Punktem wyjścia są dane ze strony ZKDP (w formacie Excel.) Ponieważ pobieram je od pewnego czasu mam tego więcej niż jest na ww. stronie bo od stycznia 2015 do lipca 2017, czyli 31 plików. Ręczna konwersja byłaby zatem ciut za bardzo czasochłonna.
for i in *.xls do
oocalc --headless --convert-to csv $i ;
# albo ssconvert -v $i `basename $i .xls`.csv ;
done
# Wyciągam dane dotyczące sprzedaży ogółem dla SE
grep 'Super Ex' *.csv | awk -F ',' '{print $7} ' > se_sales.csv
# Analogicznie dla innych tytułów
Uwaga: program ssconvert znajduje się w pakiecie gnumeric, oocalc to oczywiście składni Libre/OpenOffice.
Wielkości sprzedaży dla trzech najpoczytniejszych tytułów pokazują wykresy liniowe (pierwszy w tys egz. a drugi w procentach nakładu ze stycznia 2015 r.)
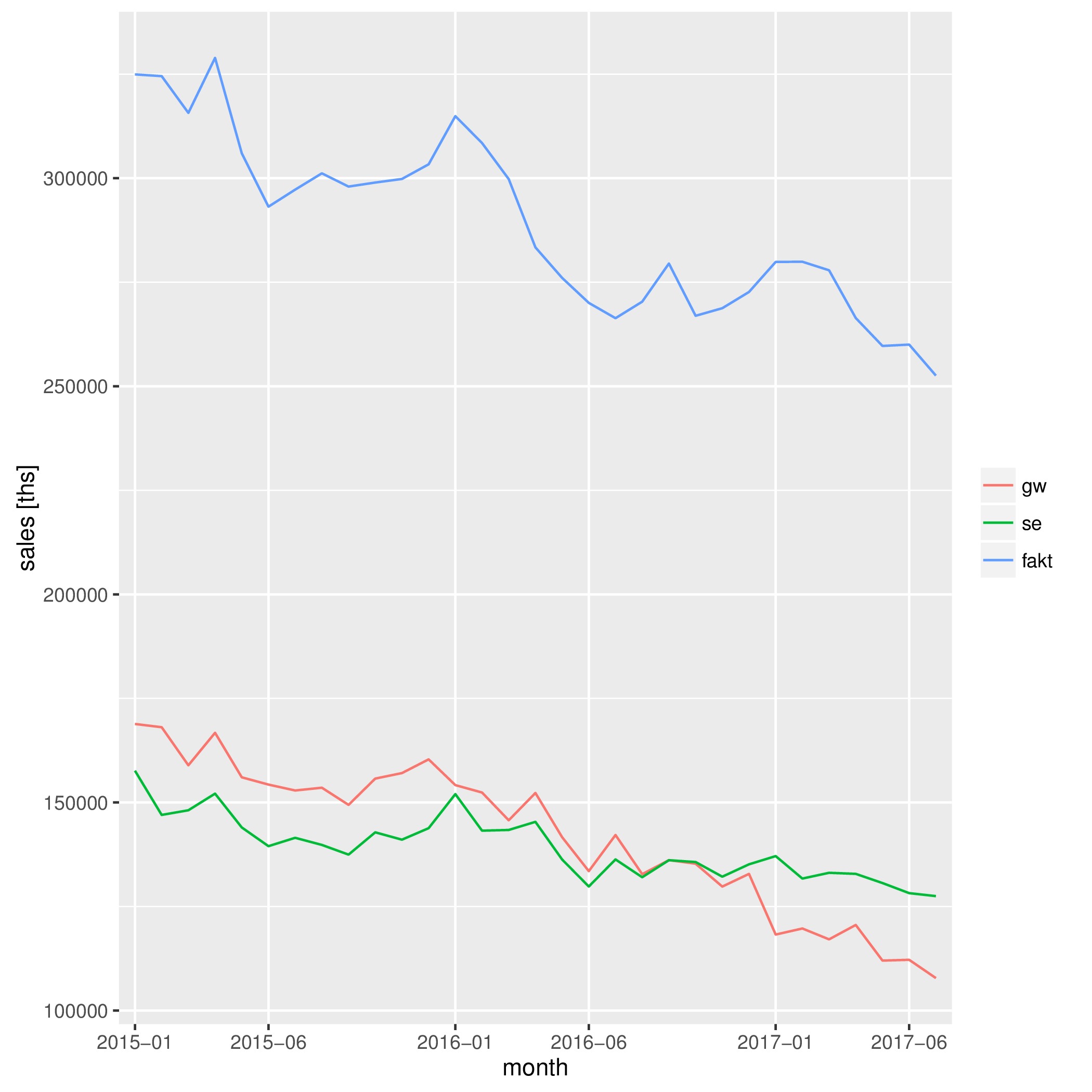
Sprzedaż w tys egz.
