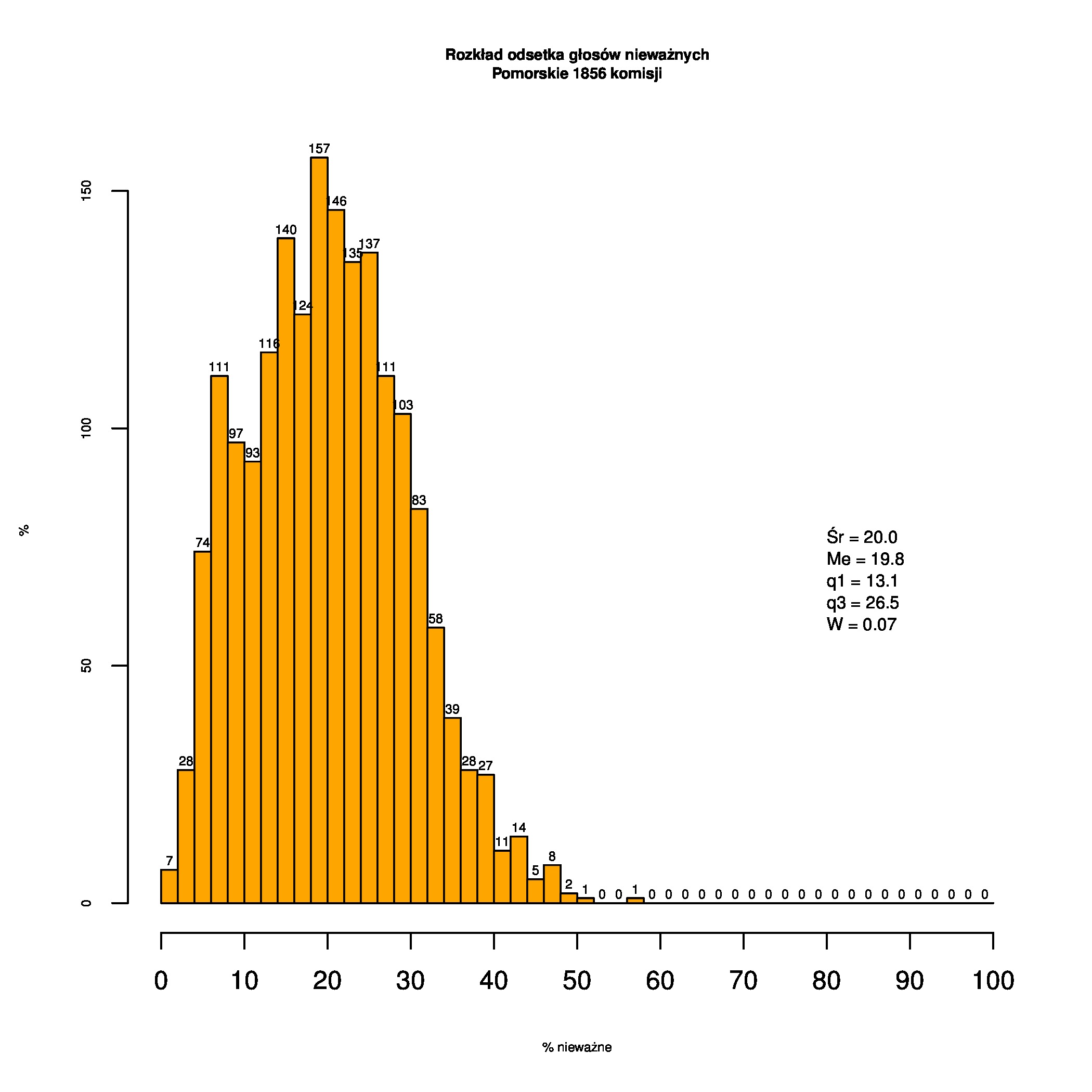
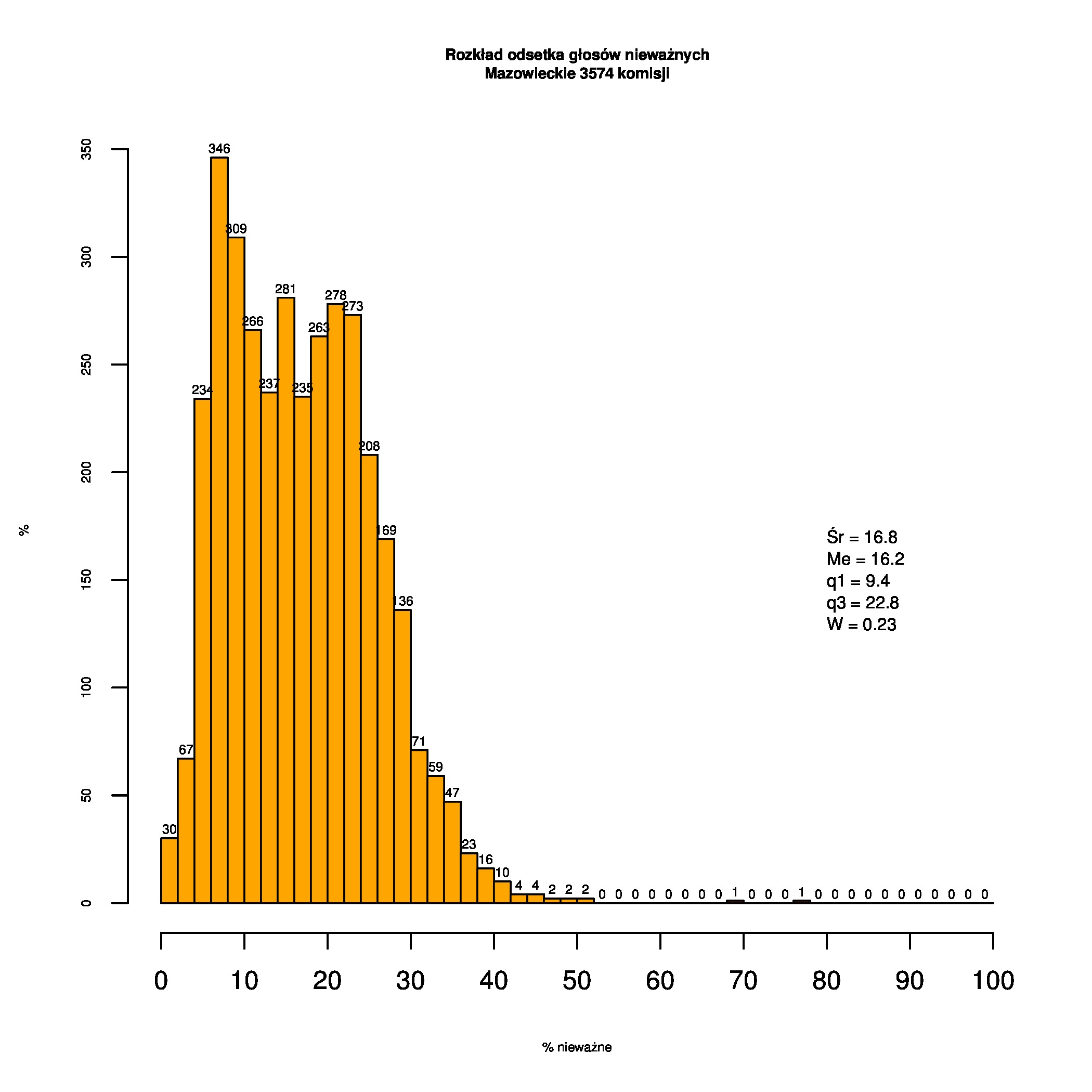
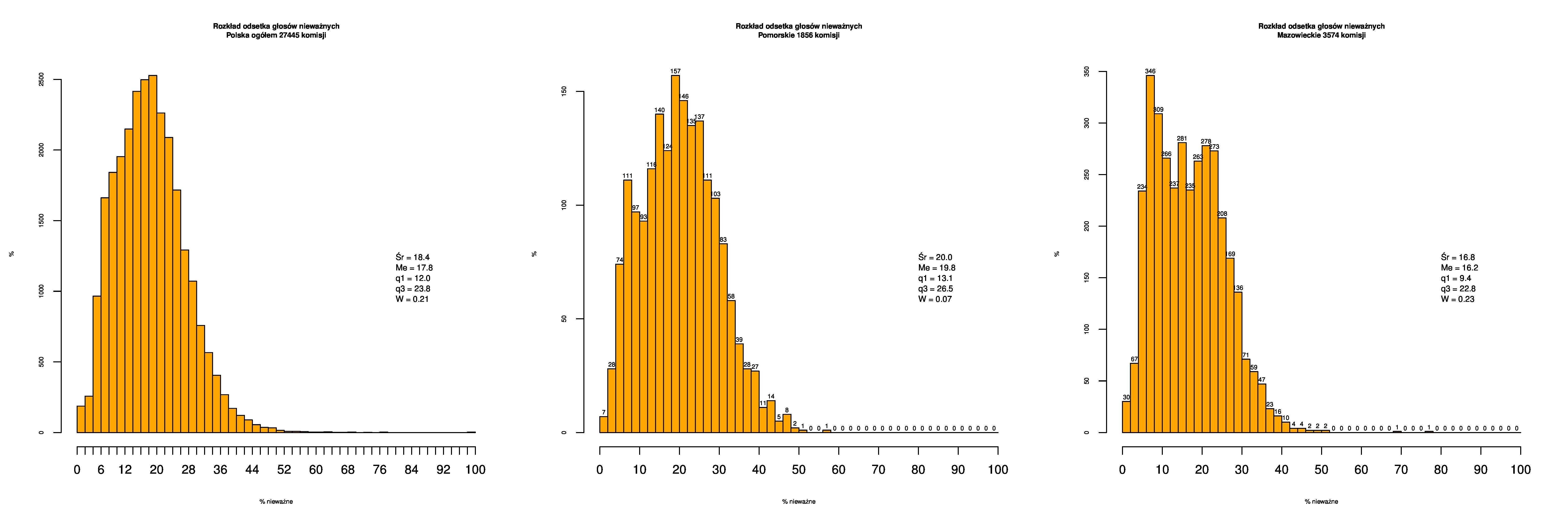
Rozkład odsetka głosów nieważnych (definiowanego jako głosy nieważne / (głosy ważne + nieważne)) w wyborach samorządowych w 2014. Pierwszy histogram dotyczy całej Polski (27455 komisji), drugi województwa pomorskiego (1856) a trzeci Mazowieckiego (3574).
