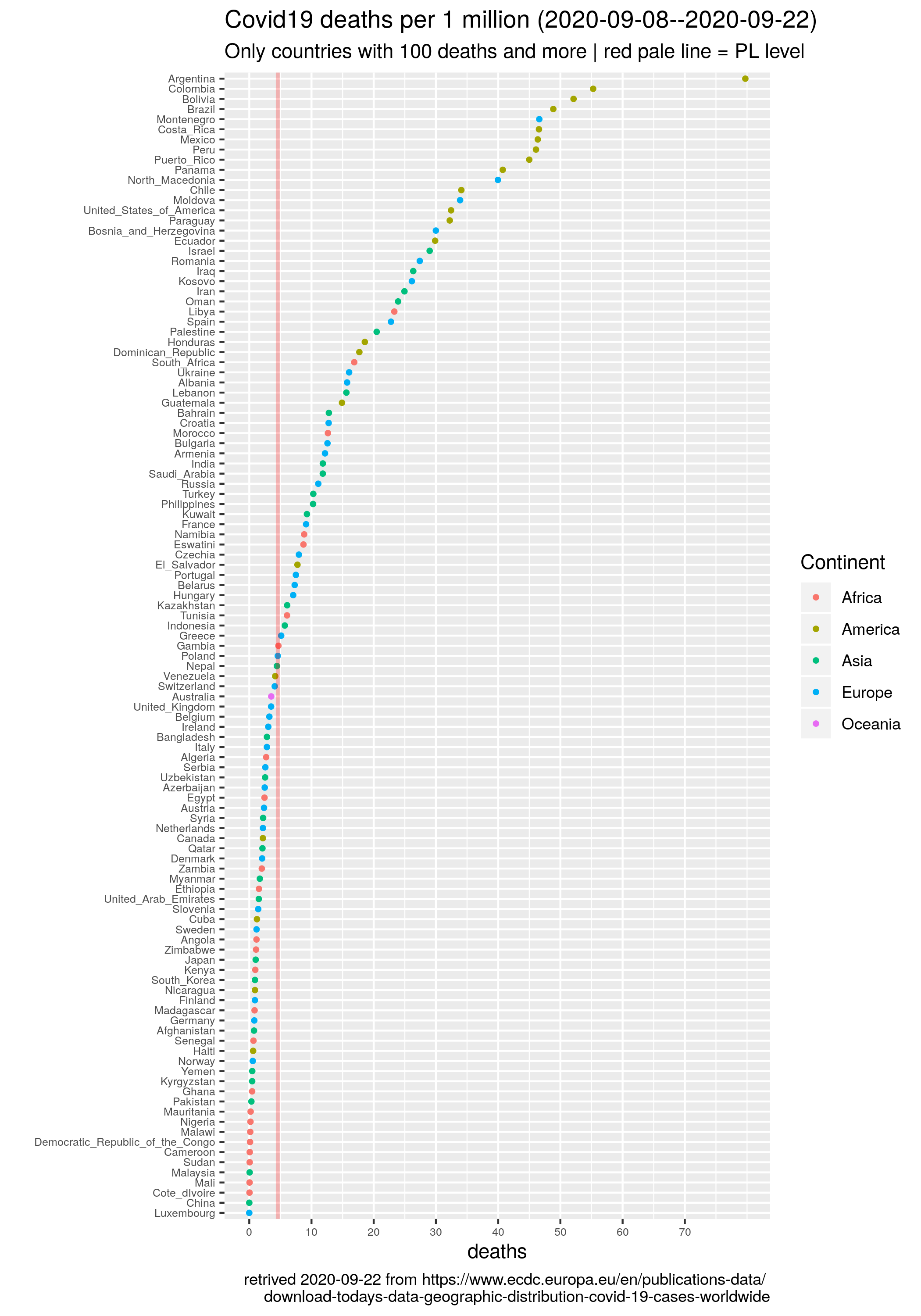
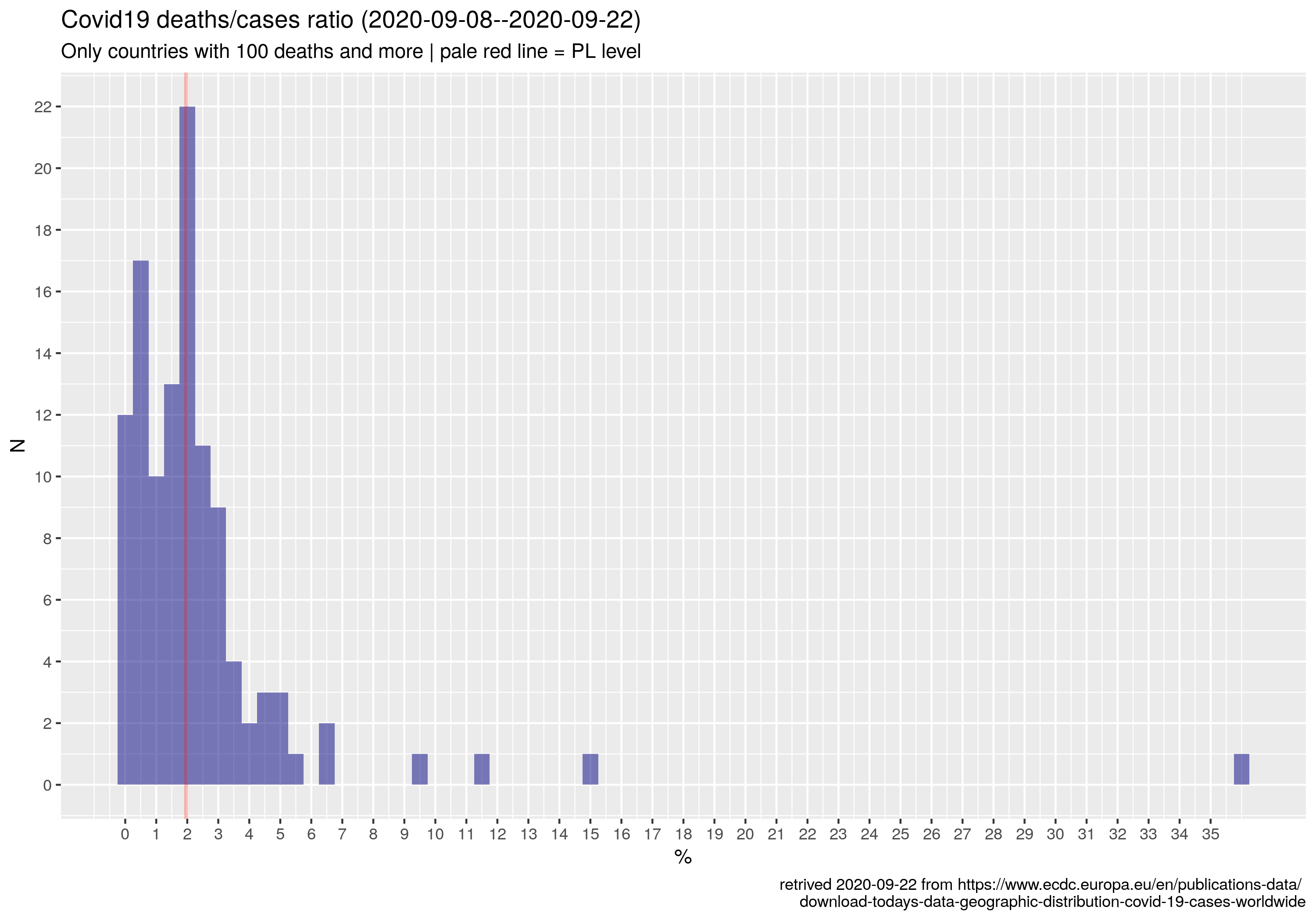
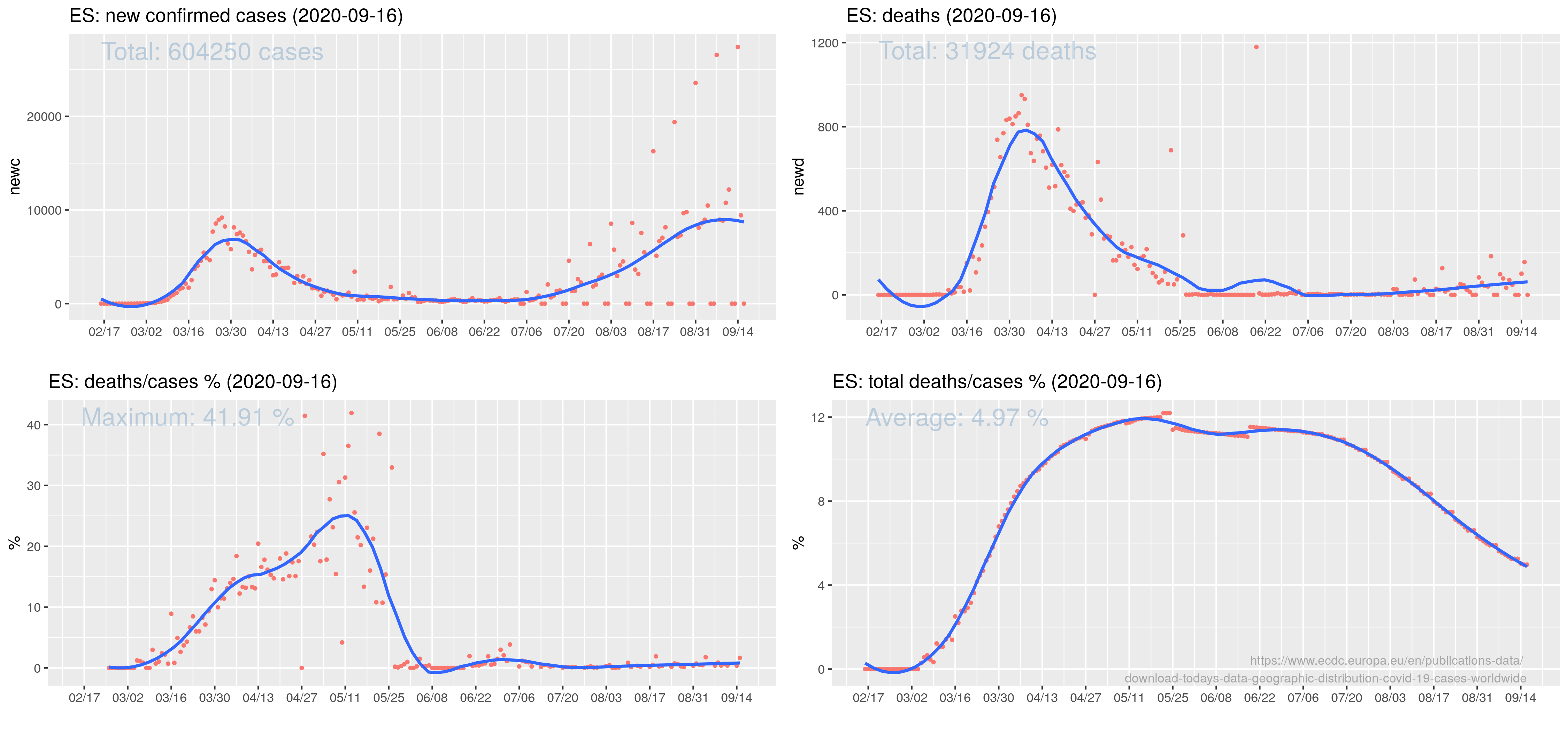
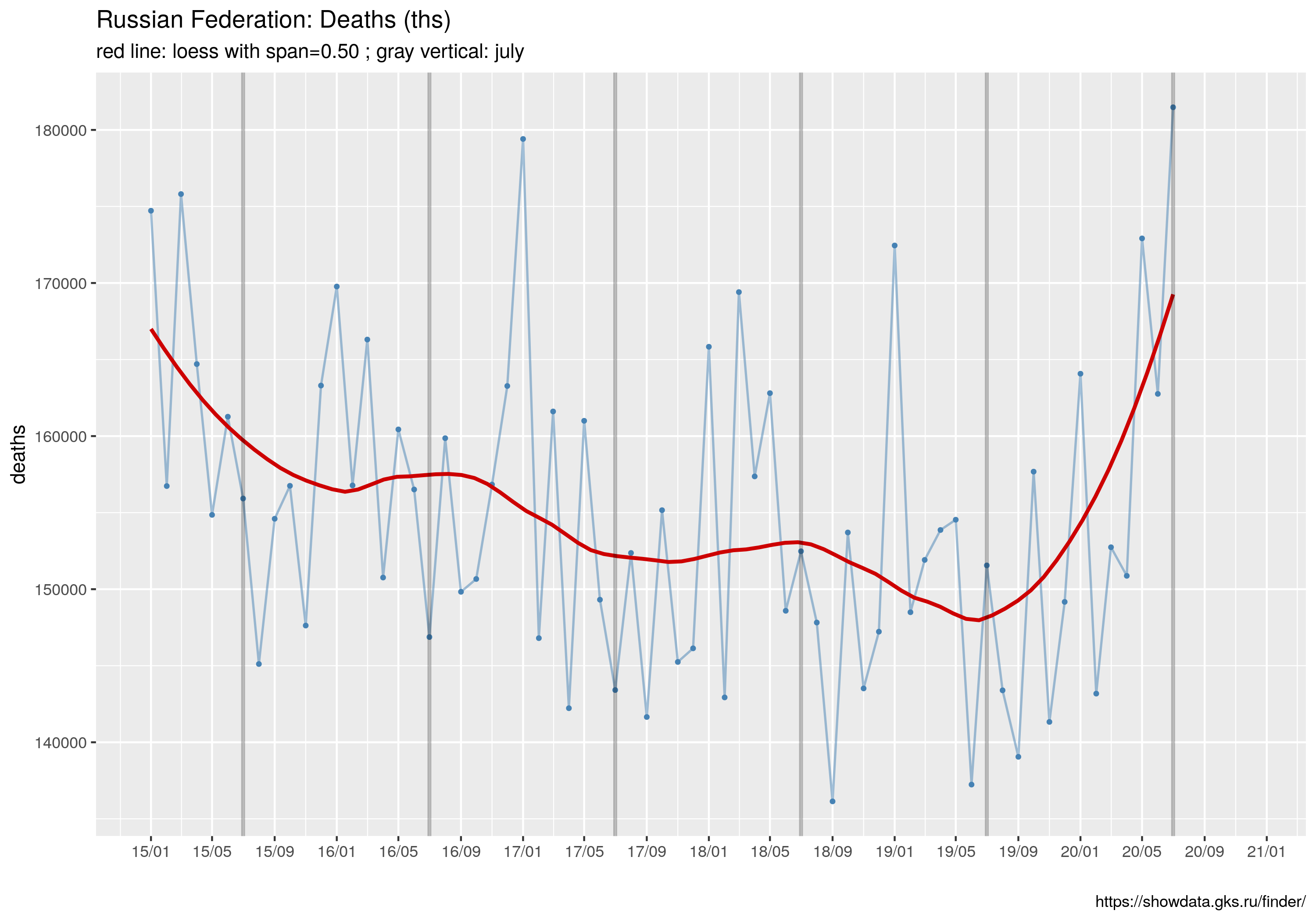
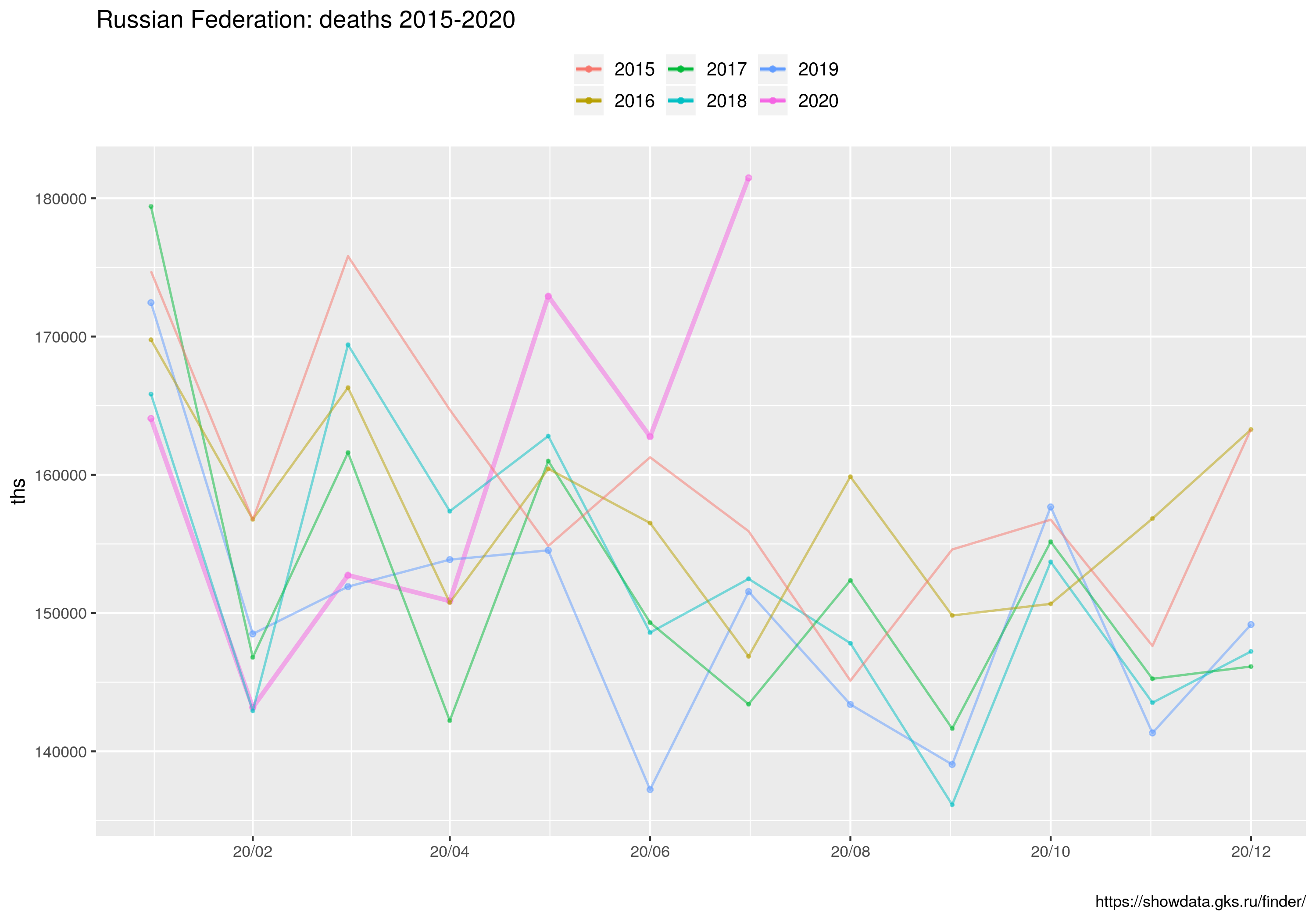
