Na stronie https://wybory2018.pkw.gov.pl/pl/geografia#general_committee_stat jest informacja, że w wyborach na radnych sejmików wojewódzkich bierze udział/zostało zarejestrowanych 7076 kandydatów. Zaczynając od tej strony można się doklikać do stron dla każdego województwa oraz okręgu. Są to odpowiednio strony tworzone według schematu:
https://wybory2018.pkw.gov.pl/pl/geografia/220000#geo_committee_stat https://wybory2018.pkw.gov.pl/pl/geografia/220000/voiv_council/1
Strona okręgu zawiera listę kandydatów a jej HTML jest tak nieskomplikowany, że zamiana na na przykład plik CSV jest banalnie prosta.
Po ściągnięciu 85 ,,stron okręgowych'' i ich zamianie na CSV, faktycznie otrzymałem plik składający się z 7076 wierszy, z których każdy jest postaci:
woj;okr;komitet;nr;kandydat;wiek;skad;oswidczenie;uwagi 02;o1;SLD-LR;1;SIKORA Arkadiusz;45;Oleśnica;;
Dalszą analizę przeprowadziłem wykorzystując R:
k <- read.csv("kandydaci_ws_2018_3.csv", sep = ';', header=T, na.string="NA", dec=",");
with (k, table(komitet))
| Komitet | liczba kandydatów | liczba okręgów |
| BS | 447 | 62 |
| K15 | 675 | 84 |
| KW INICJATYWA OBYWATELSKA POWIATU TARNOGÓRSKIEGO | 31 | 4 |
| KW STOWARZYSZENIA LEX NATURALIS | 12 | 2 |
| KW STRONNICTWA PRACY | 6 | 1 |
| KW ŚLĄSKIEJ PARTII REGIONALNEJ | 85 | 12 |
| KW ŚLONZOKI RAZEM | 40 | 5 |
| KW WSPÓLNA MAŁOPOLSKA 51 KW WYBORCÓW AKCJA NARODOWA | 27 | 5 |
| KW WYBORCÓW ISKRA | 38 | 6 |
| KW WYBORCÓW JEDNOŚĆ NARODU -- WSPÓLNOTA | 118 | 18 |
| KW WYBORCÓW AGNIESZKI JĘDRZEJEWSKIEJ | 5 | 1 |
| KW WYBORCÓW MNIEJSZOŚĆ NIEMIECKA | 31 | 4 |
| KW WYBORCÓW POLSKIE RODZINY RAZEM | 28 | 4 |
| KW WYBORCÓW PROJEKT ŚWIĘTOKRZYSKIE BOGDANA WENTY | 30 | 4 |
| KW WYBORCÓW SPOZA SITWY | 23 | 4 |
| KW WYBORCÓW Z DUTKIEWICZEM DLA DOLNEGO ŚLĄSKA | 45 | 5 |