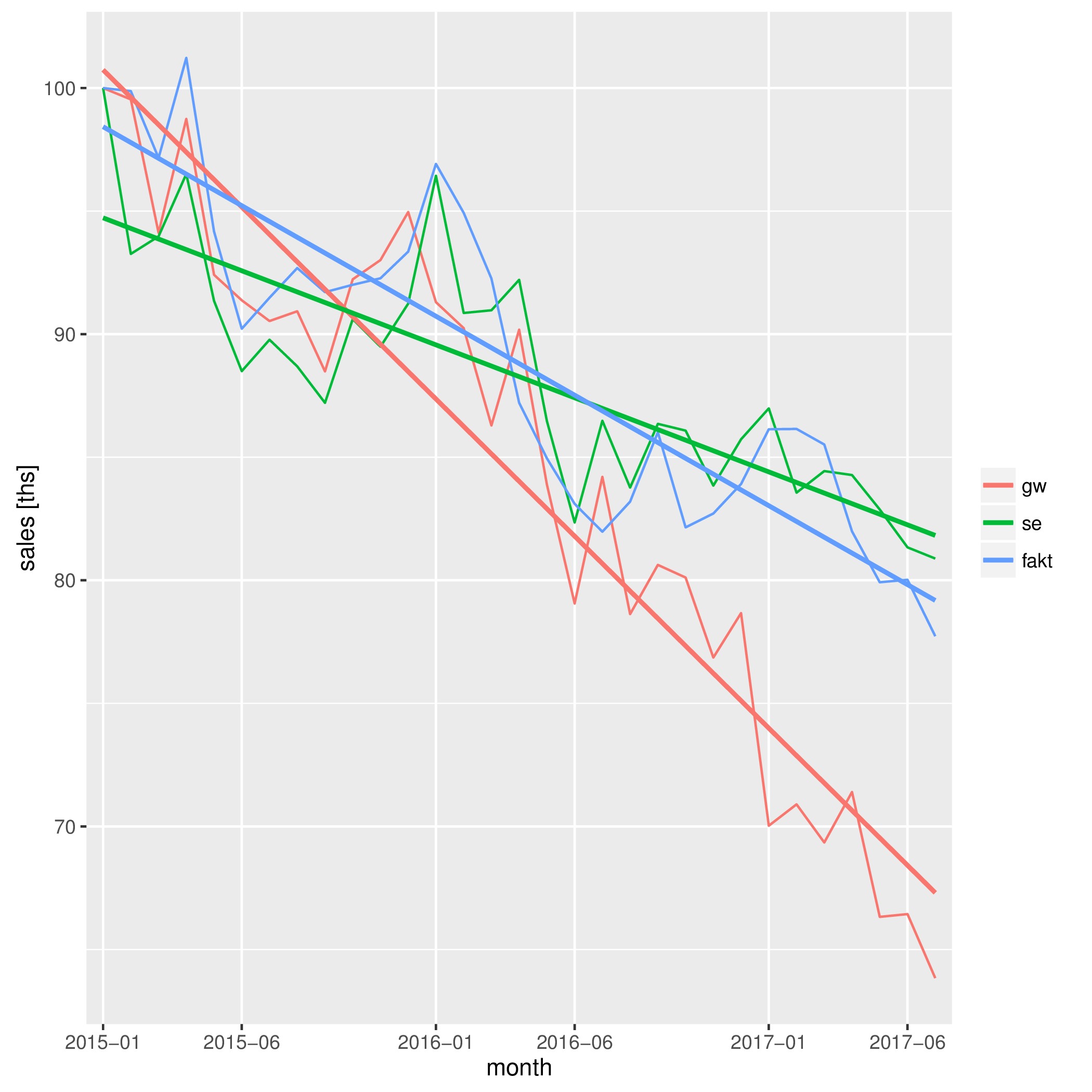
Sprzedaż w % poziomu ze stycznia 2015
library(ggplot2)
library(reshape2)
df <- read.csv("newspaper_sales_2015-17.csv", sep = ';',
header=T, na.string="NA");
meltdf <- melt(df,id="month")
ggplot(meltdf,aes(x=month, y=value, colour=variable, group=variable)) +
geom_line() +
ylab(label="sales [ths]") +
theme(legend.title=element_blank()) +
scale_x_discrete (breaks=c("2015-01-01", "2015-06-01",
"2016-01-01", "2016-06-01", "2017-01-01", "2017-06-01"),
labels=c("2015-01", "2015-06", "2016-01", "2016-06",
"2017-01", "2017-06") )
# https://stackoverflow.com/questions/10085806/extracting-specific-columns-from-a-data-frame
obs <- df[,c("month")]
normalize <- function(x) { return (x /x[1] * 100 ) }
dfN <- as.data.frame(lapply(df[-1], normalize))
# https://stackoverflow.com/questions/10150579/adding-a-column-to-a-data-frame
dfN["month"] <- obs
str(dfN)
meltdf <- melt(dfN,id="month")
# https://www.r-bloggers.com/what-is-a-linear-trend-by-the-way/
pN <- ggplot(meltdf,
aes(x=month, y=value, colour=variable, group=variable)) + geom_line() +
ylab(label="sales [ths]") +
theme(legend.title=element_blank()) +
stat_smooth(method = "lm", se=F) +
scale_x_discrete (breaks=c("2015-01-01", "2015-06-01",
"2016-01-01", "2016-06-01", "2017-01-01", "2017-06-01"),
labels=c("2015-01", "2015-06", "2016-01",
"2016-06", "2017-01", "2017-06") )
pN
Spadek widoczny na wykresach można określić liczbowo na przykład szacując linię trendu:
# Trend liniowy # http://t-redactyl.io/blog/2016/05/creating-plots-in-r-using-ggplot2-part-11-linear-regression-plots.html # http://r-statistics.co/Time-Series-Analysis-With-R.html seq = c (1:nrow(dfN)) dfN["trend"] <- seq trendL.gw <- lm(data=dfN, gw ~ trend ) trendL.fakt <- lm(data=dfN, fakt ~ trend ) trendL.se <- lm(data=dfN, se ~ trend ) trendL.gw trendL.fakt trendL.se
Współczynniki trendu dla GW, Faktu i SE są odpowiednio równe -1.114 -0.6415 -0.4301, co należy interpretować następująco: przeciętnie z miesiąca na miesiąc nakład spada o 1,11%, 0,64% oraz 0,43% nakładu ze stycznia 2015 r., odpowiednio dla GW, Faktu i SuperExpresu.
Dane i wyniki są tutaj
Ciekawy wpis
OdpowiedzUsuń