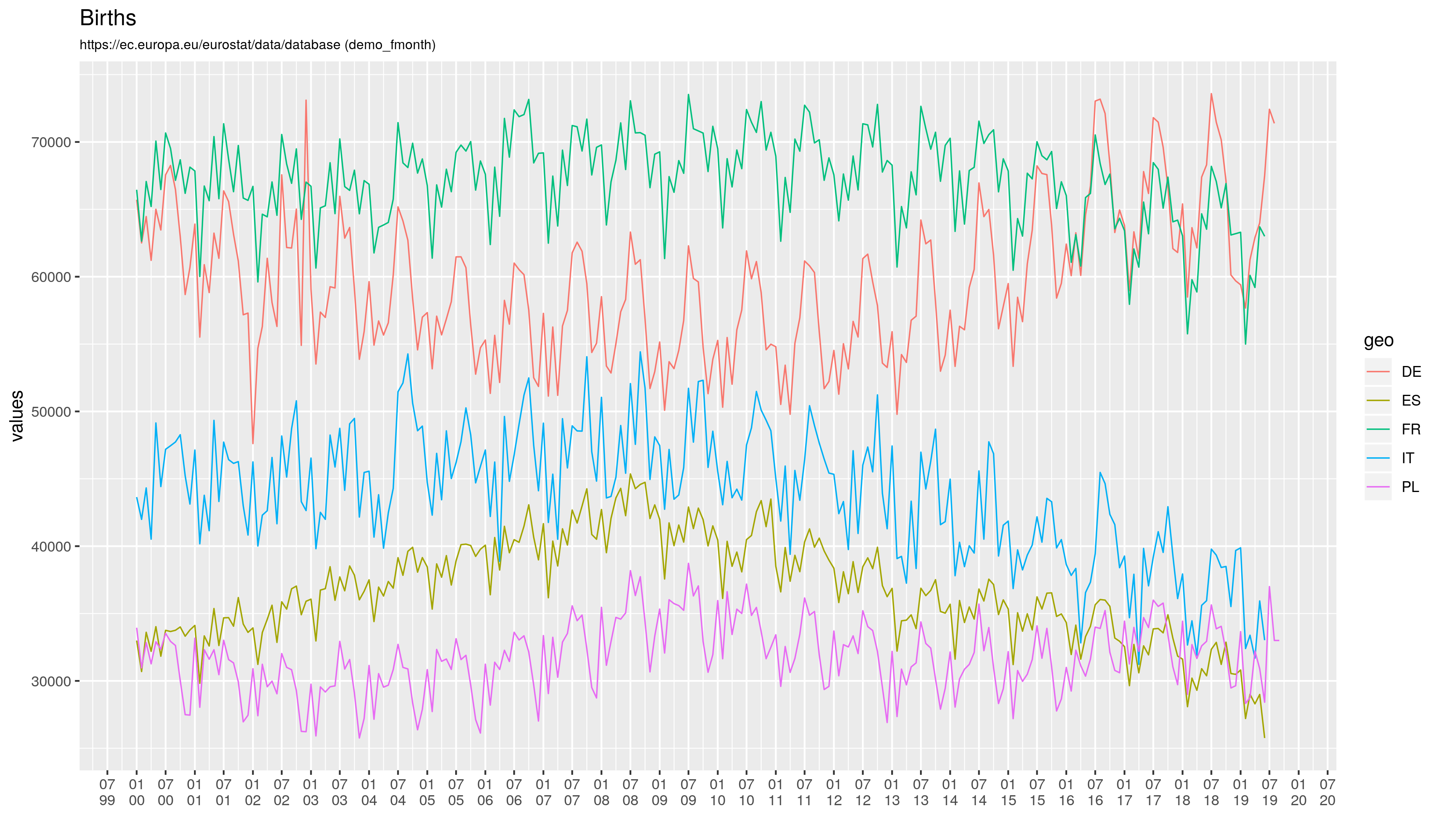
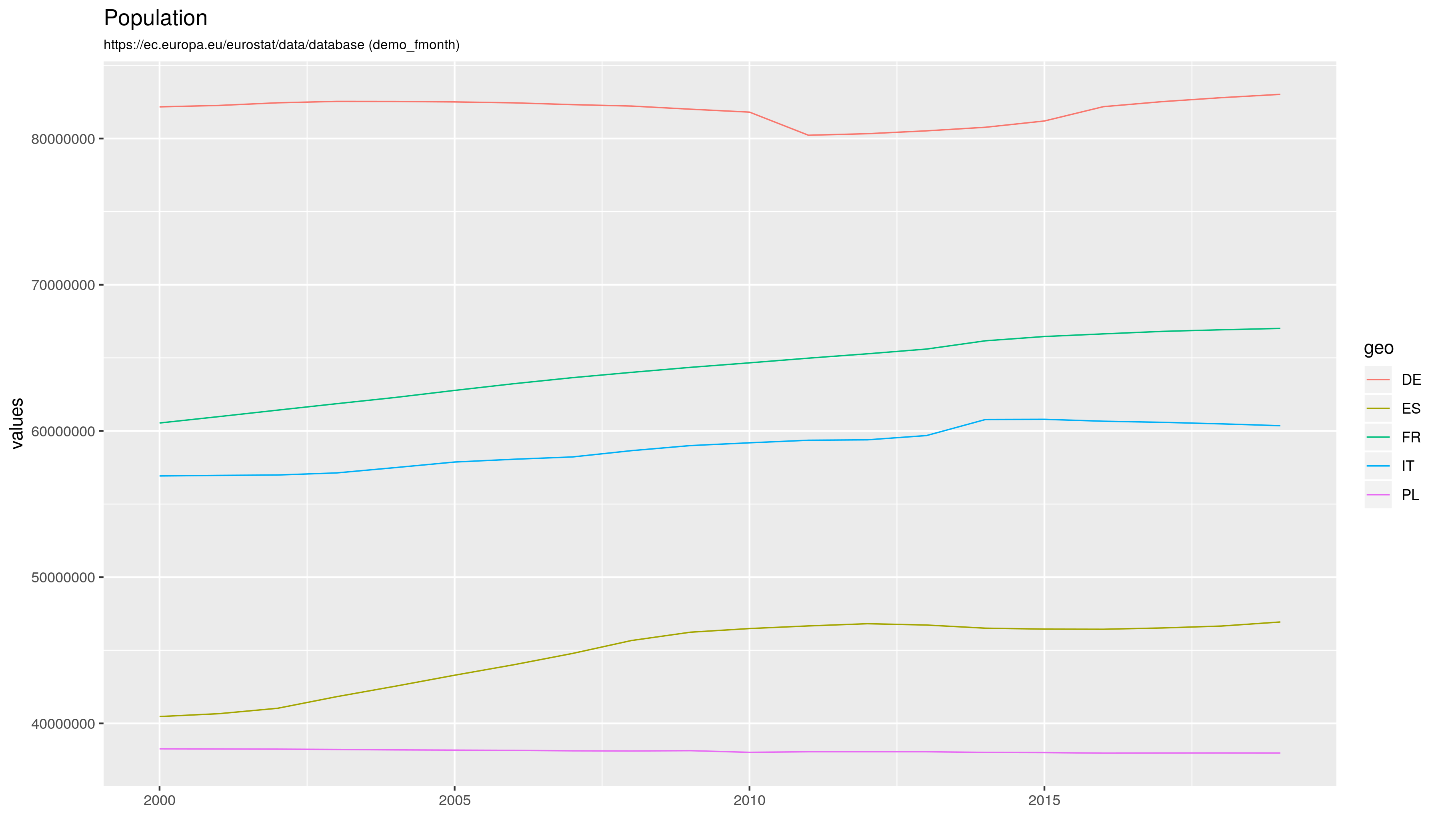
Że czwarta fala szaleje to nadmiarowe zgony w Europie sobie liczę, w której to kategorii Polska cytując poetę trzecie miejsce