Na stronie http://policja.pl/pol/form/1,Informacja-dzienna.html udostępniane są dzienne dane dotyczące liczby interwencji, zatrzymanych na gorącym uczynku, zatrzymanych poszukiwanych, pijanych kierujących, wypadków, zabitych w wypadkach, rannych w wypadkach.
Ściągam wszystkie dane:
#!/bin/bash
rm pp.html
for ((i=0; i <= 274; i++)) do
if [ ! -f ${i}.html ] ; then
curl -o ${i}.html "http://policja.pl/pol/form/1,Informacja-dzienna.html?page=${i}" ;
grep 'data-label' ${i}.html >> pp.html
sleep 6
else
grep 'data-label' ${i}.html >> pp.html
echo done
fi
done
zamieniam prostymi skryptami na plik CSV, który ma następującą strukturę:
data;interwencje;zng;zp;znk;wypadki;zabici;ranni 2008-12-01;NA;873;344;447;135;1;1
okazuje się że liczba interwencji jest podawana od roku 2018, wcześniej nie była. Nic to wstawiamy NA.
Na przyszłość dane będą aktualizowane w ten sposób, że codziennie (przez odpowiedni wpis w pliku crontab) będzie pobierany plik http://policja.pl/pol/form/1,Informacja-dzienna.html:
#!/usr/bin/perl
use LWP::Simple;
$PP="http://policja.pl/pol/form/1,Informacja-dzienna.html";
$PPBase="pp.csv";
$content = get("$PP");
$content =~ s/\r//g; # dla pewności usuń
@content = split (/\n/, $content);
foreach (@content) { chomp();
unless ($_ =~ m/data-label=/ ) { next }
if ($_ =~ m/Data statystyki/ ) { $d = clean($_); }
elsif ($_ =~ m/Interwencje/ ) { $i = clean($_); }
elsif ($_ =~ m/Zatrzymani na g/ ) { $zg = clean($_); }
elsif ($_ =~ m/Zatrzymani p/ ) { $zp = clean($_); }
elsif ($_ =~ m/Zatrzymani n/ ) { $zn = clean($_); }
elsif ($_ =~ m/Wypadki d/ ) { $w = clean($_); }
elsif ($_ =~ m/Zabici/ ) { $z = clean($_); }
elsif ($_ =~ m/Ranni/ ) { $r = clean($_);
$l = "$d;$i;$zg;$zp;$zn;$w;$z;$r";
$last_line = "$l"; $last_date = "$d";
## pierwszy wpis powinien zawierać dane dotyczące kolejnego dnia
## więc po pobraniu pierwszego można zakończyć
last;
}
}
### read the database
open (PP, "<$PPBase") || die "cannot open $PPBase/r!\n" ;
while (<PP>) { chomp(); $line = $_; @tmp = split /;/, $line; }
close(PP);
### append the database (if new record)
open (PP, ">>$PPBase") || die "cannot open $PPBase/w!\n" ;
unless ("$tmp[0]" eq "$last_date") { print PP "$last_line\n" }
else {print STDERR "nic nowego nie widzę!\n"}
close(PP);
sub clean {
my $s = shift;
$s =~ s/<[^<>]*>//g;
$s =~ s/[ \t]//g;
return ($s);
}
Zaktualizowana baza jest wysyłana na githuba. Tutaj jest: https://github.com/hrpunio/Nafisa/tree/master/PP
Agregacja do danych tygodniowych okazała się nietrywialna
Niektóra lata zaczynają się od tygodnia numer 0 a inne od 1. Okazuje się, że tak ma być (https://en.wikipedia.org/wiki/ISO_week_date#First_week):
If 1 January is on a Monday, Tuesday, Wednesday or Thursday, it is in W01. If it is on a Friday, it is part of W53 of the previous year. If it is on a Saturday, it is part of the last week of the previous year which is numbered W52 in a common year and W53 in a leap year. If it is on a Sunday, it is part of W52 of the previous year.
Nie bawię się w subtelności tylko tygodnie o numerze zero dodaję do tygodnia z poprzedniego roku.