#!/usr/bin/Rscript
# Skrypt wykreśla histogramy dla danych z pliku ws2014_komisje.csv
# (więcej: https://github.com/hrpunio/Data/tree/master/ws2014_pobranie_2018)
#
par(ps=6,cex=1,cex.axis=1,cex.lab=1,cex.main=1.2)
komisje <- read.csv("ws2014_komisje.csv", sep = ';',
header=T, na.string="NA");
komisje$ogn <- komisje$glosyNiewazne / (komisje$glosy + komisje$glosyNiewazne) * 100;
summary(komisje$glosyNiewazne); fivenum(komisje$glosyNiewazne);
sX <- summary(komisje$ogn);
sF <- fivenum(komisje$ogn);
sV <- sd(komisje$ogn, na.rm=TRUE)
skewness <- 3 * (sX[["Mean"]] - sX[["Median"]])/sV
summary_label <- sprintf ("Śr = %.1f\nMe = %.1f\nq1 = %.1f\nq3 = %.1f\nW = %.2f",
sX[["Mean"]], sX[["Median"]], sX[["1st Qu."]], sX[["3rd Qu."]], skewness)
## ##
kpN <- seq(0, 100, by=2);
kpX <- c(0, 10,20,30,40,50,60,70,80,90, 100);
nn <- nrow(komisje)
h <- hist(komisje$ogn, breaks=kpN, freq=TRUE,
col="orange", main=sprintf ("Rozkład odsetka głosów nieważnych\nPolska ogółem %i komisji", nn),