w świecie (Kazik Staszewski/Amnezja)
Dane pobieram za pomocą get_eurostat (pakiet eurostat):
library("eurostat")
# demo_r_mwk_ts = Deaths by week and sex
z <- get_eurostat("demo_r_mwk_ts", stringsAsFactors = FALSE) %>%
mutate (time = as.character(time)) %>%
mutate (year = as.numeric(substr(time, 1, 4)),
week = as.numeric(substr(time, 6,7)),
sex = as.factor(sex),
geo = as.factor(geo)) %>%
select (sex, geo, year, week, value=values) %>%
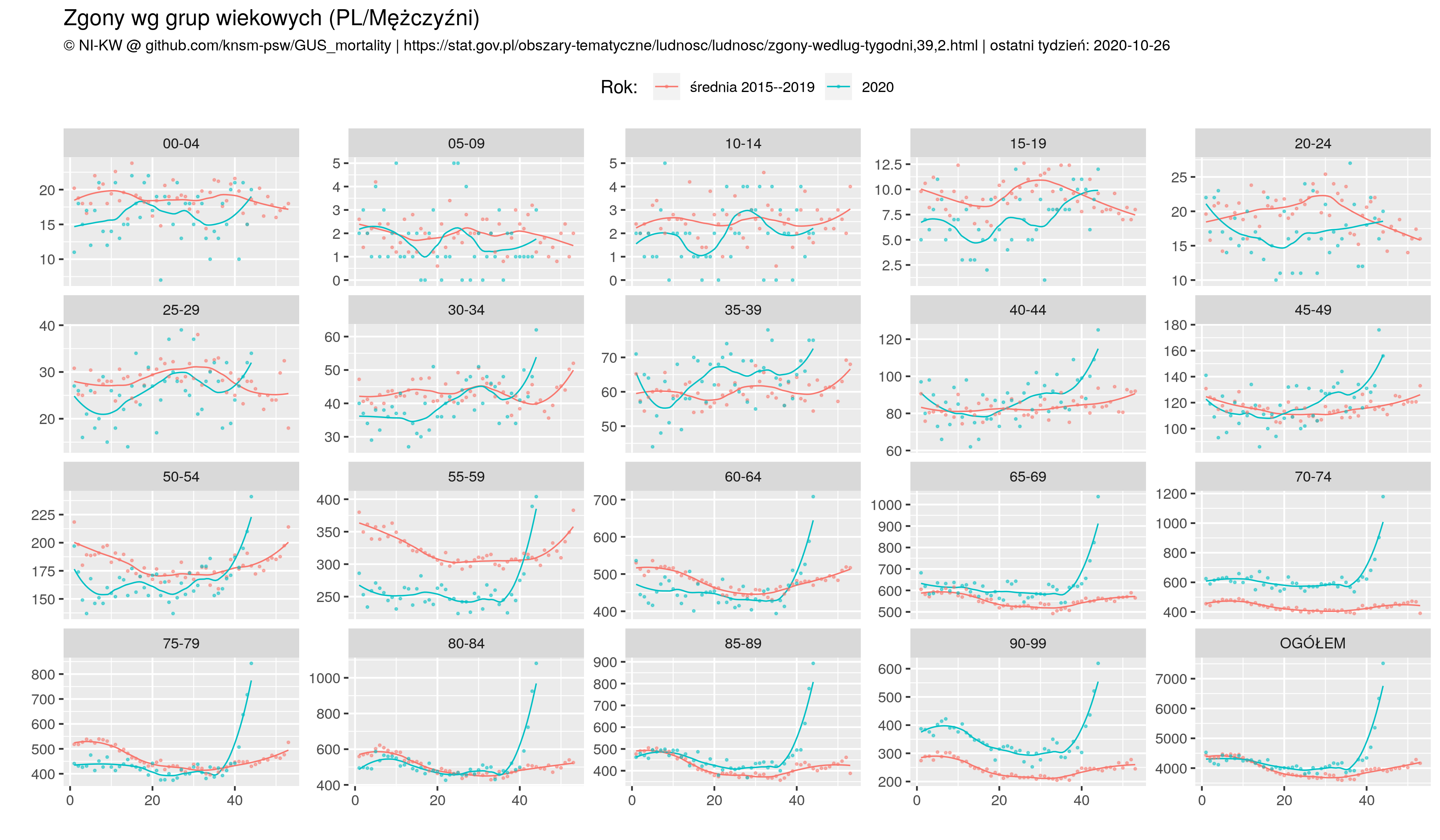
filter (sex == 'T')
Końcowy filter usuwa liczbę zgonów dla kobiet/mężczyzn osobno, bo chcemy tylko analizować ogółem czyli Total.