Sprawdzam czy jest OK i się okazuje że niektóre tygodnie mają 8 dni. W plikach html są błędy:
Błędne daty 2019-10-30 winno być 2019-09-30; podobnie błędne 2019-03-28 (winno być 2019-02-28), 2018-11-01 (2018-12-01), 2018-12-01 (2017-12-01), 2016-04-30 (2016-03-30), 2009-08-31 (2009-07-31). Powtórzone daty: 2016-03-10, 2010-07-25, 2010-01-10 (zdublowane/różne/arbitralnie usuwamy drugi) Ponadto brak danych z następujących dni: 2015-12-04--2015-12-07, 2015-04-17--2015-04-20, 2014-10-02--2014-10-05, 2014-01-23 i jeszcze paru innych (nie chcialo mi się poprawiać starych.)
Teraz jest OK, plik ppw.csv ma nast strukturę:
rok;nrt;interwencje;in;zng;zngn;zp;zpn;znk;znkn;wypadki;wn;zabici;zn;ranni;rn;d1;d7 coś co się kończy na `n' to liczba tego co jest w kolumnie poprzedniej, np zn to liczba dni tygodnia dla kolumny zabici. Generalnie kolumny kończące się na `n' zawierają 7 :-) Kolumna d1 to pierwszy dzień tygodnia a kolumna d7 ostatni.
maxY <- max (d$zabici)
pz <- ggplot(d, aes(x= as.factor(nrt), y=zabici )) +
geom_bar(fill="steelblue", stat="identity") +
xlab(label="") +
ggtitle("Wypadki/zabici (Polska/2020)", subtitle="policja.pl/pol/form/1,Informacja-dzienna.html")
W sumie agregacja jest niepotrzebna, bo można ją zrobić na poziomie R używając funkcji stat_summary:
pw <- ggplot(d, aes(x= week, y=wypadki)) +
stat_summary(fun.y = sum, geom="bar", fill="steelblue") +
scale_x_date( labels = date_format("%y/%m"), breaks = "2 months") +
xlab(label="") +
#theme(plot.subtitle=element_text(size=8, hjust=0, color="black")) +
ggtitle("Wypadki (Polska/2018--2020)", subtitle="policja.pl/pol/form/1,Informacja-dzienna.html")
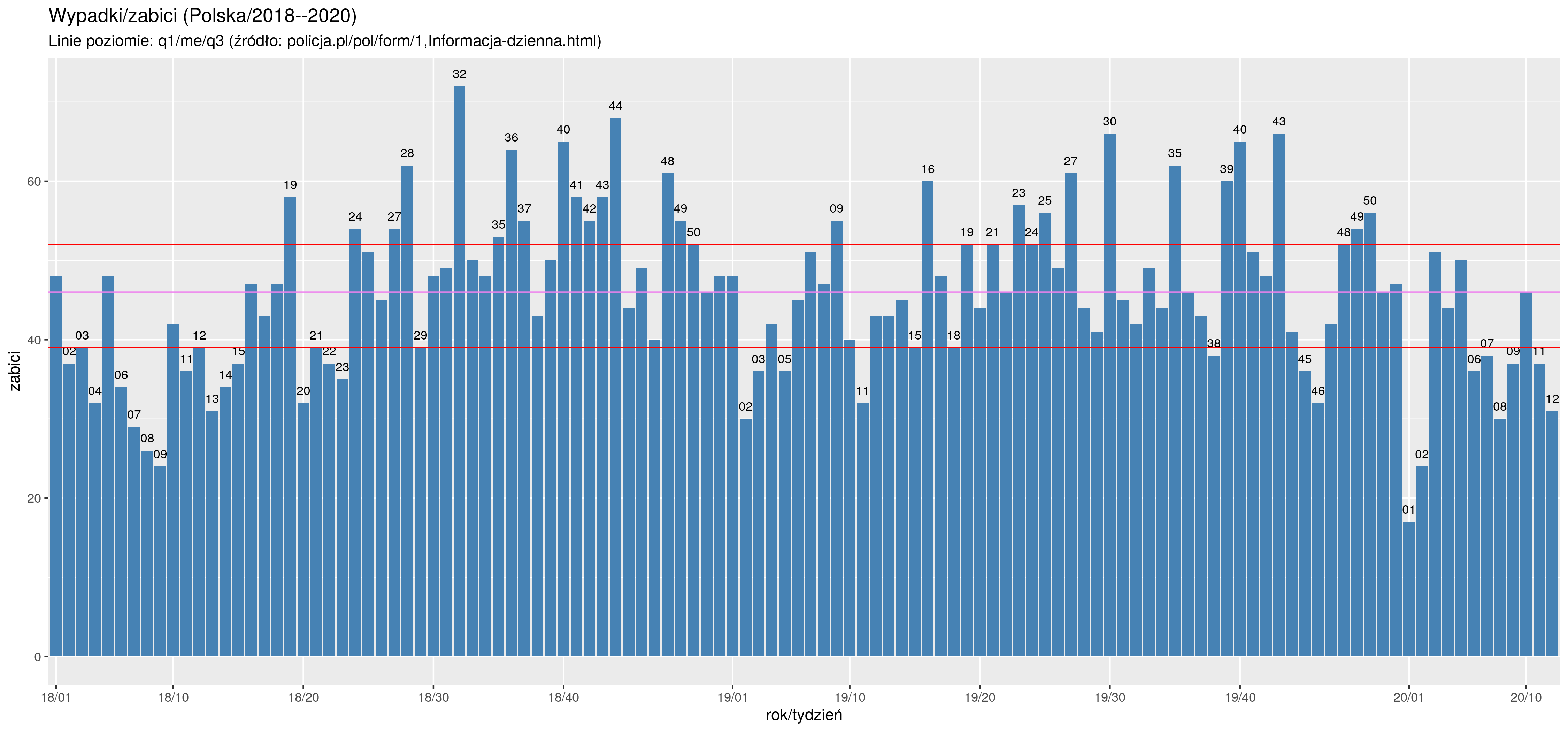
