Kupiłem w Balcie wersję z Suse. Bo tańsza -- 1300 PLN a windows mi nie jest potrzebny (wersja z MS Windows XP, 220 PLN więcej). Chciałem z baterią 6 komorową ale w sklepie utrzymywali, że takowej konfiguracji nie ma -- można co najwyżej osobno dokupić (za ponad 500 PLN). Suse się ładnie zainstalowało, łącznie z WiFi ale, kurcze ostatnio jest zawsze jakieś ale. No więc to Suse jest w wersji 10.2, która jest ciut obsolete. Teraz spędziłem kilka godzin na kombinowaniu jak ten system dostroić do moim potrzeb. Np. nie ma w nim thunderbirda i Emacsa. W Fedorze wpisuję yum install thunderbird emacs emacs-el i ww programy się instalują bezproblemowo. A w Suse tak nie jest--jest program do zarządzania systemem -- yast2, który najpierw trzeba skonfigurować... Chcąc zainstalować cokolwiek najpierw należy podać repozytoria z jakich będą pobierane pakiety.
Pomysł taki sobie--nowy użytkownik musi zaczynać od ustalenia adresów repozytoriów... Do tego system jest lekko starawy, więc repozytoria download.opensuse.org są bezużyteczne bo zaczynają się od wersji 10.3. W sumie to lipa, że HP sprzedaje coś w ten sposób ewidentnie niedorobionego. Zwykłe robienie klienta w balona. No nic, ustaliłem URL repozytorium z wersją 10.2. Dodałem Emacsa i Thunderbirda... Thunderbird jest OK, ale Emacs jest w wersji to 21.3. Za stara... A jak zainstalować coś do oglądania filmów, muzyczki i acrobata... Nie chce mi się ustalać...
Wniosek: gdyby wszystko działało to bym się tej starej Suse (niem. die Alte Suse) trzymał, ale wobec powyższych problemów zacząłem kombinować jakby podmienić system na inny... Ten inny to albo Ubuntu albo Fedora...
W jaki sposób zainstalować system bez napędu CD
Nigdy tego nie robiłem ale okazało się to dość proste. Poprzez google można znaleźć kilka opisów jak przygotować bootowalny napęd USB (bootable USB stick). Sposób opisany w www.mach.x.pl nie działa -- zwis na etapie bootowania. Działa USB przygotowany programem unetbootin. System się uruchamia tyle, że nie działa WiFi. Gorzej -- klawiatura też nie działa. Skoro klawiatura nie działa to i instalacja się nie skończy, bo jak wpisać nazwę użytkownika i hasło? [Z podpiętej USB, kiedyś tak zrobiłem -- ale teraz mi się nie chce:-)] Problem z klawiaturą też miałem w przypadku Vostro 1320 i dotyczył on zarówno Ubuntu jak i Fedory. Jakaś globalna niekompatybilność z nowym laptopami?
Próbowałem -- uruchamiając z USB -- Ubuntu 9.10 (aka Karmic Koala) i to w dwóch wersjach: karmic-desktop-i386.iso oraz karmic-netbook-remix-i386.iso. Klawiatura działa ale obie się wysypują: pierwsza od razu, druga po pewnym -- zresztą krótkim -- czasie używania. Ostatnia nadzieja w Fedorze...