| KW ZJEDNOCZENIE CHRZEŚCIJAŃSKICH RODZIN | 40 | 7 |
| KW ZWIĄZKU SŁOWIAŃSKIEGO | 17 | 3 |
| PiS | 722 | 85 |
| PO-N | 722 | 85 |
| PSL | 722 | 85 |
| RAZEM | 549 | 85 |
| RN | 528 | 79 |
| SLD-LR | 713 | 85 |
| WiS | 448 | 63 |
| WwS | 574 | 77 |
| ZIELONI | 349 | 57 |
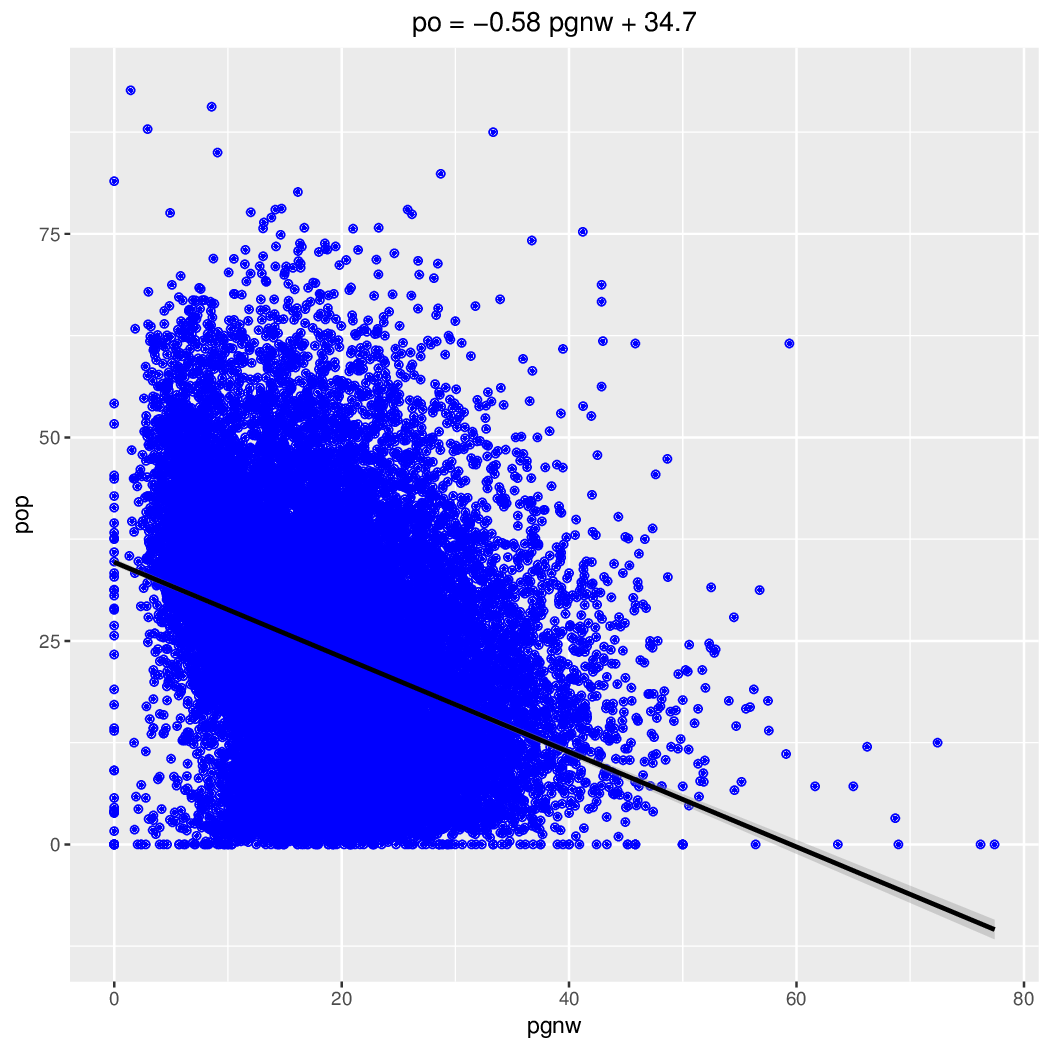
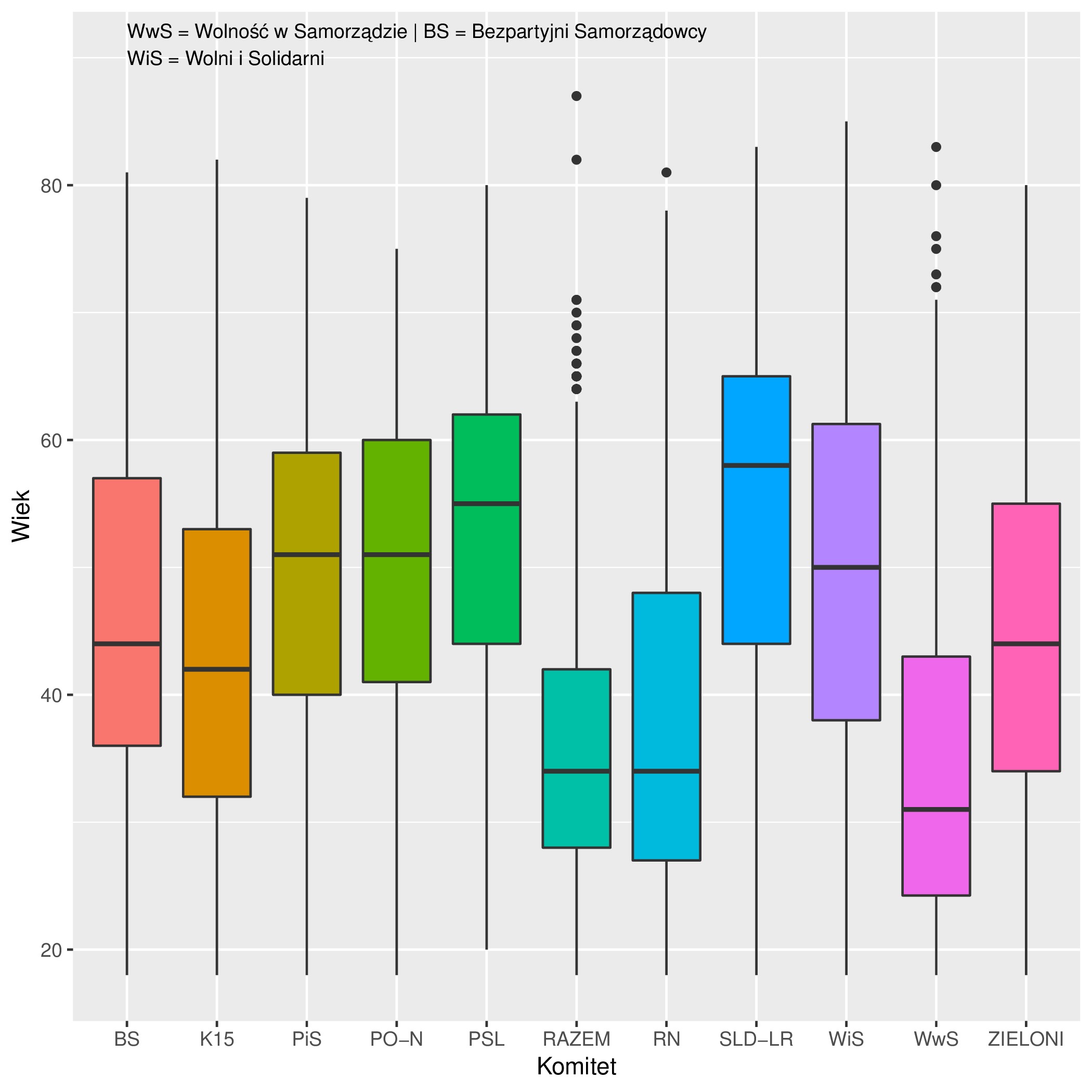
Dalszą analizą objęto 10 komitetów, które zarejestrowały kandydatów w ponad połowie okręgów wyboczych (WsS to Wolność w Samorządzie; WiS to Wolni i Solidarni a BS oznacza Komitet pn Bezpartyjni Samorządowcy):
aggregate (k$wiek, list(Numer = k$komitet), fivenum)
wB <- c(18,20,25,30,35,40,45,50,55,60,65,70,75,80,95);
summary_label <- paste (sep='', "Średnia = ", sprintf("%.1f", sumS[["Mean"]]),
"\nMediana = ", sumS[["Median"]],
"\nQ1 = ", sumS[["1st Qu."]], "\nQ3 = ", sumS[["3rd Qu."]] )
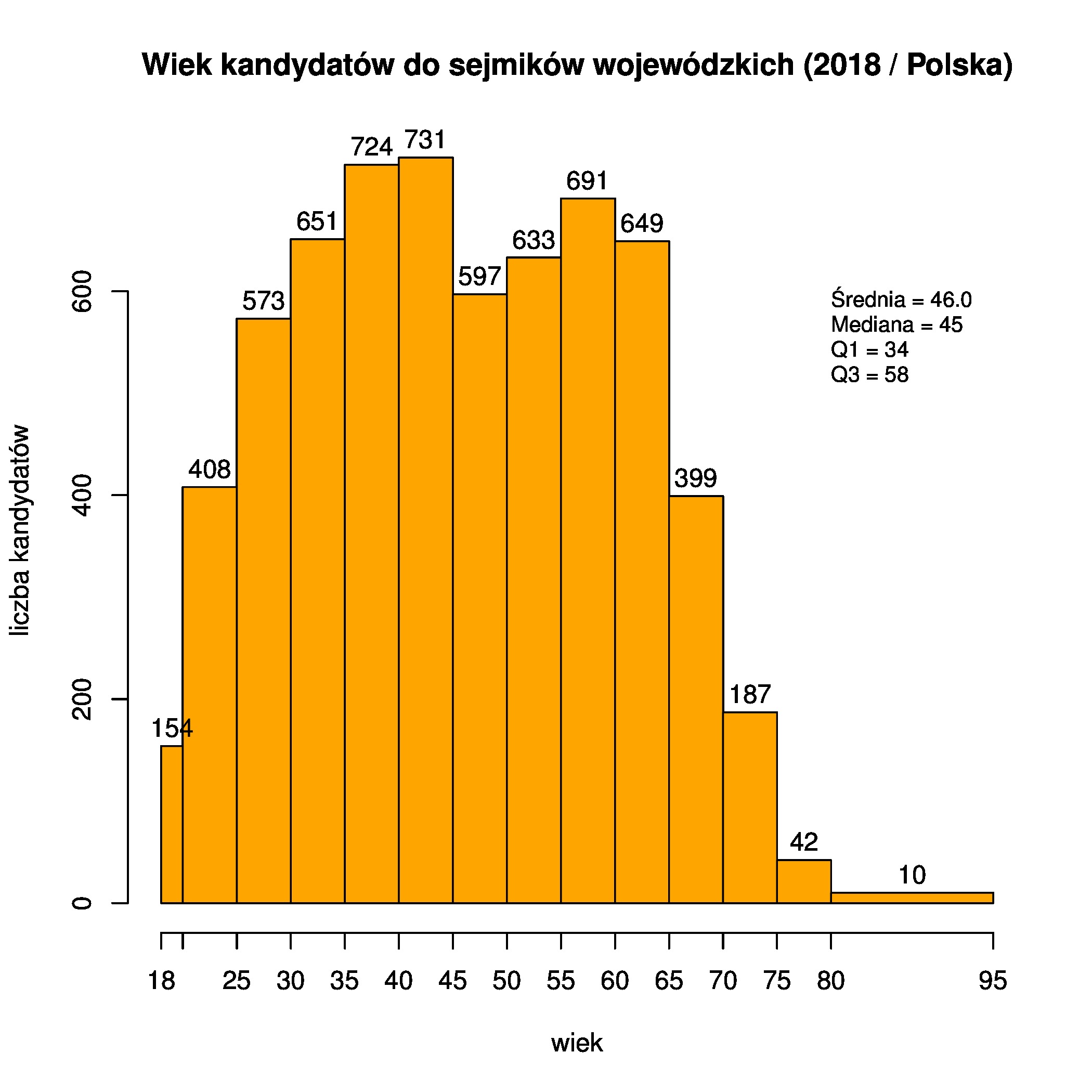