albo najpierw agregując dane a potem wykreślając wykres szeregu zagregowanego. Drugi sposób pozwala na przykład na dodanie linii oznaczających poziomy zagregowanego zjawiska/etykiety słupków w sposób `inteligentny'. Dodajemy etykiety (z numerem tygodnia) tylko dla słupków poniżej/powyżej Q1/Q3:
## agregowanie do danych tygodniowych kolumn ranni, zabici, wypadki
dw <- d %>% group_by ( YrWeek) %>% summarise_at ( vars(ranni,zabici,wypadki), sum )
## Obliczanie mediany i kwartyli
median.zw <- median(dw$zabici)
q1.zw <- quantile(dw$zabici, 1/4)
q3.zw <- quantile(dw$zabici, 3/4)
## YrWeekZZ to numer tygodnia, dla tygodni w których liczba wypadków jest typowa
## numer jest pusty (żeby nie był drukowany); taki trick może jest lepszy
dw$YrWeekZZ <- substr(dw$YrWeek,4,5)
dw$YrWeekZZ[ (dw$zabici > q1.zw) & (dw$zabici < q3.zw) ] <- ""
pz.2 <- ggplot(dw, aes(x= YrWeek, y=zabici)) +
geom_bar(stat="identity", fill = "steelblue") +
geom_text(data=dw, aes(label=sprintf("%s", YrWeekZZ), x=YrWeek, y= zabici), vjust=-0.9, size=3 ) +
geom_hline(yintercept=median.zw, linetype="solid", color = "violet", size=.4) +
geom_hline(yintercept=q3.zw, linetype="solid", color = "red", size=.4) +
geom_hline(yintercept=q1.zw, linetype="solid", color = "red", size=.4) +
xlab(label="rok/tydzień") +
ylab(label="zabici") +
scale_x_discrete(breaks=c("18/01", "18/10", "18/20", "18/30", "18/40",
"19/01", "19/10", "19/20", "19/30", "19/40", "20/01", "20/10")) +
# labels = c("/18/01", "18/10", "18/20", "")) ## tutaj niepotrzebne
ggtitle("Wypadki/zabici (Polska/2018--2020)",
subtitle="Linie poziomie: q1/me/q3 (źródło: policja.pl/pol/form/1,Informacja-dzienna.html)")
Brak komentarzy:
Prześlij komentarz