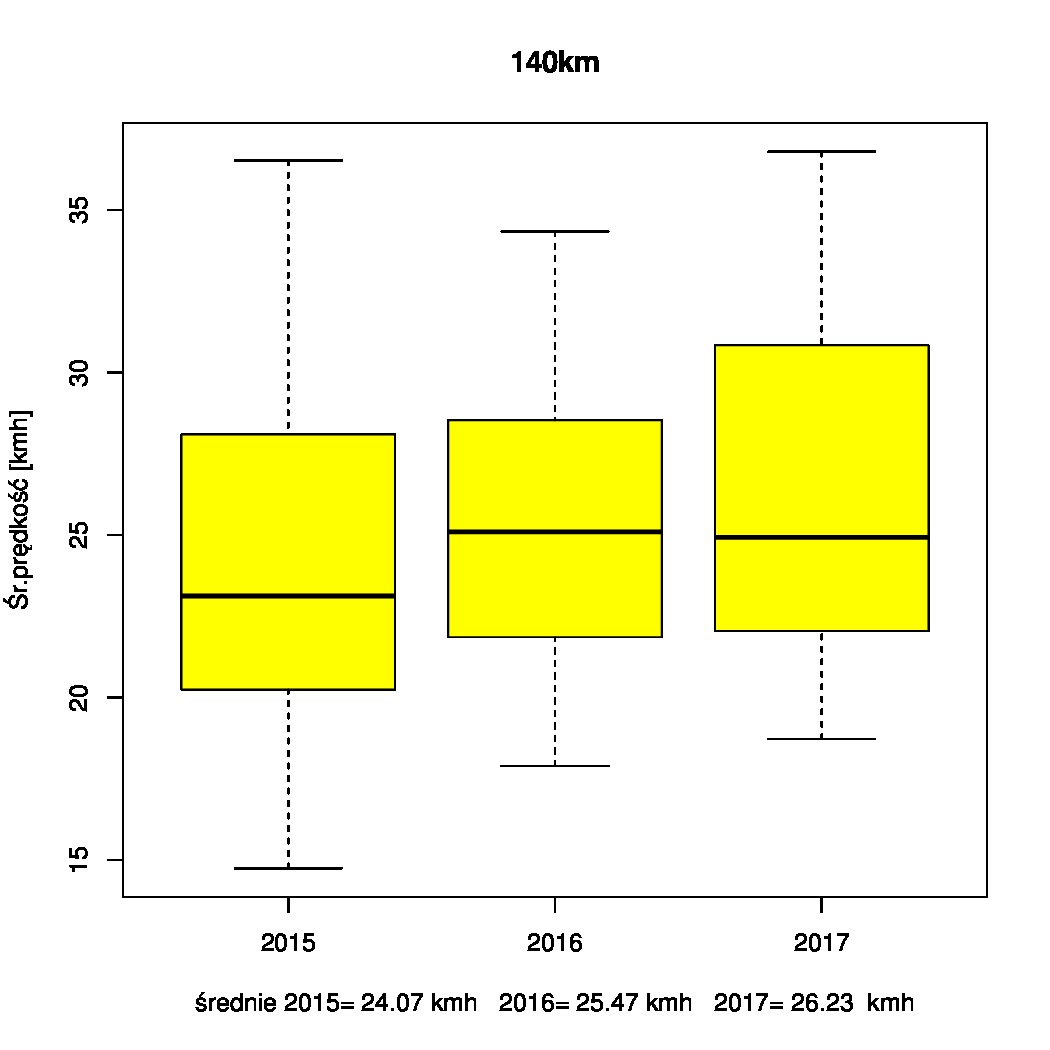
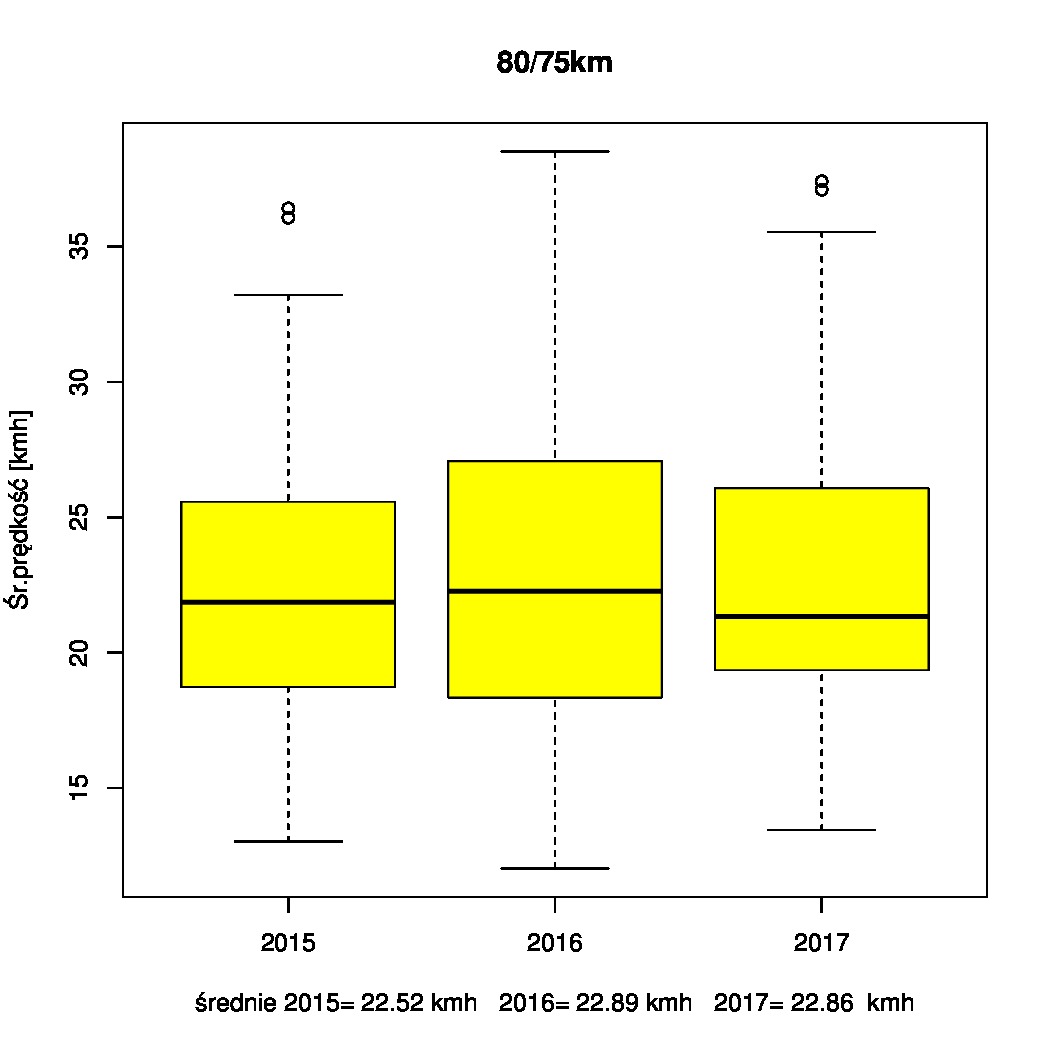
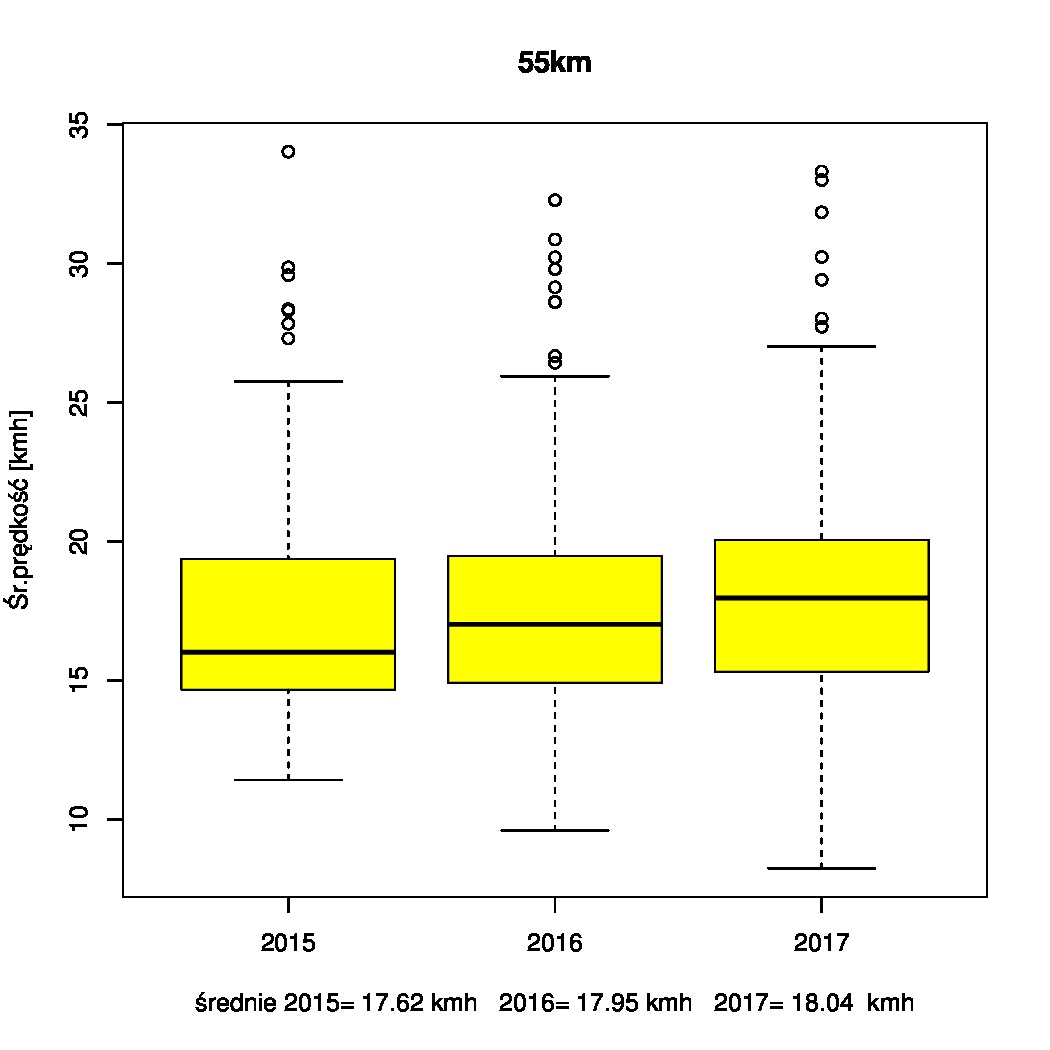