ylab="%", xlab="% nieważne", labels=F, xaxt='n' )
axis(side=1, at=kpN, cex.axis=2, cex.lab=2)
posX <- .5 * max(h$counts)
text(80, posX, summary_label, cex=1.4, adj=c(0,1))
## ##
komisje$woj <- substr(komisje$teryt, start=1, stop=2)
komisjeW <- subset (komisje, woj == "22"); ## pomorskie
nn <- nrow(komisjeW)
sX <- summary(komisjeW$ogn); sF <- fivenum(komisjeW$ogn);
sV <- sd(komisjeW$ogn, na.rm=TRUE)
skewness <- 3 * (sX[["Mean"]] - sX[["Median"]])/sV
summary_label <- sprintf ("Śr = %.1f\nMe = %.1f\nq1 = %.1f\nq3 = %.1f\nW = %.2f",
sX[["Mean"]], sX[["Median"]], sX[["1st Qu."]], sX[["3rd Qu."]], skewness)
h <- hist(komisjeW$ogn, breaks=kpN, freq=TRUE,
col="orange", main=sprintf("Rozkład odsetka głosów nieważnych\nPomorskie %i komisji", nn),
ylab="%", xlab="% nieważne", labels=T, xaxt='n' )
axis(side=1, at=kpX, cex.axis=2, cex.lab=2)
posX <- .5 * max(h$counts)
text(80, posX, summary_label, cex=1.4, adj=c(0,1))
komisjeW <- subset (komisje, woj == "14"); ## mazowieckie
nn <- nrow(komisjeW)