Za pomocą unetbootin przygotowałem pendrive zawierający Fedorę 11. Uruchomiłem i przetestowałem zgrubnie. Ponieważ wszystko w zasadzie działało; zdecydowałem się na zamianę starej Suse na nową Fedorę 11. No i się zaczęła jazda.... Uparłem się podzielić dysk na dwie partycje -- jedną na system a drugą na katalog /home. Przynajmniej w teorii ułatwi to aktualizację systemu w przyszłości. Zdefiniowałem zatem trzy partycje i tutaj pierwsza skucha: FedoraLive domaga się systemu plików ext4. OK, nie ma sprawy -- zmieniłem. Dalej źle -- tym razem coś, że /boot nie może być ext4. Straciłem godzinę, zanim znalazłem wyjaśnienie na stronach bugzilla.redhat.com. Konkretnie sprawa ma się następująco: ,,Yes, with Fedora 11 to install from the live image, you have to have two partitions. This is because we have switched to ext4 as the default filesystem and thus it is used for the rootfs. Unfortunately, the support for ext4 in grub was not ready in time and so you need to have a /boot that's of a filesystem type that grub can boot from (eg, ext3).'' No to żeście sobie koledzy z Fedory skomplikowali niepotrzebnie życie, ale teraz przynajmniej wiadomo co dalej: potrzebna jest ekstra partycja na katalog /boot. Ostatecznie zatem zdefiniowałem cztery partycje: 20 Gb na system, 1,5 Gb na swap, 0,5Gb na /boot oraz resztę na katalog /home.
Teraz z kolei instalator wysypał się przy partycjonowaniu dysku (uprzednio usuwając to co na nim było). Kolejny kłopot. Pierwszym podejrzanym jest unetbootin. Przeglądam zatem stronę How to create and use Live USB. Tam jest opisany sposób alternatywny, wykorzystujący narzędzia z pakietu livecd-tools albo liveusb-creator. Sposób postępowania jest następujący:
yum install livecd-tools liveusb-creator
yum update syslinux # na wszelki wypadek
teraz:
livecd-iso-to-disk ./Fedora-11-i686-Live.iso /dev/sdb1
## należy też wykonać poniższe bo inaczej pendrive nie jest bootowalny
cat /usr/share/syslinux/mbr.bin > /dev/sdb
Rezultat podobny do tego, który uzyskałem za pomocą wersji przygotowanej przez unetbootin. Próbowałem innych wariantów podziału dysku łącznie z tym, w którym system jest instalowanym na jednej partycji... Nic to nie dało -- zawsze kończyło się błędem. Straciłem czas ale przynajmniej teraz wiem że winna jest anakonda. Spróbuję zatem podzielić i sformatować dysk używając gparted w nadziej, że wtedy zainstaluję fedorę. Wersję na USB gparted też przygotowałem za pomocą unetbootina. Wprawdzie w liście wyboru różnych systemów w unetbootin nie ma gparted, ale nie ma to znaczenia wystarczy wybrać z dysku uprzednio ściągnięty plik ISO:
http://superb-west.dl.sourceforge.net/sourceforge/gparted/gparted-live-0.4.6-1.iso
W dwóch krokach udaje się wreszcie podzielić i sformatować dysk tak jak chciałem. W dwóch, bo usunięcie tego co było na dysku, wymagało restartu gparted przed założeniem nowych partycji. Próba wykonania tego ,,za jednym zamachem'' kończyła się błędem... Cud, że starczyło mi cierpliwości na czytanie komunikatów o błędach.
Teraz anakonda się nie wysypuje i cała instalacja kończy się sukcesem. Wreszcie!. Podsumowując: aby zainstalować F11 na HP Mini 2140 trzeba przygotować USB za pomocą unetbootin (bo tak jest najwygodniej) a dysk podzielić i sformatować uprzednio używając gparted. WiFi na starcie nie działa, ale jestem dobrej myśli...
Dostrajanie systemu:
Instalowanie nie każdej aplikacji ma sens na takim komputerze jak HP Mini. Poniższa lista jest w znacznej mierze oparta na poradniku Personal Fedora 11 Installation Guide. Na końcu są dodane moje aplikacje...