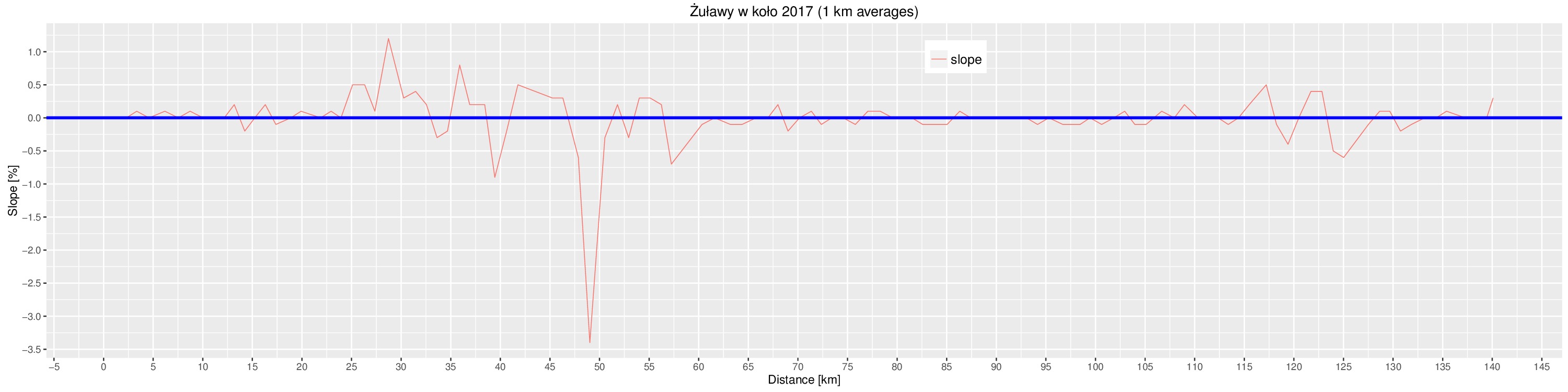
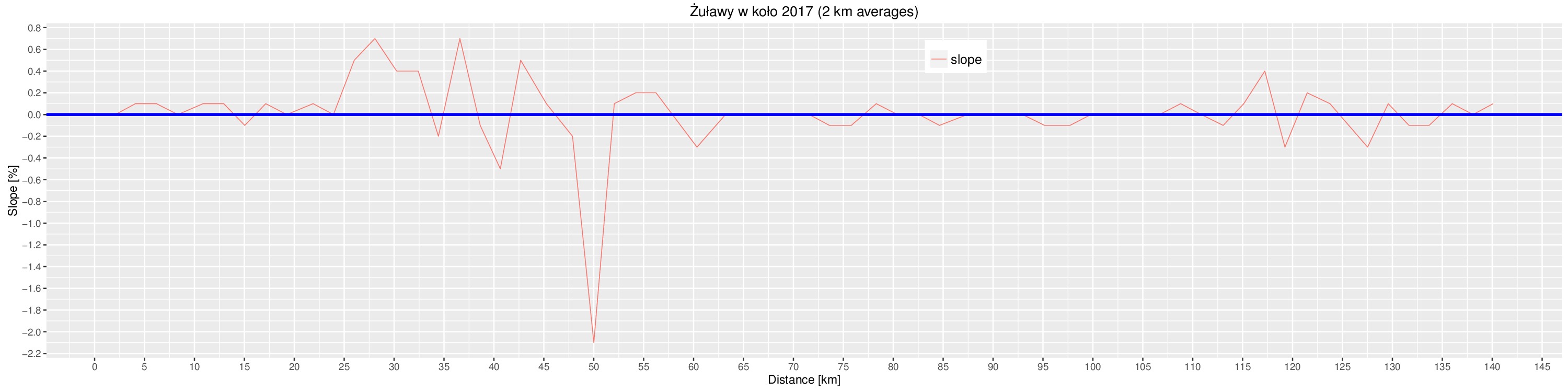
Contour+ ma GPSa i rejestruje współrzędne geograficzne, tyle że do niedawna nie bardzo wiedziałem jak (słusznie podejrzewałem że w postaci napisów aka subtitles). Wreszcie rozkminiłem jak to działa, a zmobilizowały mnie filmy zarejestrowane podczas imprezy Żuławy wKoło 2017.