sX <- summary(komisjeW$ogn); sF <- fivenum(komisjeW$ogn);
sV <- sd(komisjeW$ogn, na.rm=TRUE)
skewness <- 3 * (sX[["Mean"]] - sX[["Median"]])/sV
summary_label <- sprintf ("Śr = %.1f\nMe = %.1f\nq1 = %.1f\nq3 = %.1f\nW = %.2f",
sX[["Mean"]], sX[["Median"]], sX[["1st Qu."]], sX[["3rd Qu."]], skewness)
h <- hist(komisjeW$ogn, breaks=kpN, freq=TRUE,
col="orange", main=sprintf("Rozkład odsetka głosów nieważnych\nMazowieckie %i komisji", nn),
ylab="%", xlab="% nieważne", labels=T, xaxt='n' )
axis(side=1, at=kpX, cex.axis=2, cex.lab=2)
posX <- .5 * max(h$counts)
text(80, posX, summary_label, cex=1.4, adj=c(0,1))
Wyniki są takie oto (indywidualne wykresy tutaj: #01 #02 #03):
{kind=link}
{kind=link}
{kind=link}
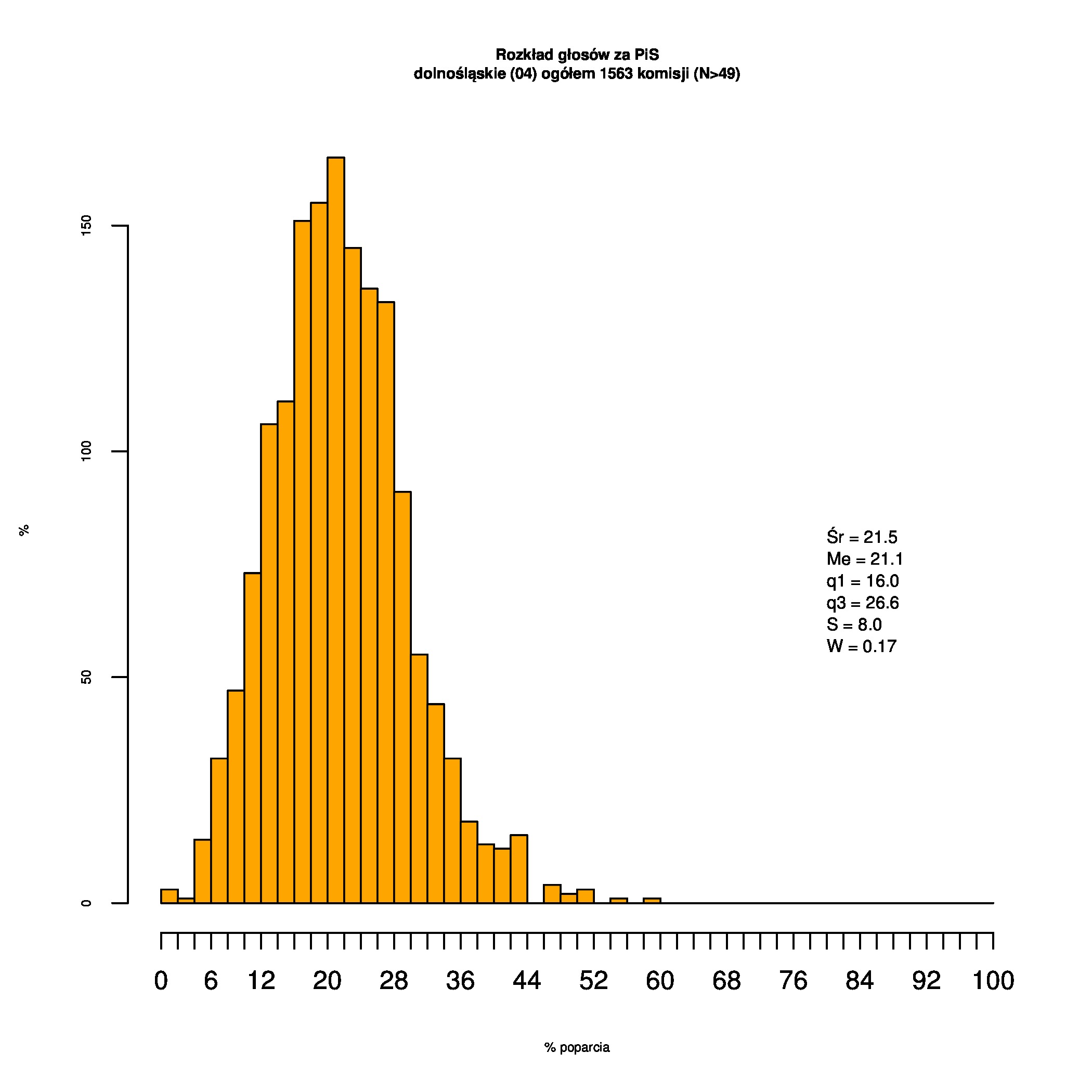
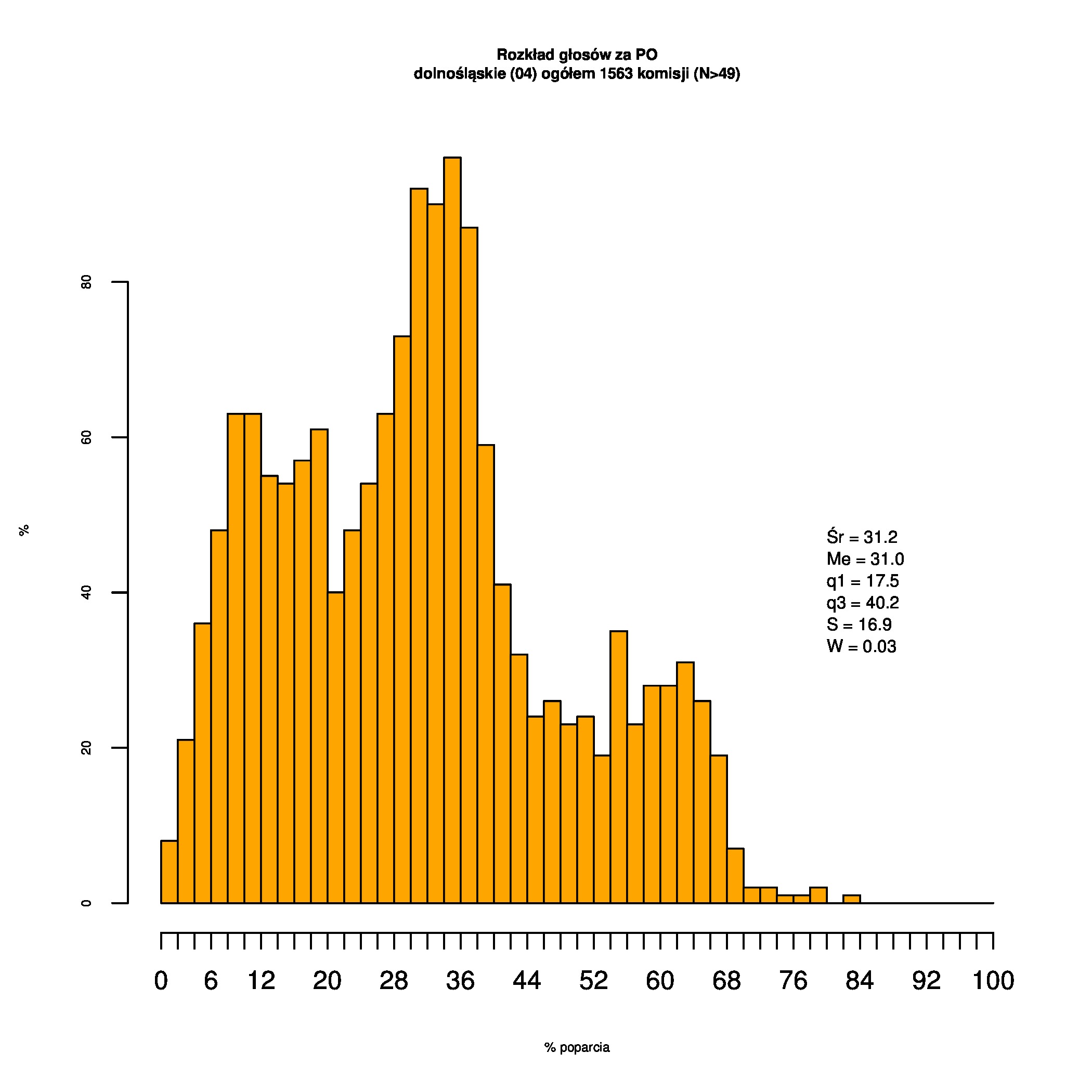
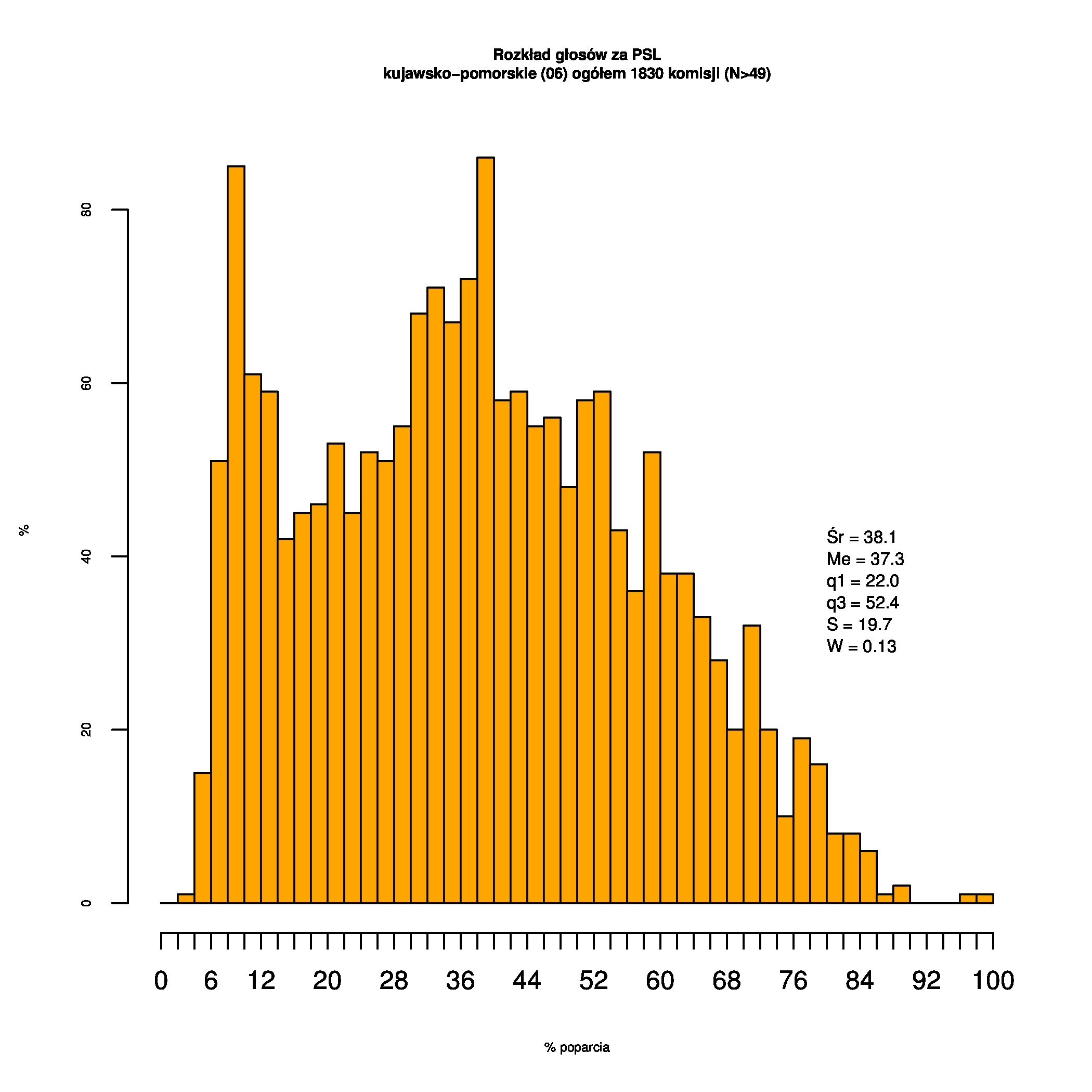
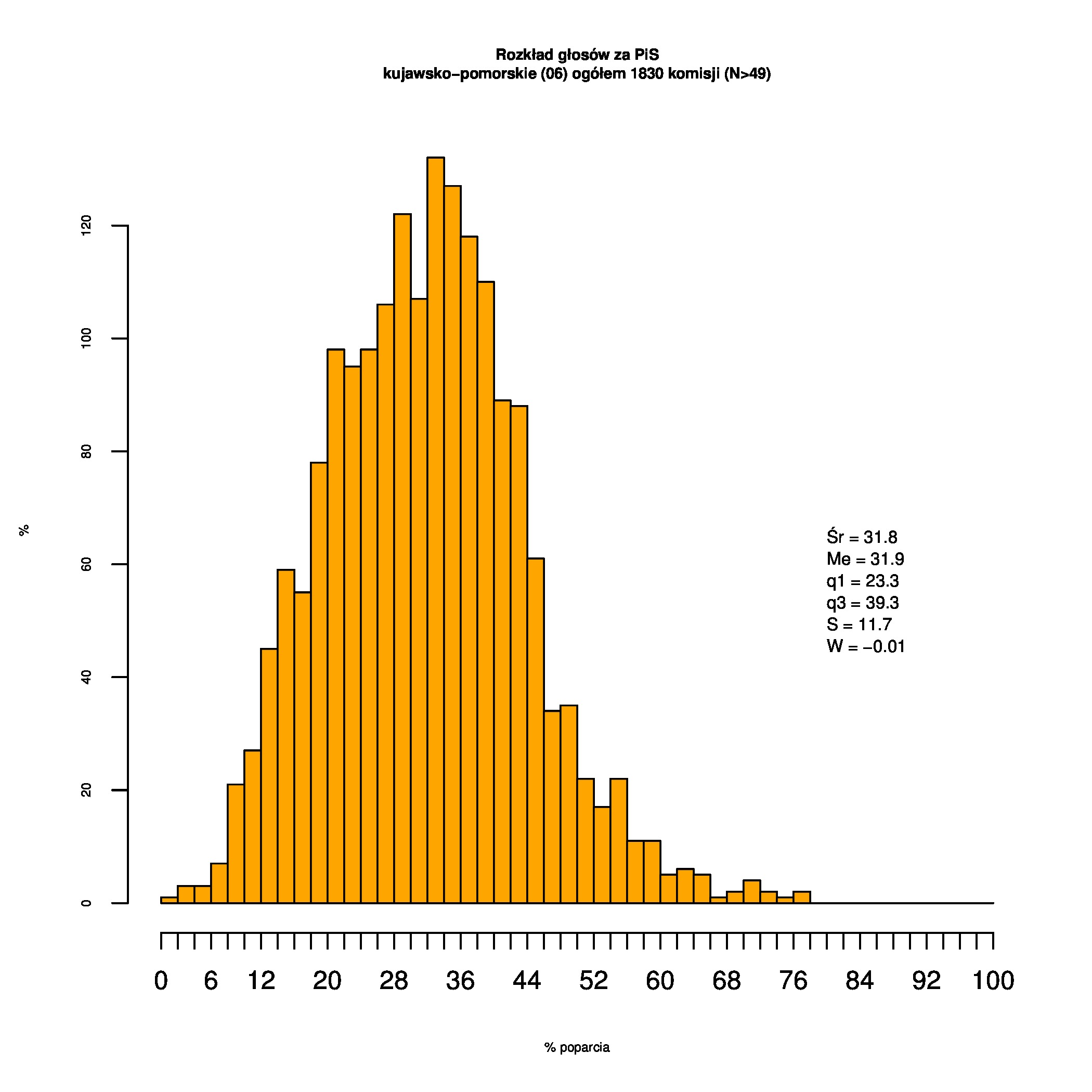
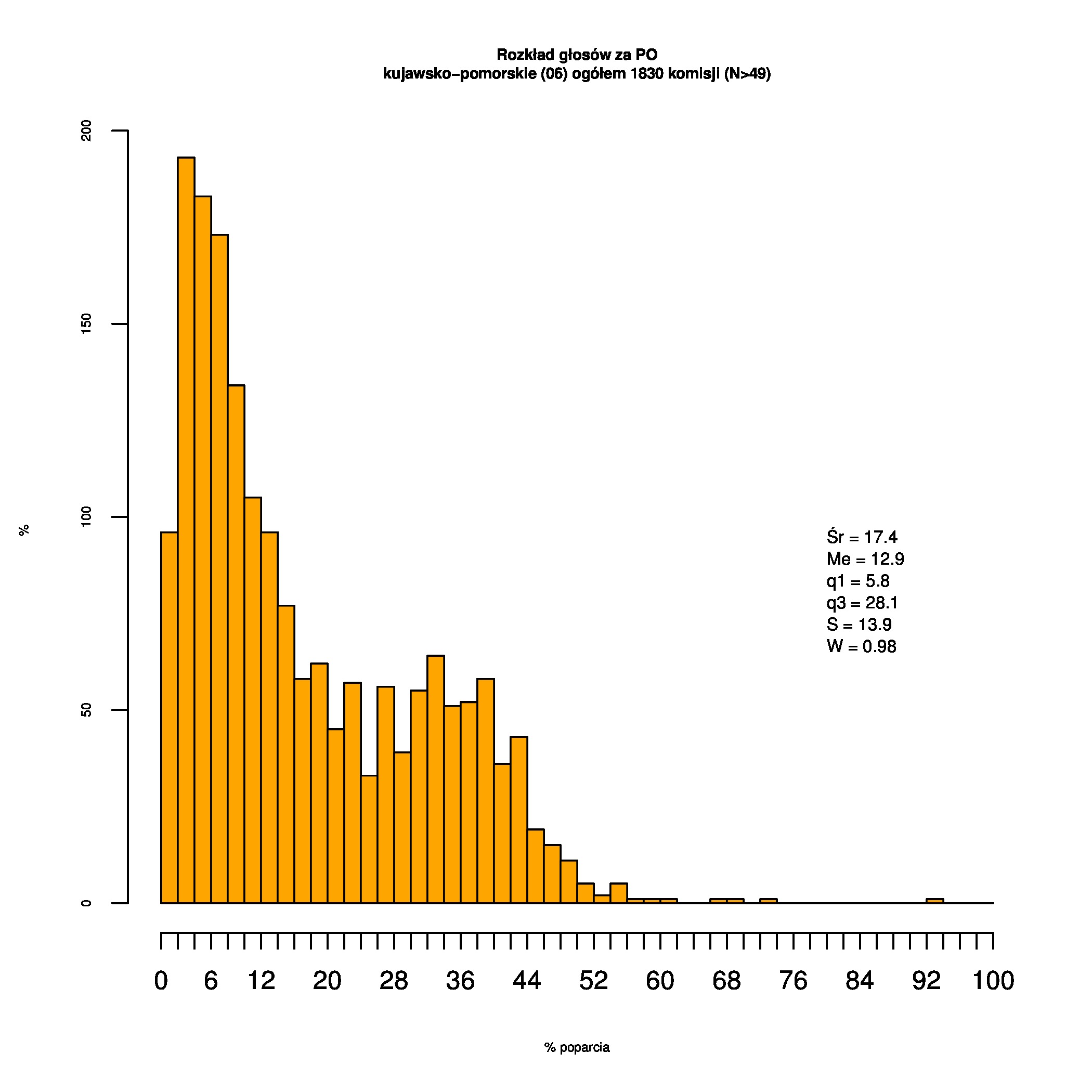
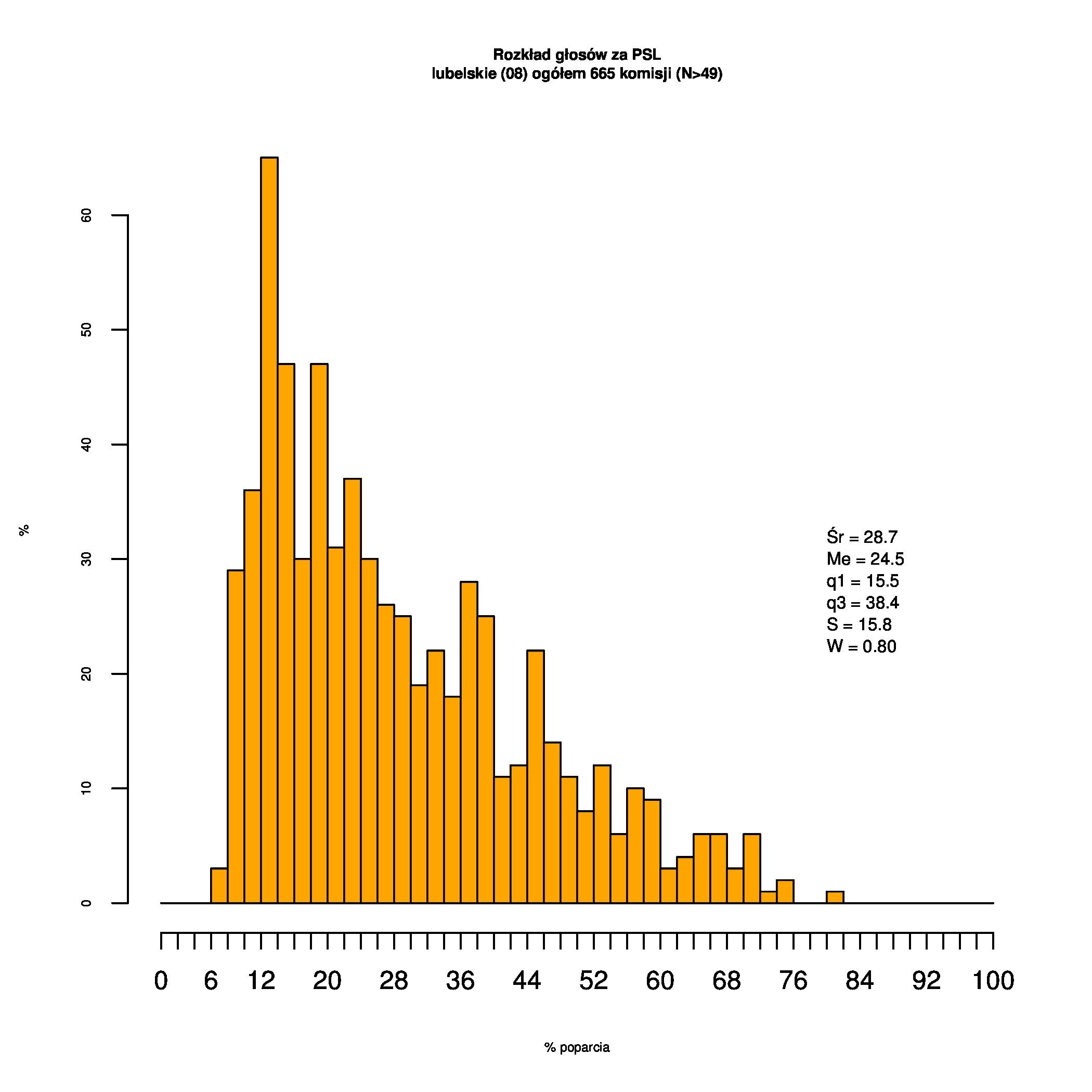
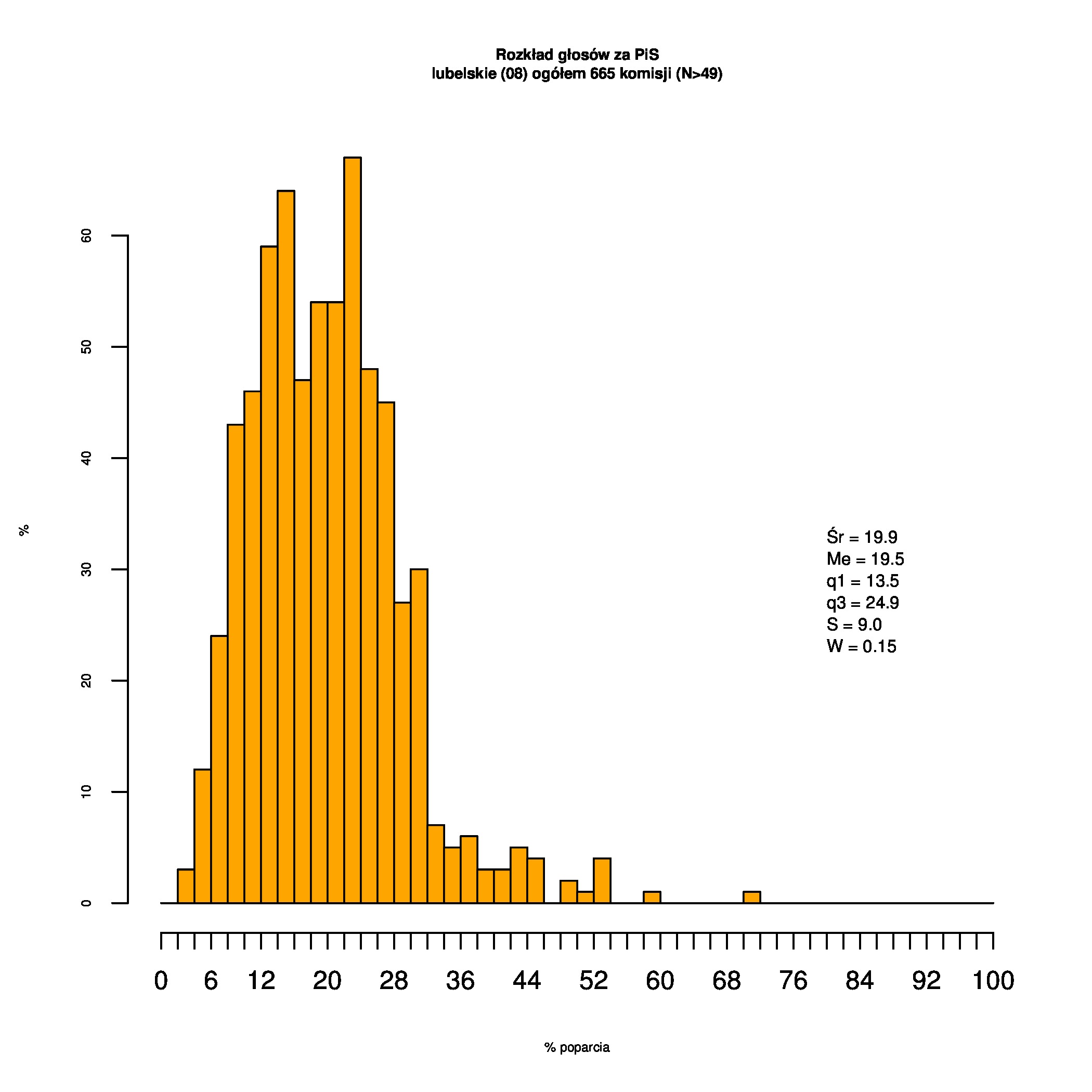