A więc rozpoczynam od skonfigurowania yuma; najistotniejsze jest dodanie repozytorium RPMfusion, zawierającego m.in. różne pakiety o statusie non-free:
## ze strony http://www.mjmwired.net/resources/mjm-fedora-f11.html
yum install yum-plugin-fastestmirror
yum install yum-presto
rpm -ivh http://download1.rpmfusion.org/free/fedora/rpmfusion-free-release-stable.noarch.rpm
rpm -ivh http://download1.rpmfusion.org/nonfree/fedora/rpmfusion-nonfree-release-stable.noarch.rpm
W szczególności RPMfusion zawiera pakiet kmod-wl, dzięki któremu mam nadzieję uruchomić sieć WiFi:
## WiFi:
yum install kmod-wl
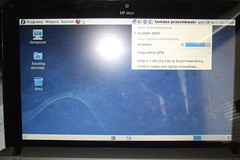
Teraz restart i WiFi działa (dowód na rysunku obok).
W sposób opisany w poradniku Mauriata Mirandy instaluję: Adobe Flash i Adobe Acrobata, xine, xmms, amaroka i parę innych pakietów, głównie związanych z odtwarzaniem plików audio/wideo:
## Adobe Flash Plugin
rpm -ivh http://linuxdownload.adobe.com/adobe-release/adobe-release-i386-1.0-1.noarch.rpm
rpm --import /etc/pki/rpm-gpg/RPM-GPG-KEY-adobe-linux
yum install flash-plugin
## Install Adobe Acrobat
rpm -ivh http://linuxdownload.adobe.com/adobe-release/adobe-release-i386-1.0-1.noarch.rpm
rpm --import /etc/pki/rpm-gpg/RPM-GPG-KEY-adobe-linux
yum install AdobeReader_enu
##
yum install xine xine-lib-extras xine-lib-extras-freeworld
mkdir -p /usr/lib/codecs
wget http://www.mplayerhq.hu/MPlayer/releases/codecs/all-20071007.tar.bz2
tar -jxvf all-20071007.tar.bz2 --strip-components 1 -C /usr/lib/codecs/
## Install Microsoft Truetype Fonts
http://corefonts.sourceforge.net/
## wget http://www.mjmwired.net/resources/files/msttcore-fonts-2.0-3.noarch.rpm
rpm -ivh msttcore-fonts-2.0-3.noarch.rpm
## XMMS i Amarok
yum install xmms xmms-mp3 xmms-faad2 xmms-pulse xmms-skins
yum install amarok xine-lib-extras-freeworld
Na koniec aplikacje, których używam, a które nie sa instalowane przez instalator FedoraLive:
## Moje dodatki:
yum install wget mc ## mam słabość do MidnightCommandera
yum install wine dosbox R amule ktorrent xchm xpdf kchmviewer
yum install tidy mod_dav_svn gnutls-utils kile opensp gv gqview
yum install fuse-sshfs
## ew. można także zainstalować poniższe:
yum install skype JBidWatcher bt747 ydpdict
## co do GoogleEarth to mam wątpliwości czy ma to sens
## poniższe nie instaluję:
## scribus grip sopcast fontforge
Kilka drobiazgów. Zatrzymałem następujące usługi: mdmonitor, smolt, rpcbind, crond, cups. Aby przy starcie nie odgrywał sygnału powitalnego należy odhaczyć: System-Preferencje-Programy startowe-Gnome login sound. Terminal gnome uruchamiam z opcją --hide-menubar, dzięki temu nie jest wyświetlany (niepotrzebny) pasek menu.