Najpierw trzeba ustalić co jest w środku pliku .mov:
ffmpeg -i FILE0037.MOV
## ## ##
Stream #0:2(eng): Subtitle: mov_text (text / 0x74786574), 1 kb/s (default)
Teraz można wyciągnąć napis znajdujący się w strumieniu (stream) 2:
ffmpeg -i FILE0037.MOV -vn -an -codec:s:0.2 srt file0037_2.srt
W pliku file0037_2.srt jest coś takiego:
692
00:11:31,000 --> 00:11:32,000
$GPRMC,061159.00,V,,,,,,,240917,,,N*7E
$GPGGA,061159.00,,,,,0,04,2.18,,,,,,*53
693
00:11:32,000 --> 00:11:33,000
$GPRMC,061200.00,A,5412.74161,N,01906.66188,E,18.465,202.51,240917,,,A*50
$GPGGA,061200.00,5412.74161,N,01906.66188,E,1,04,2.18,6.5,M,32.4,M,,*58
Czyli jest to zwykły plik napisów w formacie SRT, tj. sekwencja rekordów składających się z wierszy tekstu. Pierwszy wiersz zawiera numeru napisu (692 na przykład). Drugi wiersz określa czas wyświetlania napisu (początek --> koniec). Kolejne wiersze to tekst napisu. W przykładzie powyżej napis 692 jeszcze nie złapał fiksa, a napis 693 już tak. Współrzędne są zarejestrowane w postaci par zdań (sentences) GPRMC/GPGGA w standardzie NMEA. Do konwersji czegoś takiego na format GPX na przykład można zastosować gpsbabela
gpsbabel -i nmea -f file.srt -o GPX -F file.gpx
Ale wtedy gubi się informację z pierwszych dwóch wierszy rekordu, a jest ona niezbędna do synchronizacji obrazu ze współrzędnymi w programach nie potrafiących wykorzystać napisów wbudowanych. Chciał-nie-chciał musiałem rozpoznać NMEA i dokonać konwersji po swojemu:
$GPRMC,time,###,dd.mm,N/S,dd.mm,E/W,speed,###,date,###,###,###
$GPGGA,time,dd.mm,N/S,dd.mm,E/W,q,s,###,ele,M,###,M,###,###
Gdzie: speed -- prędkość w węzłach czyli milach/godzinę; date -- data w formacie ddmmyy; time -- czas w formacie hhmmss.ss; dd.mm -- współrzędne geograficzne w formacie stopnieminuty.minuty tj 5412.74161 oznacza 54 stopnie 12.74161 minut a 01906.66188 oznacza 19 stopni 6.66188 minut (uwaga: szerokość/długość ma różną liczbę cyfr przed kropką dziesiętną); N/S/E/W -- kierunki geograficzne (north, south itp); q -- jakość sygnału (niezerowa wartość jest OK); s -- liczba satelitów; ele -- wysokość npm. (w metrach na szczęście w przypadku Contoura+). Zawartość pól oznaczona jako ### nas nie interesuje. Symbol M oznacza jednostkę miary (metry), z czego by wynikało, że różne odbiorniki GPS mogą zapisywać informacje o wysokości z wykorzystaniem innych jednostek miary.
Teraz banalny skrypt Perlowy zamienia SRT na format GPX dodając informacje o numerze napisu i czasie wyświetlania w postaci stosownego elementu cmt
<trkpt lat="54.212360" lon="19.111031">
<ele>6.500000</ele>
<time>2017-09-24T06:12:00Z</time>
<speed>9.499208</speed>
<cmt>693 00:11:32,000 --> 00:11:33,000</cmt>
</trkpt>
BTW nie ma elementu speed w specyfikacji schematu GPX, ale na przykład gpsbabel taki element wstawia i jakoś to działa. Sprawa wymaga zbadania.
Uwaga: Garmin Virb Edit nie czyta dokumentów GPX w wersji 1.0 -- musi
być wersja 1.1. W praktyce oznacza to, że element gpx
powinien posiadać atrybuty version oraz
xmlns o następujących wartościach
<gpx version="1.1" xmlns="http://www.topografix.com/GPX/1/1">
Skrypt pn. cc2gpx.pl do konwersji SRT→GPX jest tutaj.