W pliku ecdc_countries_names_codes3166.csv są nazwy krajów (bo w bazie Eurostatu są tylko ISO-kody):
## country names
nn <- read.csv("ecdc_countries_names_codes3166.csv", sep = ';', header=T, na.string="NA" )
Teraz liczę 5-letnie średnie dla okresu przed pandemią czyli dla lat 2015--2019 włącznie:
## mean weekly deaths 2015--2019 z0 <- z %>% filter ( year >= 2015 & year < 2020) %>% group_by(geo, week) %>% summarise (d0 = mean(value, na.rm=T))
Oraz tygodniowe liczby zgonów dla lat 2020--2021
## weekly deaths 2020--2021 z1 <- z %>% filter ( year > 2019 ) %>% group_by(geo, year, week) %>% summarise ( d1 = sum(value))
Łączę z0 z z1; liczę różnice między zgonami 2020--2021 a średnimi. Najpierw usuwam wiersze z NA w kolumnach zawierających zgony/średnie (drop_na). To w szczegolności usunie wiersze z tygodni (w roku 2021), dla których jeszcze nie ma danych.
## join z0 z1 and compute differences
zz <- left_join(z0, z1, by=c("week", "geo")) %>%
drop_na(d0,d1) %>%
mutate (exp = (d1 - d0)/d0 * 100, exm = d1 - d0 )
zz <- left_join(zz, nn, by=c('geo'='id'))
Osobno liczę numer ostatniego raportowanego tygodnia w roku 2021. Pytanie o numer ostatniego w ogóle jest bez sensu, bo w 2020 będzie to ostatni tydzień. Ten fragment ciut mało robust jest bo w 2022 trzeba go będzie zmodyfikować
## if NA then the country stop reporting in 2020 zz.last.week <- zz %>% filter (year == 2021) %>% group_by (geo) %>% summarise (lw = last(week)) %>% drop_na(lw) ## najbardziej aktualny raportowany tydzień (różne kraje raportują różnie) latestweek <- max (zz.last.week$lw)
Uwaga: niektóre kraje nie raportują w 2021, więc ich nie będzie w ramce zz.last.week z uwagi na filter.
Ramka zzt zawiera sumy różnic; bezwzględne (exm) oraz względne w procentach względem poziomu średniego 2015--2019 (exp):
### total exmort zzt <- zz %>% group_by(geo) %>% summarise(country=last(country), exm = sum(exm), nm = sum(d0)) %>% mutate (exmp = exm/nm * 100)
Dodajemy informację z ramki zz.last.week; jeżeli w tej ramce nie ma kraju (bo nie raportował w 2021) to usuwamy go (drop_na(lw)). Wypierniczamy kraje raportujące więcej niż 6 tygodni po kraju (krajach), który przysłały raport najpóźniej. Np jak jakiś kraj-prymus dostarczył w 47 tygodniu to tylko kraje raportujące z tygodni 41 i później zostają a inne są usuwane (jako nieporównywalne)