Konfiguracja Jawy SDK. Po ściągnięciu ze strony http://java.sun.com stosownego pliku (w moim przypadku jdk-6u4-linux-i586.bin) zmieniam domyślne ustawienia za pomocą polecenia alternatives:
/usr/sbin/alternatives --config java ## # sprawdzam co jest zainstalowane <Enter>
/usr/sbin/alternatives --install /usr/bin/java java /opt/jdk1.6.0_04/bin/java 20000
/usr/sbin/alternatives --config java # wybieram 3<Enter>
Thunderbird3 beta. W fedorze 11 zdecydowano się na wersję beta Thunderbirda. Decyzja chyba nie do końca przemyślana -- można w google znaleźć narzekania, że to-czy-tamto nie działa. Dla mnie Thunderbird3 jest do kitu przede wszystkim z powodu niekompatybilności z jedyną z kilku używanych przeze mnie wtyczek, a mianowicie SyncKolab. [SyncKolab pozwala na synchronizację książek adresowych]. Problem rozwiązałem ściągając ,,ręcznie'' z repozytorium wersję Thunderbirda dla FC 10. Przykładowo z (znak \ poniżej na końcu wiersza oznacza kontynuację):
http://ftp.uni-erlangen.de/pub/Linux/MIRROR.fedora/core/updates/10/i386/\
thunderbird-2.0.0.23-1.fc10.i386.rpm
Teraz:
rpm -Uvh thunderbird-2.0.0.23-1.fc10.i386.rpm
Nikt nie protestuje -- wygląda, że wersje bibliotek się zgadzają. Na razie działa:-) Żeby przy aktualizacji nie usiłował jednak zainstalować TB3, dopisuję w pliku /etc/yum.conf:
exclude=thunderbird
Akumulator trzyma około 2 godziny 10 minut. Przy włączonym WiFi/Bluetooth; odtwarzanie filmu + kopiowanie kilkuset megabajtów plików z drugiego komputera.
Dopisane 29 września 2009: Wielkości fontu w Emacs określam dodając do pliku /etc/X11/Xresources wpis:
Emacs.font: Monospace-9
Zamiast /etc/X11/Xresources można wpisać do ~/.Xresources, po czym wykonać:
xrdb -merge ~/.Xresources
Dociągam też program do rozpakowywania plików .rar
yum install unrar
Kompilowanie ydpdict. Ydpdict służy do obsługi słowników firmy YDP. [YDP sprzedaje swoje słowniki wraz z aplikacją pozwalającą na ich przeglądania; aplikacja jest przeznaczona dla środowiska MS Windows]. Zatem ze strony toxygen.net ściągnąć należy pliki libydpdict-1.0.1.tar.gz oraz ydpdict-1.0.0.tar.gz. Uprzedzając wydarzenia potrzebne jest dociągnięcie dwóch pakietów:
yum install ncurses-devel libao-devel
Teraz rozpakowujemy oba archiwa .tar.gz. W każdym wykonujemy sekwencję (rozpoczynając do archiwum z biblioteką):
./configure && make && make install
Pliki słownika kopiuję do katalogu /usr/local/share/ydpdict. W pliku konfiguracyjnym ~/.ydpdictrc wpisuję:
Path /usr/local/share/ydpdict
Dla wygody można zdefiniować aktywator na panelu.
Dopisane 15 października 2009: Wielkości fontu w pasku menu i menach Emacsa określam dodając do pliku ~/.emacs.d/gtkrc:
http://www.gnu.org/software/emacs/manual/html_node/emacs/GTK-resources.html#GTK-resources
# Define the style 'menufont'.
style "menufont"
{
font_name = "Sans 8" # This is a Pango font name
}
# Specify that widget type '*emacs-menuitem*' uses 'menufont'.
widget "*emacs-menuitem*" style "menufont"
Aby okno Emacsa było maksymalnie duże dodaję do .emacs:
;; nie wyświetlaj paska narzędzi
(tool-bar-mode 0)
Zmieniam też kolor tła na lekko niebieskawy:
(set-background-color "skyblue")
Powyższe wstawiam na samym końcu pliku .emacs, bo inaczej jest ignorowane (pewnie gdzieś ,,po drodze'', w jakimś pakiecie jest ustawiany inny kolor tła). Nota bene: w ten sposób ustawiony kolor jest nadpisywany przez pakiety--muszę znaleźć cwańszy sposób.