## wykres słupkowy
h <- hist(kandydaci$wiek,
breaks=wB,
freq=TRUE,
col="orange", main="Wiek kandydatów do sejmików...",
ylab="liczba kandydatów", xlab="wiek", labels=T, xaxt='n')
axis(side=1, at=wB)
text(80, 600, summary_label, cex = .8, adj=c(0,1))
## wykres pudełkowy
ggplot(kandydaci, aes(x=komitet, y=wiek, fill=komitet)) +
geom_boxplot() +
ylab("Wiek") +
xlab("Komitet") +
annotate(geom="text", x = 1, y = 90, hjust=0, size=3,
label = "WwS = Wolność w Samorządzie | ...") +
guides(fill=FALSE) ;
| # | komitet | min | q1 | Me | q3 | max |
| 1 | BS | 18.0 | 36.0 | 44.0 | 57.0 | 81.0 |
| 2 | K15 | 18.0 | 32.0 | 42.0 | 53.0 | 82.0 |
| 3 | PiS | 18.0 | 40.0 | 51.0 | 59.0 | 79.0 |
| 4 | PO-N | 18.0 | 41.0 | 51.0 | 60.0 | 75.0 |
| 5 | PSL | 20.0 | 44.0 | 55.0 | 62.0 | 80.0 |
| 6 | RAZEM | 18.0 | 28.0 | 34.0 | 42.0 | 87.0 |
| 7 | RN | 18.0 | 27.0 | 34.0 | 48.0 | 81.0 |