zztt <- left_join(zzt, zz.last.week, by='geo') %>% drop_na(lw) %>% filter (lw >= latestweek - 6) ## ile zostało krajów (dla ciekawości): countries.left <- nrow(zztt)
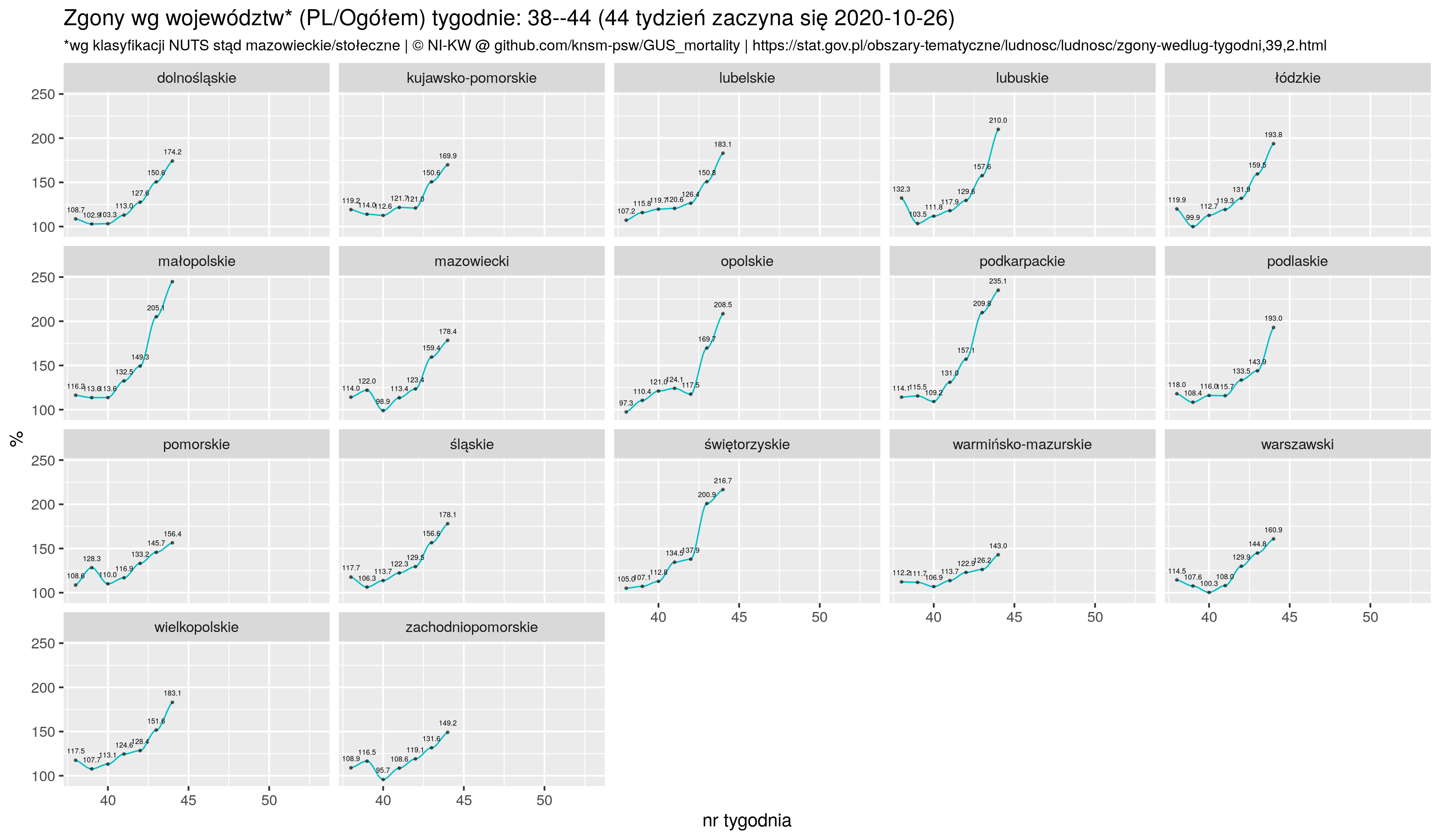
Wykres słupkowy względnej nadmiarowej umieralności (Total excess mortality by country) Trochę go komplikujemy bo słupek PL ma być wyróżniony (w tym celu tworzymy zmienną base a potem ręcznie ustawiamy legendę scale_fill_manual):
p6 <- zztt %>% mutate( base=ifelse(geo=='PL', "1", "0")) %>%
ggplot(aes(x = reorder(country, exmp ), fill=as.factor(base))) +
geom_bar(aes(y = exmp), stat="identity", alpha=.4 ) +
geom_text(aes(label=sprintf("%.1f", exmp), y= exmp ),
vjust=0.25, hjust=1.25, size=2, color='black' ) +
geom_text(aes(label=sprintf("%.0f", lw), y= 0 ),
vjust=0.25, hjust=-1.25, size=2, color='brown4' ) +
xlab(label="") +
ylab(label="") +
ggtitle("Total Excessive deaths in Europe 2020--2021",
subtitle ="Sum of (deaths_2020/2021 - average_2015--2019) / average_2015--2019 * 100%") +
theme_nikw() +
coord_flip() +
scale_fill_manual( values = c( "1"="red", "0"="steelblue" ), guide = FALSE ) +
labs(caption=x.note)
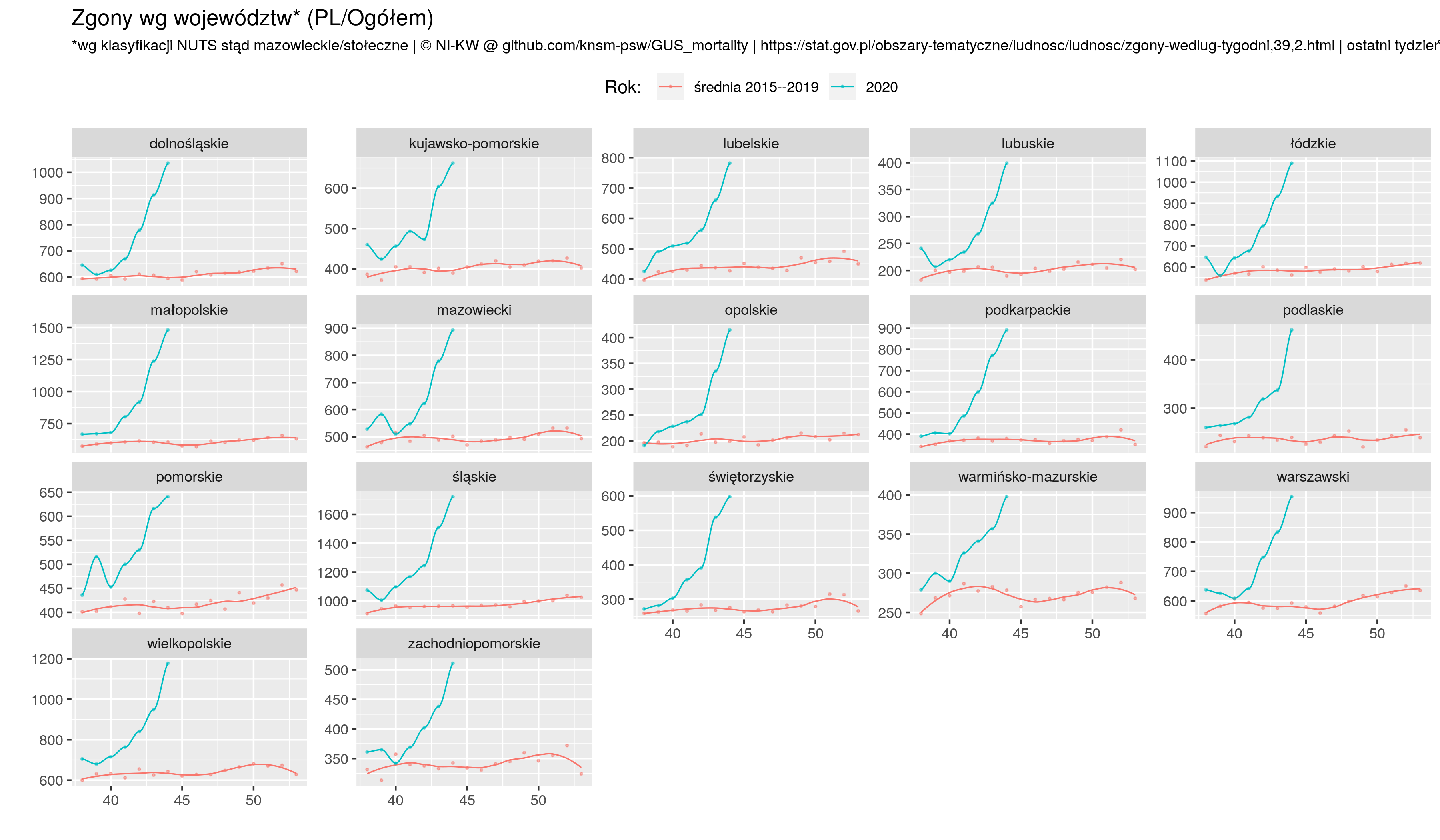
Wykres dynamiki. Ponieważ krajów jest dużo to usuwamy (pierwszy filter) `nieciekawe' (małe lub te które mają jakiś feler, np dane niepełne);
p7 <- zz %>% filter (! geo %in% c('AL', 'AM', 'IE', 'IS', 'UK', 'CY', 'GE', 'LI', 'ME')) %>%
mutate(date= as.Date(sprintf("%i-%i-1", year, week), "%Y-%U-%u") ) %>%
##ggplot(aes(x = date, y =exp, group=geo, color=geo )) +
ggplot(aes(x = date, y =exp)) +
facet_wrap( ~country, scales = "fixed", ncol = 4, shrink = F) +
geom_point(size=.4) +
geom_smooth(method="loess", size=1, se = F, color="red", span =.25) +
geom_hline(yintercept = 50, color="firebrick", alpha=.2, size=1) +
scale_y_continuous(breaks=seq(-100, 200, by=50)) +
coord_cartesian(ylim = c(-100, 200)) +
ggtitle("Excessive deaths in Europe 2020--2021",
subtitle ="(deaths_2020/2021 - average_2015--2019) / average_2015--2019 * 100%") +
theme_nikw() +