Większa bateria i inne dodatki
W sklepie ultimate-netbook.co.uk kupiłem sześcio-komorową baterię oraz nie tyle pokrowiec co coś w rodzaju okładek do netbooka (wszystko kosztowało nieco mniej niż 300 PLN, łącznie z przesyłką). W pierwszych testach bateria trzyma ponad 4,5 godziny--satysfakcjonujący wynik. Ciekawostką jest, że bateria jest większa od standardowej trzy-komorowej i wystaje znacząco, tak że komputer nie leży już prosto na stole, tylko ma ,,zadarty ekran'' (bo podparty wystającą baterią -- por. rysunek obok)... Można się przyzwyczaić, aczkolwiek w pierwszej chwili są wątpliwości...
Ponadto zainstalowałem jednak GoogleEarth i działa toto zupełnie znośnie. W Fedorze 11 GoogleEarth nie działa ,,out-of-the-box'', bo jest jakiś problem z SELinux. Należy wykonać:
## https://bugzilla.redhat.com/show_bug.cgi?id=485886
restorecon -R -v /opt/google-earth/
Dopisane 20 października 2009 (Zainstalowanie programu gretl): Należy wybrać wersję dla older Linux -- wersja ,,modern'' (tj. gretl-1.8.5-1RHEL.i586.rpm) jest kompilowana z bibliotekami, których nie byłem w stanie zainstalować w F11. Przed zainstalowaniem gretla należy ,,dociągnąć'' wymagane biblioteki:
yum install blas lapack blas-devel lapack-devel gnuplot
## libreadline jest ale nie w tej wersji co trzeba:
ln -s /lib/libreadline.so.5 /lib/libreadline.so.4
teraz (opcja --nodeps jest potrzebna bo inaczej instalator będzie zgłaszał błąd -- brak biblioteki libreadline.so.4):
rpm -Uvh --nodeps gretl-1.8.5-1RHEL.i586.rpm
Doinstalowanie pakietów Perla niezbędnych do działania moich skryptów obsługujących flickr.com.
yum install perl-ExtUtils-MakeMaker perl-SOAP-Lite perl-Crypt-SSLeay \
perl-Test-Simple perl-XML-Simple perl-Text-Iconv \
perl-GDGraph perl-Image-ExifTool
## poniższe dwa pakiety trzeba doinstalować ,,ręcznie'':
XML-Parser-Lite-Tree-0.03 Geo-Coordinates-DecimalDegrees
Do oglądania i drukowania plików PDF/PS (zwłaszcza PS) w FC11 służy evince (instalowany domyślnie). Bardzo fajny program ale ja doinstalowuję jeszcze gv oraz xpdf. W pliku konfiguracyjnym /usr/share/gv/GV zmieniam:
# Odświeżaj zmodyfikowany plik automatycznie:
GV.watchFile: True
# Początkowe przeskalowanie
GV.scale: 1
Dopisane 22 października 2009: Spróbowałem aplikacji do obsługi telefonu komórkowego:
yum install gammu wammu kdebluetooth
Aplikacja kbluetooth4 nie działa; nie analizowałem dlaczego. W wammu udało się połączyć z telefonem (model SE K800i) ściągnąć wiadomości i kontakty. Nie działa niestety funkcja wysyłania SMSów, ale jeszcze powalczę może coś się da zrobić. Doczytam w szczególności tutaj.
Wreszcie, ponieważ okna dialogowe wammu nie mieściły się na ekranie zmniejszyłem font systemowy (System-Preferencje-Wygląd-Czcionki) do 9 punktów. Nota bene domyślne 10 punktów jest za duży. Dzięki temu zyskałem też całe cztery piksele ponieważ minimalna wysokość panela wynosi teraz 24 piksele (a było 26). Dolny panel zmieniłem na chowający się automatycznie (Automatyczne ukrywanie). Dzięki tym zabiegom zyskałem circa 20 pikseli więcej na okna aplikacji...
Ostatnia zmiana w konfiguracji, to wywalenie z górnego panelu apletu Aplikacji, Miejsca i System i zastąpienie go ikoną Menu Główne, dzięki czemu jest więcej miejsca na ikony aplikacji. Wszystkie ikony umieszczam w górnym panelu.