| 8 | SLD-LR | 18.0 | 44.0 | 58.0 | 65.0 | 83.0 |
| 9 | WiS | 18.0 | 38.0 | 50.0 | 61.5 | 85.0 |
| 10 | WwS | 18.0 | 24.0 | 31.0 | 43.0 | 83.0 |
| 11 | ZIELONI | 18.0 | 34.0 | 44.0 | 55.0 | 80.0 |
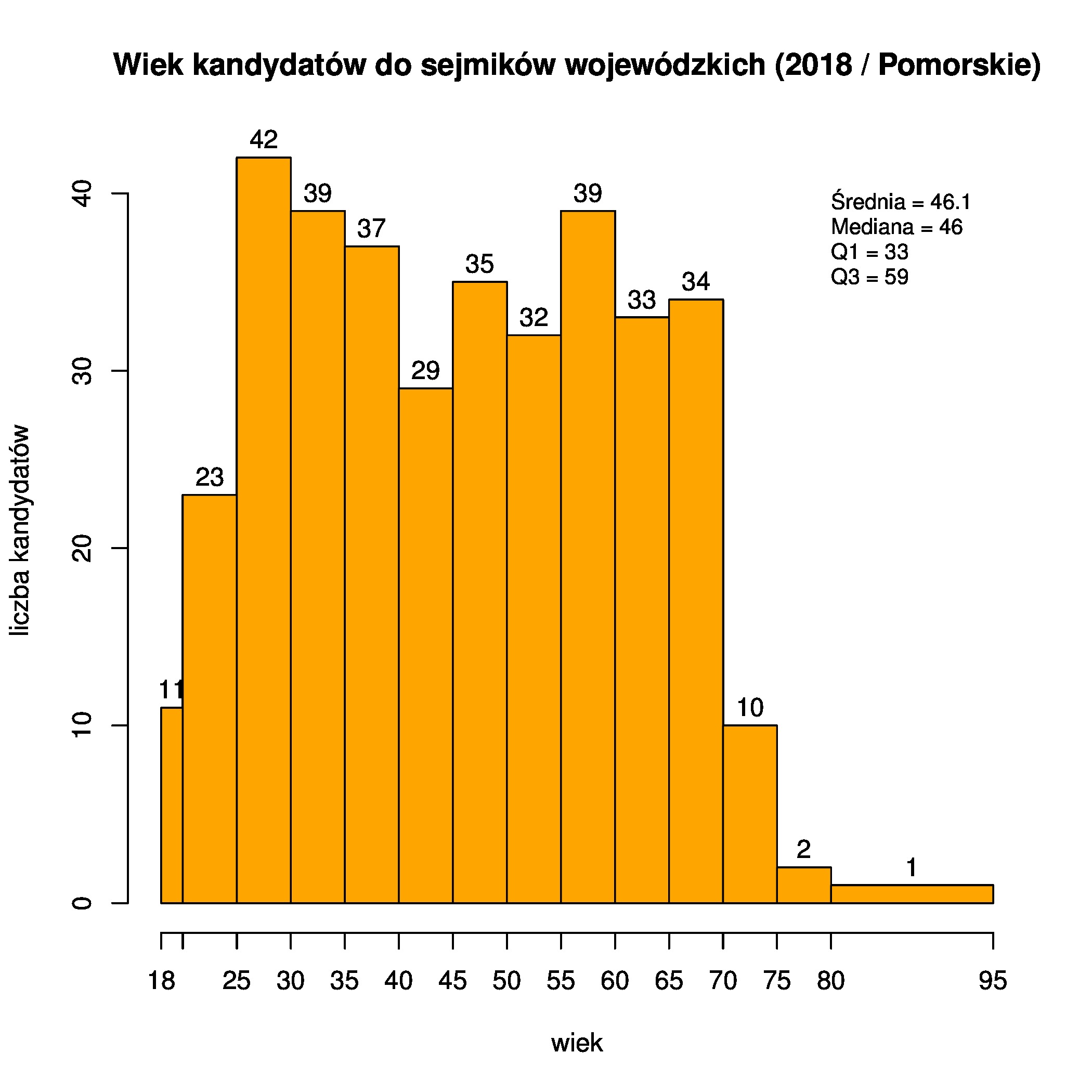
To samo dla woj. pomorskiego:
kandydaci <- subset (kandydaci, (woj == "22" )) aggregate (kandydaci$wiek, list(Numer = kandydaci$komitet), fivenum) ## itd...
| 1 | BS | 23.0 | 36.5 | 44.0 | 47.5 | 72.0 |
| 2 | K15 | 23.0 | 37.0 | 50.0 | 58.0 | 73.0 |
| 3 | PiS | 21.0 | 42.5 | 49.0 | 63.5 | 71.0 |
| 4 | PO-N | 22.0 | 39.0 | 50.0 | 60.5 | 75.0 |
| 5 | PSL | 28.0 | 49.0 | 62.0 | 68.0 | 80.0 |
| 6 | RAZEM | 19.0 | 29.0 | 33.5 | 38.0 | 87.0 |
| 7 | RN | 21.0 | 27.0 | 31.5 | 49.0 | 66.0 |
| 8 | SLD-LR | 18.0 | 50.0 | 59.0 | 62.5 | 75.0 |
| 9 | WwS | 19.0 | 27.0 | 32.0 | 38.5 | 67.0 |
| 10 | ZIELONI | 19.0 | 39.0 | 48.0 | 54.0 | 67.0 |
Dane i skrypty są tutaj.