xlab(label="%") +
labs(caption=note)
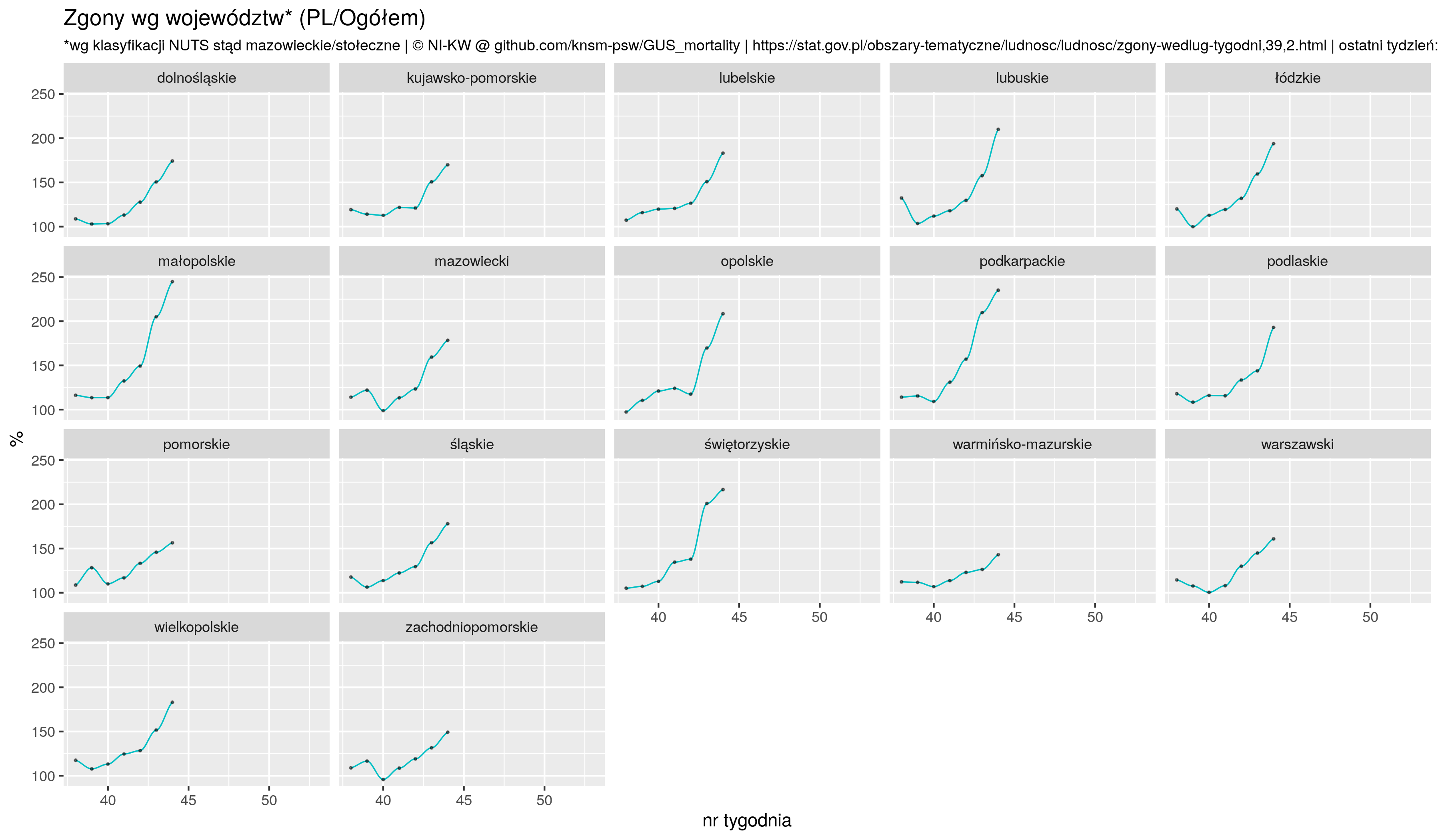
Teraz wszystko na jednym ale ponieważ krajów jest za dużo (w sensie za mało byłoby kolorów żeby wykres był czytelny), to dzielimy je na dwie grupy: Polska i reszta. Każda grupa innym kolorem:
p8 <- zz %>% filter (! geo %in% c('AL', 'AM', 'IE', 'IS', 'UK', 'CY', 'GE', 'LI', 'ME')) %>%
mutate( base=ifelse(geo=='PL', "1", "0")) %>%
mutate(date= as.Date(sprintf("%i-%i-1", year, week), "%Y-%U-%u") ) %>%
ggplot(aes(x = date, y =exp, color=as.factor(base ))) +
##ggplot(aes(x = date, y =exp)) +
geom_point(size=.4) +
geom_smooth(aes(x = date, y =exp, group=geo), method="loess", size=.3, se = F, span =.25) +
geom_hline(yintercept = 50, color="firebrick", alpha=.2, size=1) +
coord_cartesian(ylim = c(-100, 200)) +
scale_color_manual( values = c( "1"="red", "0"="steelblue" ), guide = FALSE ) +
theme_nikw() +
ylab(label="%") +
ggtitle("Excessive deaths in Europe 2020--2021 and Poland (red)",
subtitle ="(deaths_2020/2021 - average_2015--2019) / average_2015--2019 * 100%") +
scale_y_continuous(breaks=seq(-100, 200, by=50)) +
labs(caption=note)
Wszystko działa (i koliduje jak mówił Bolec), bo działało na PC, ale był problem na raspberry, na którym to ostatecznie ma być uruchamiane z automatu co dwa tygodnie. Bo tam Debian starszy (Buster) i na arma. Zapodanie:
install.package("eurostat")
Skutkowało pobraniem wielu pakietów i błędem przy kompilacji czegoś co się nazywało s2. Kombinowałem na różne sposoby jak to skompilować bo stosownego pakietu w Debianie nie było. Ni-chu-chu.
W przypływie olśnienia obejrzałem zależności tego eurostatu, wśród których żadnego s2 nie było. Był za to sf, które z kolei rzekomo zależał od s2. Żeby było śmieszniej sf dało się zainstalować (mimo że s2 nie było -- stąd rzekomo):
apt install r-cran-sf/oldstable
Problem się rozwiązał...
Skrypt będzie się uruchamiał co dwa tygodnie. Generował rysunki i wysyłał je na twittera
Całość jest na githubie i to w dodatku jako plik Rmd, ale nie na moim koncie tylko na koncie Koła Naukowego SM w PSW w Kwidzynie, którego póki co jestem opiekunem i jedynym członkiem w jednym (por. github.com/knsm-psw/ES-mortality)