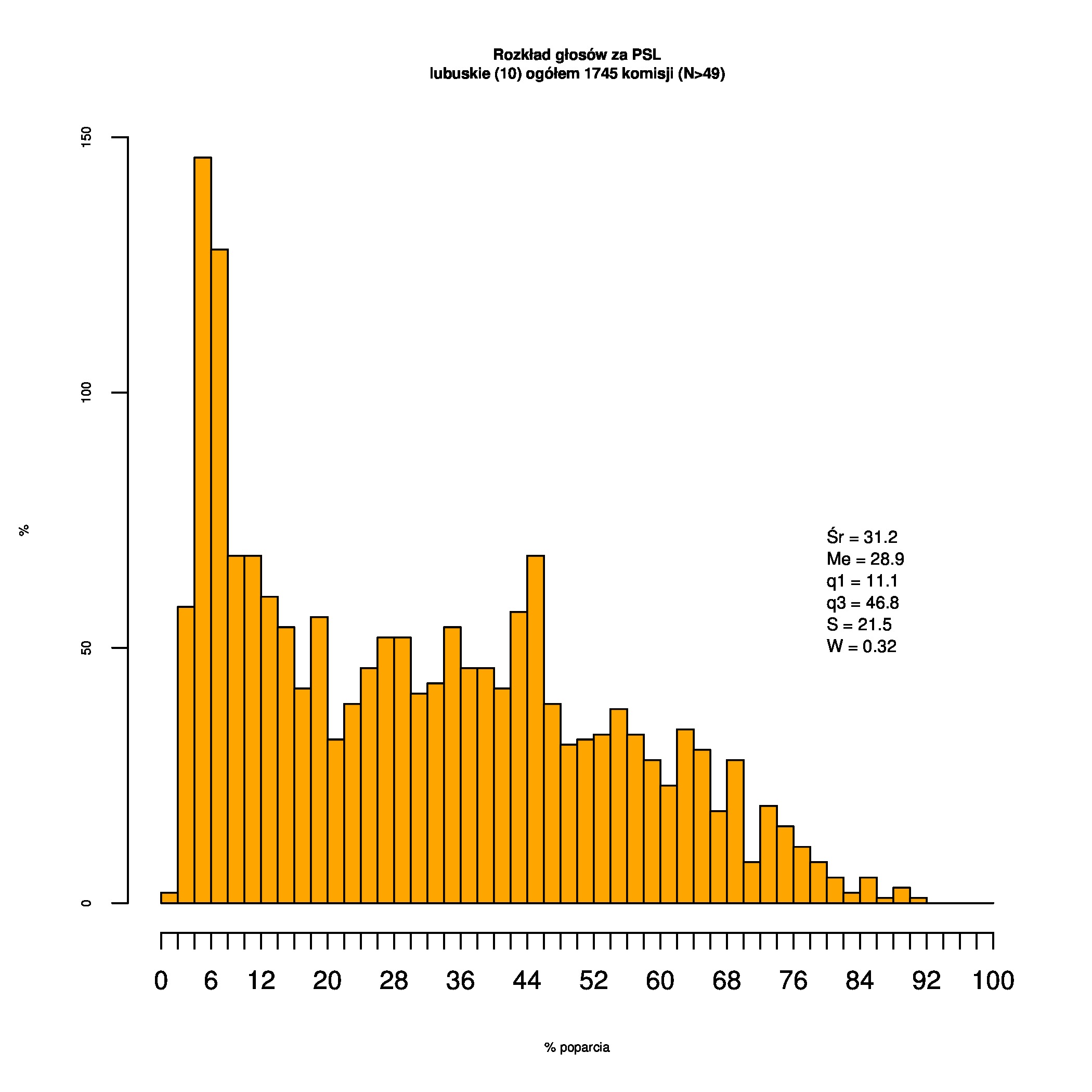
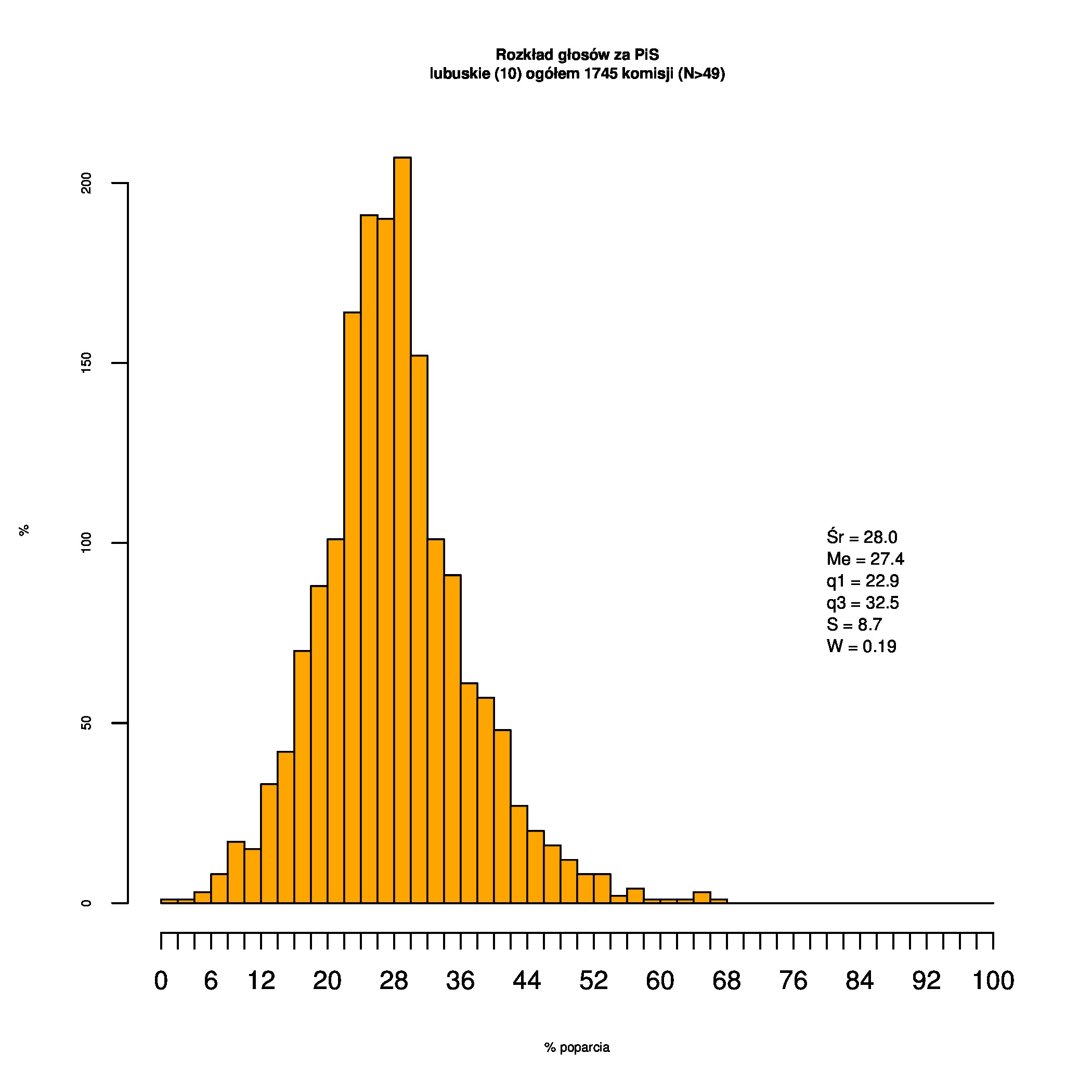
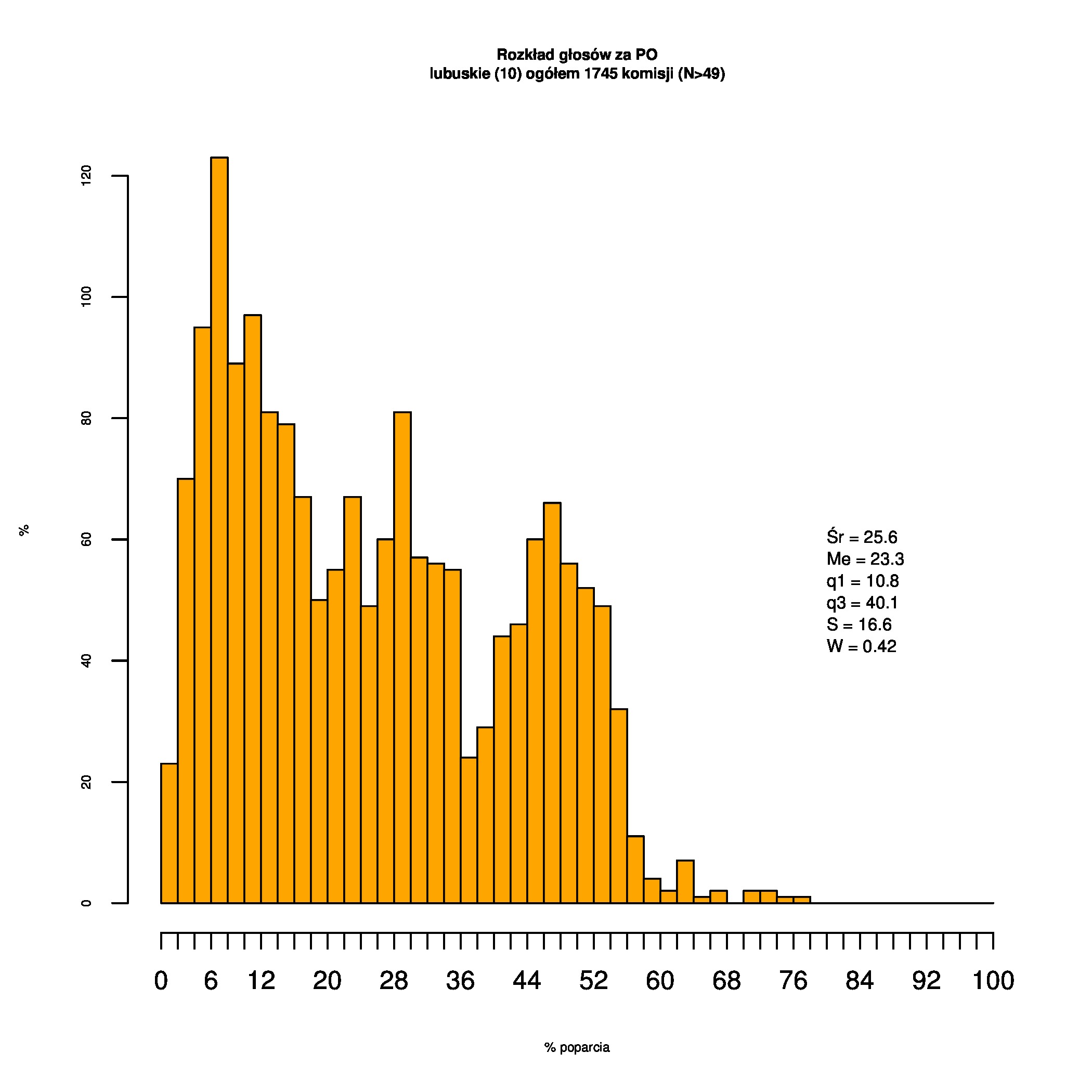
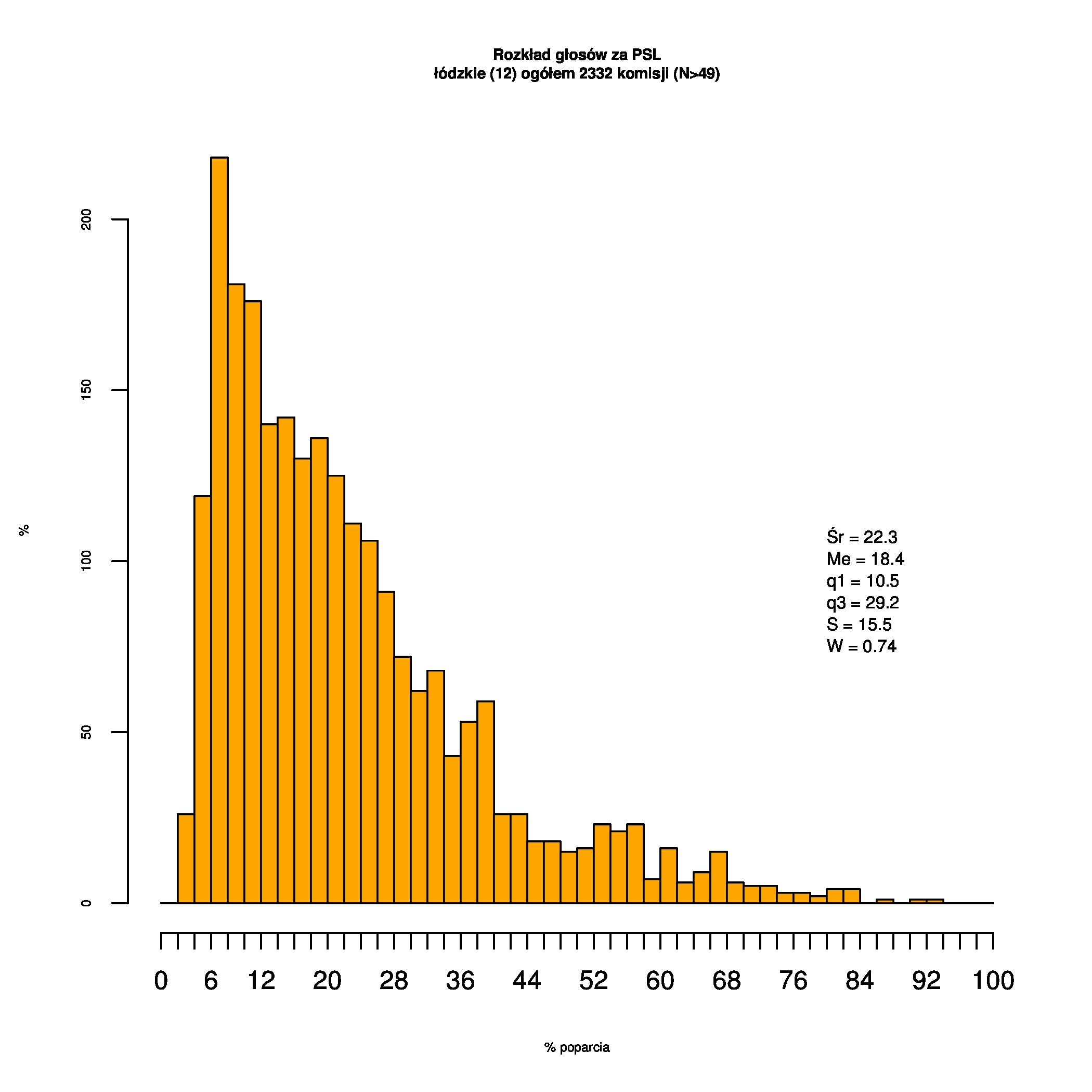
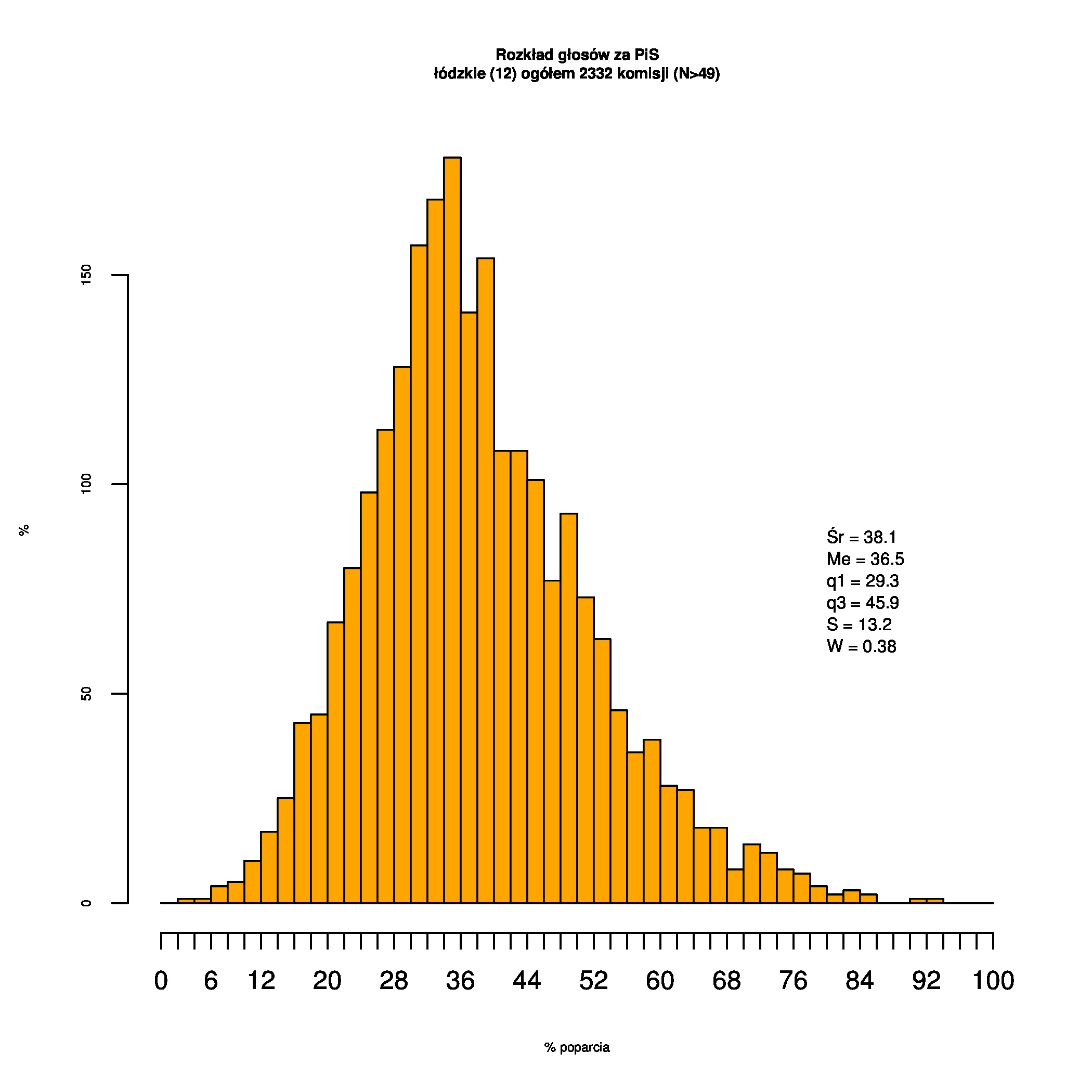
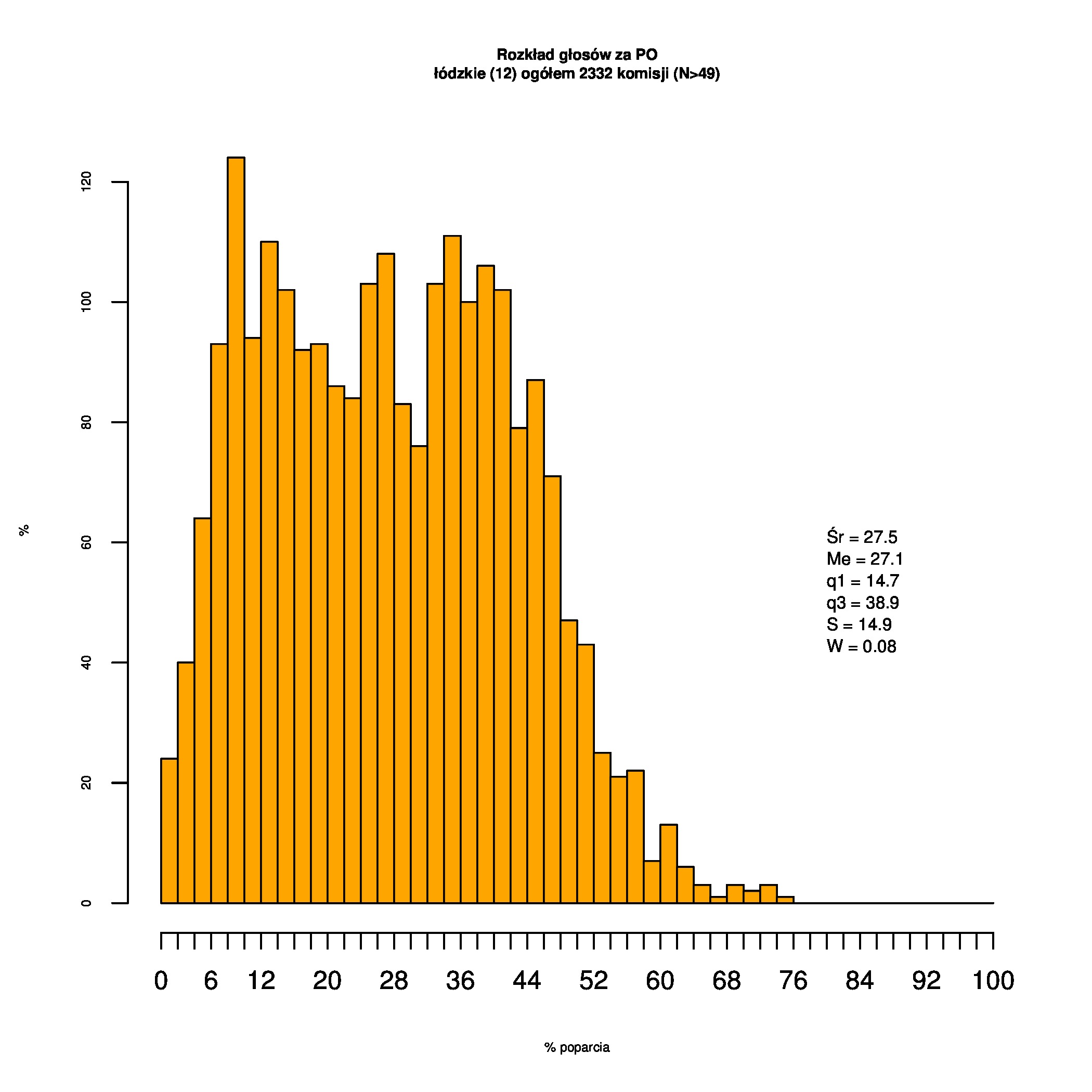
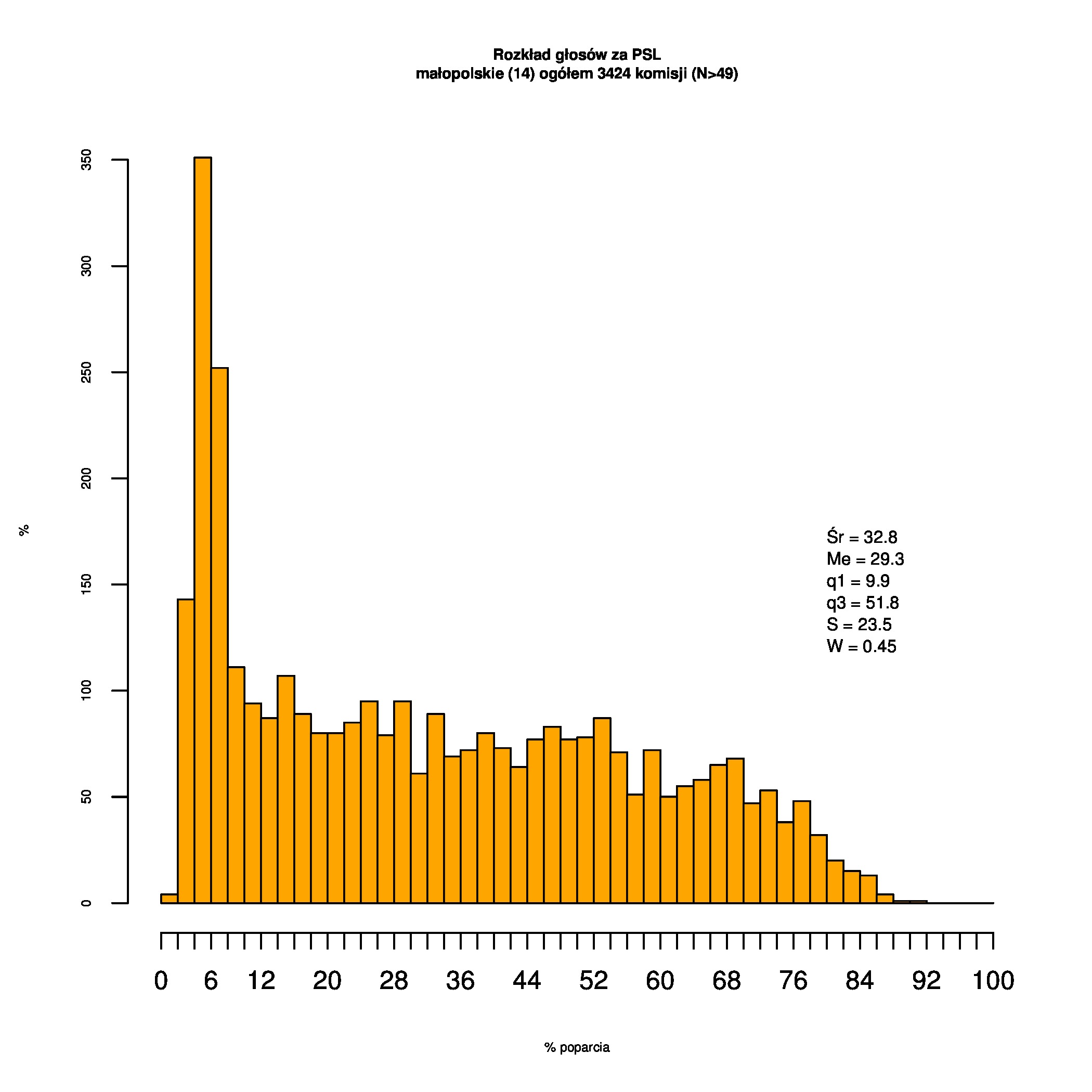
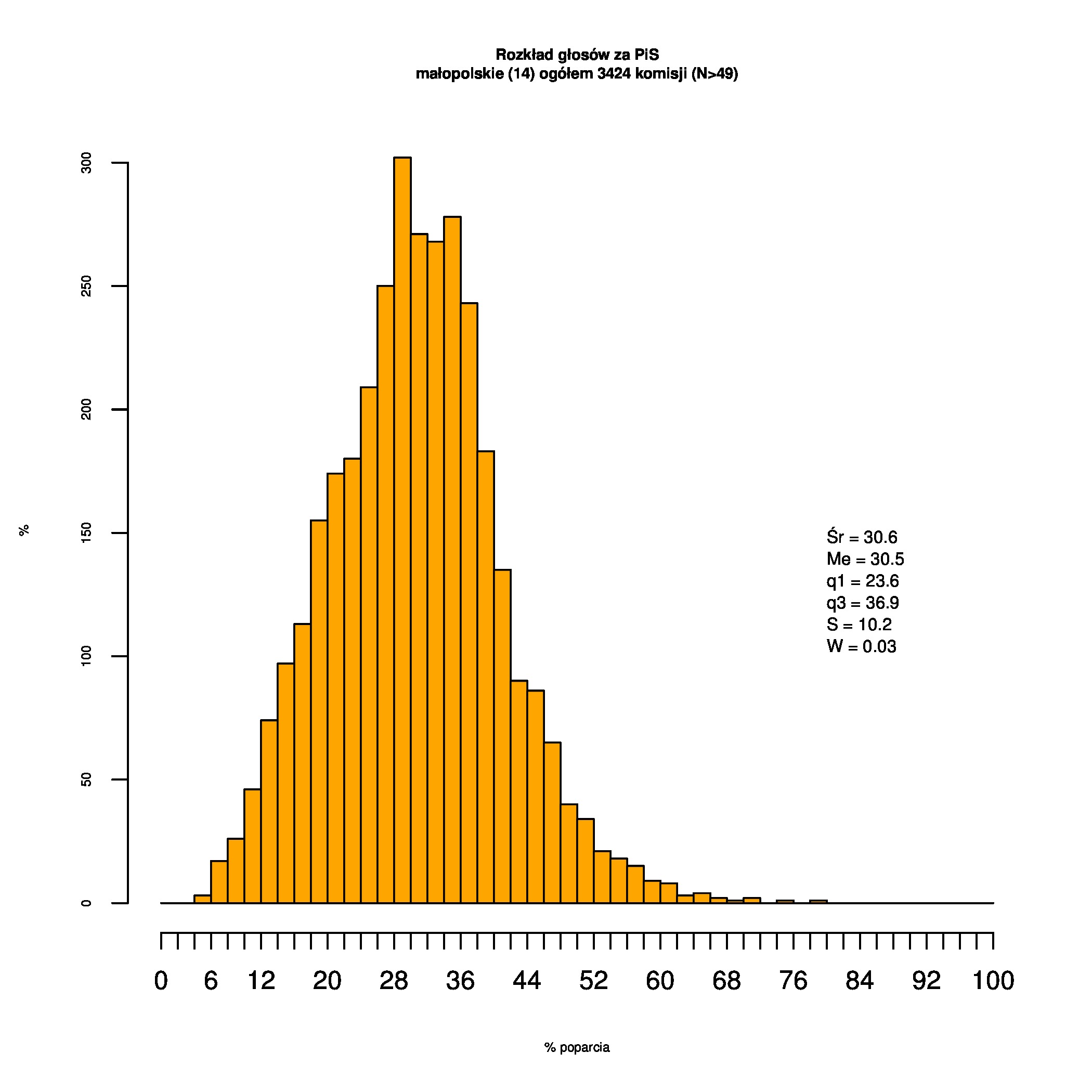
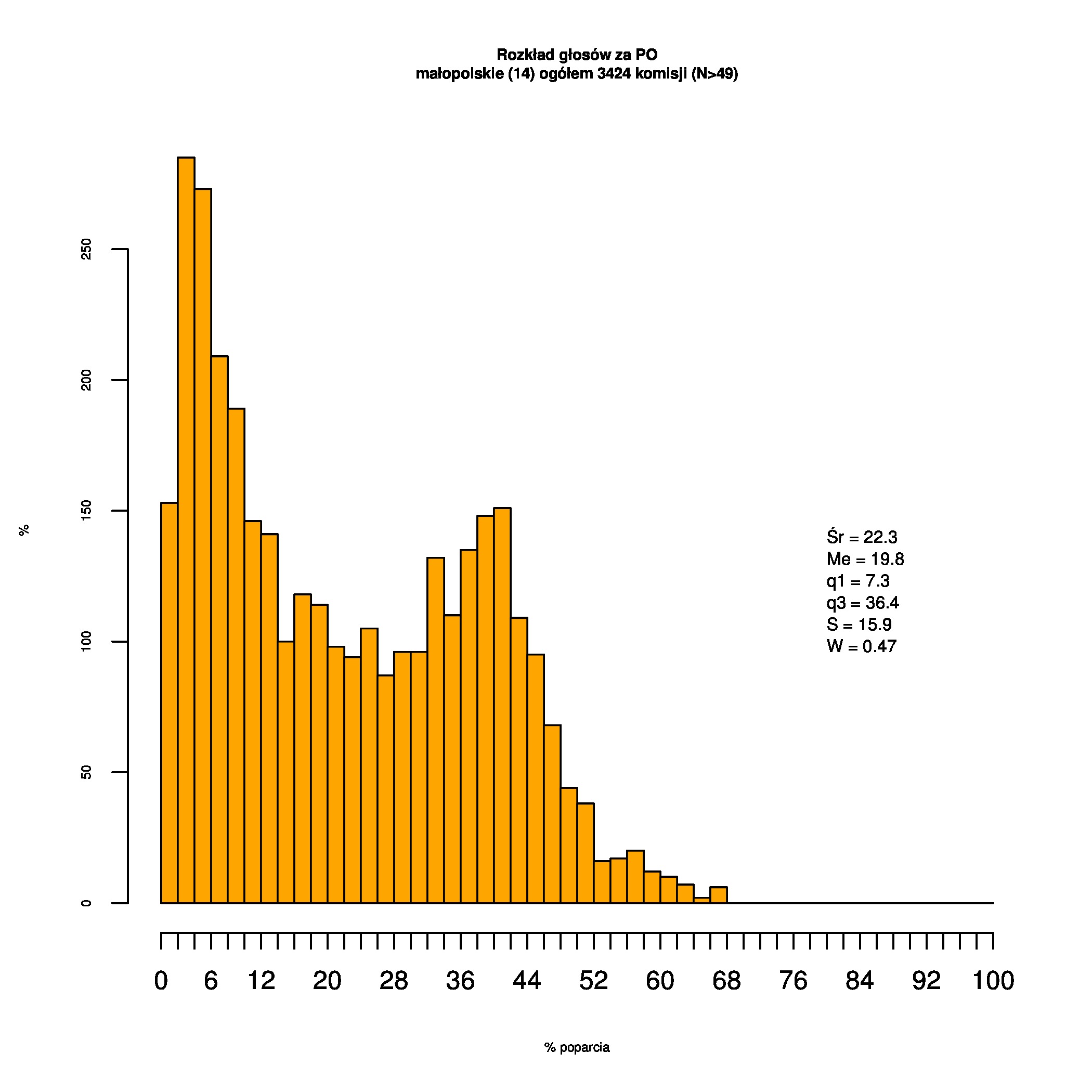
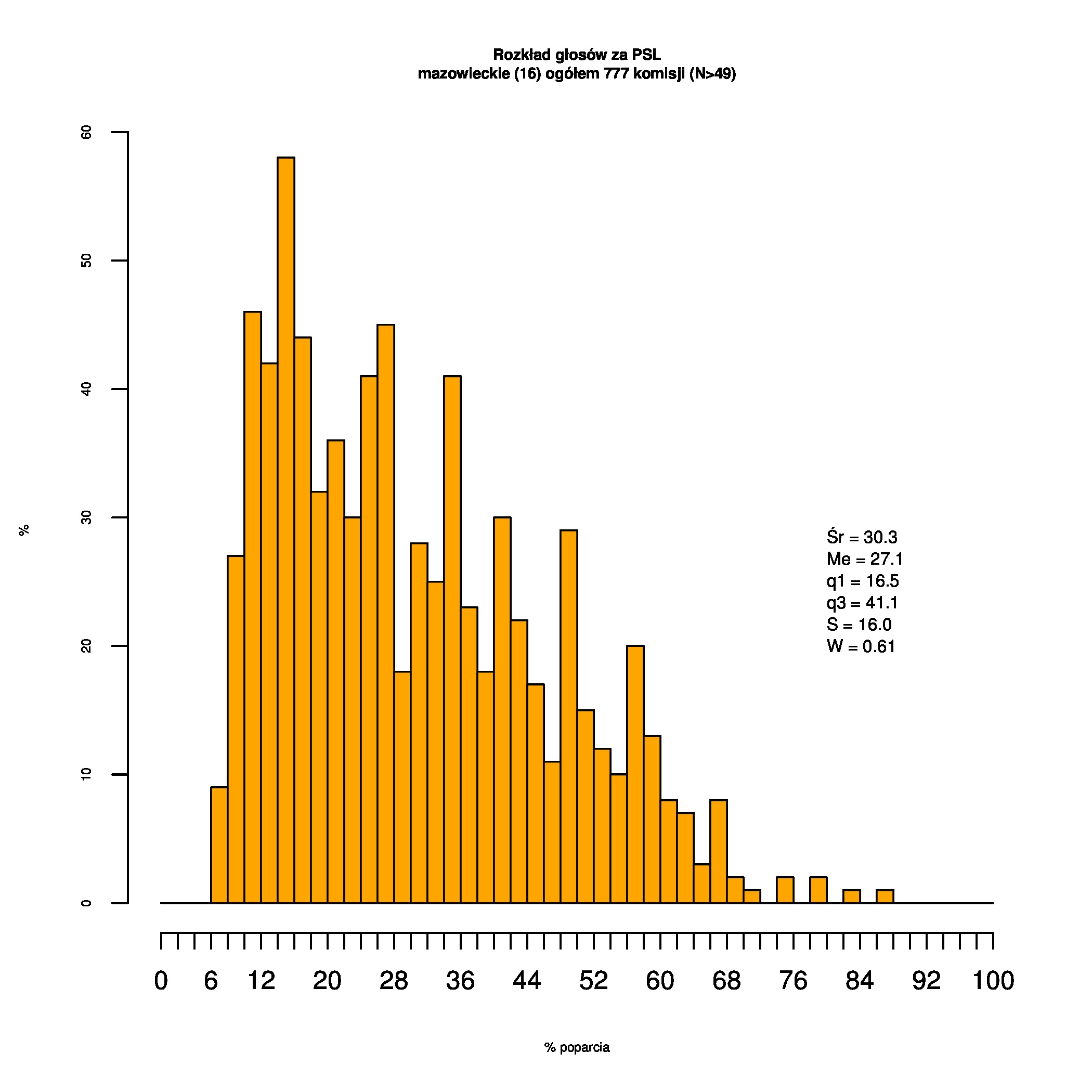
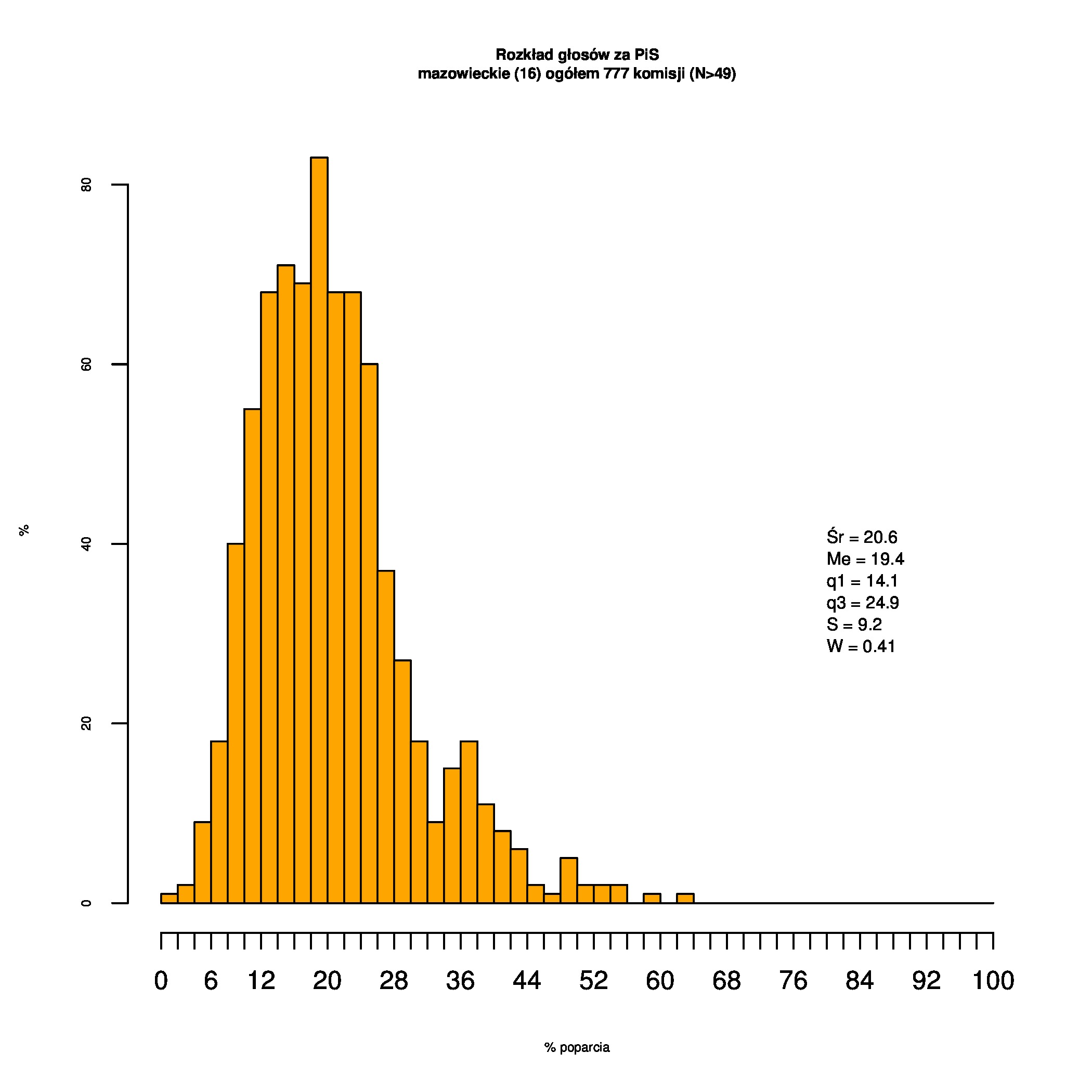
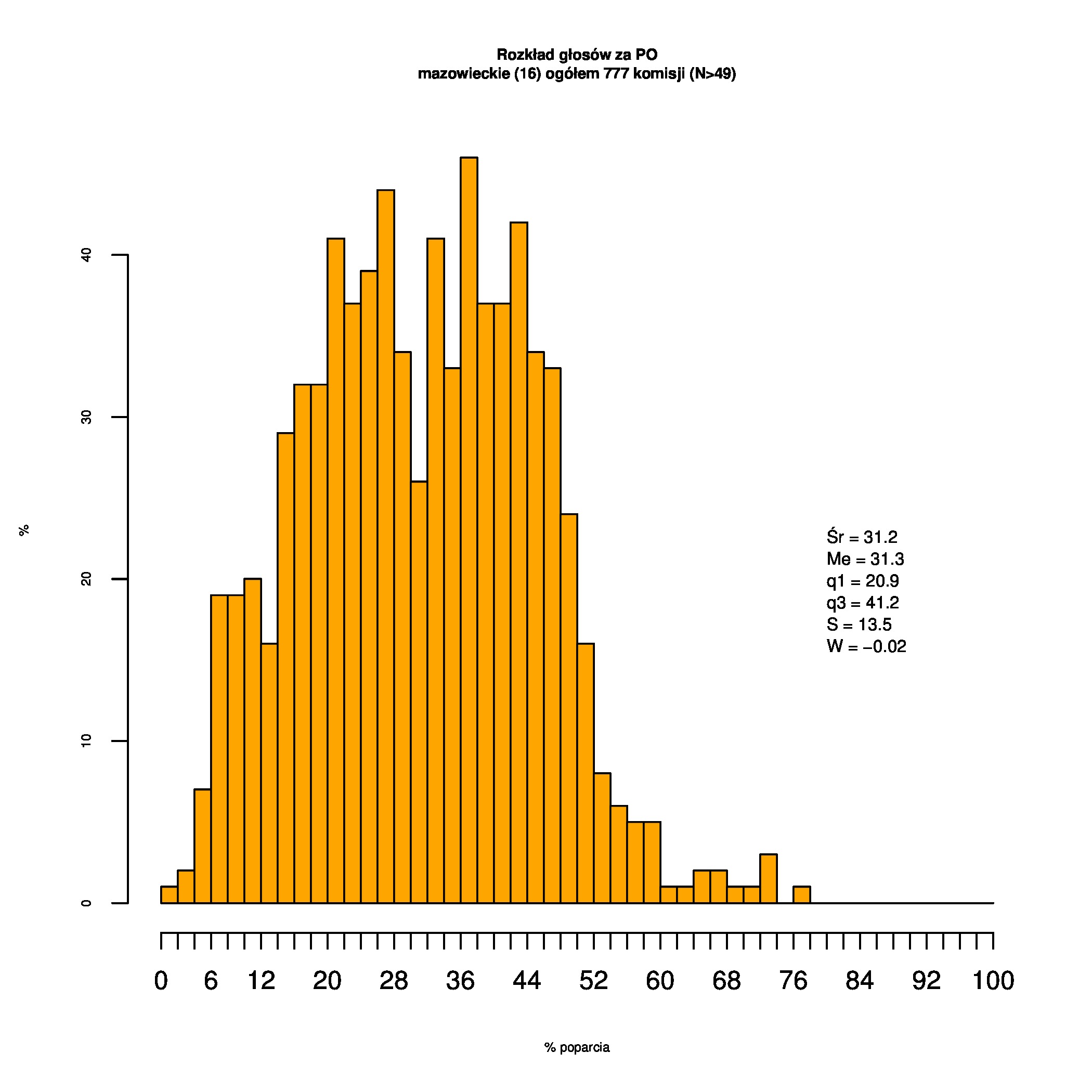
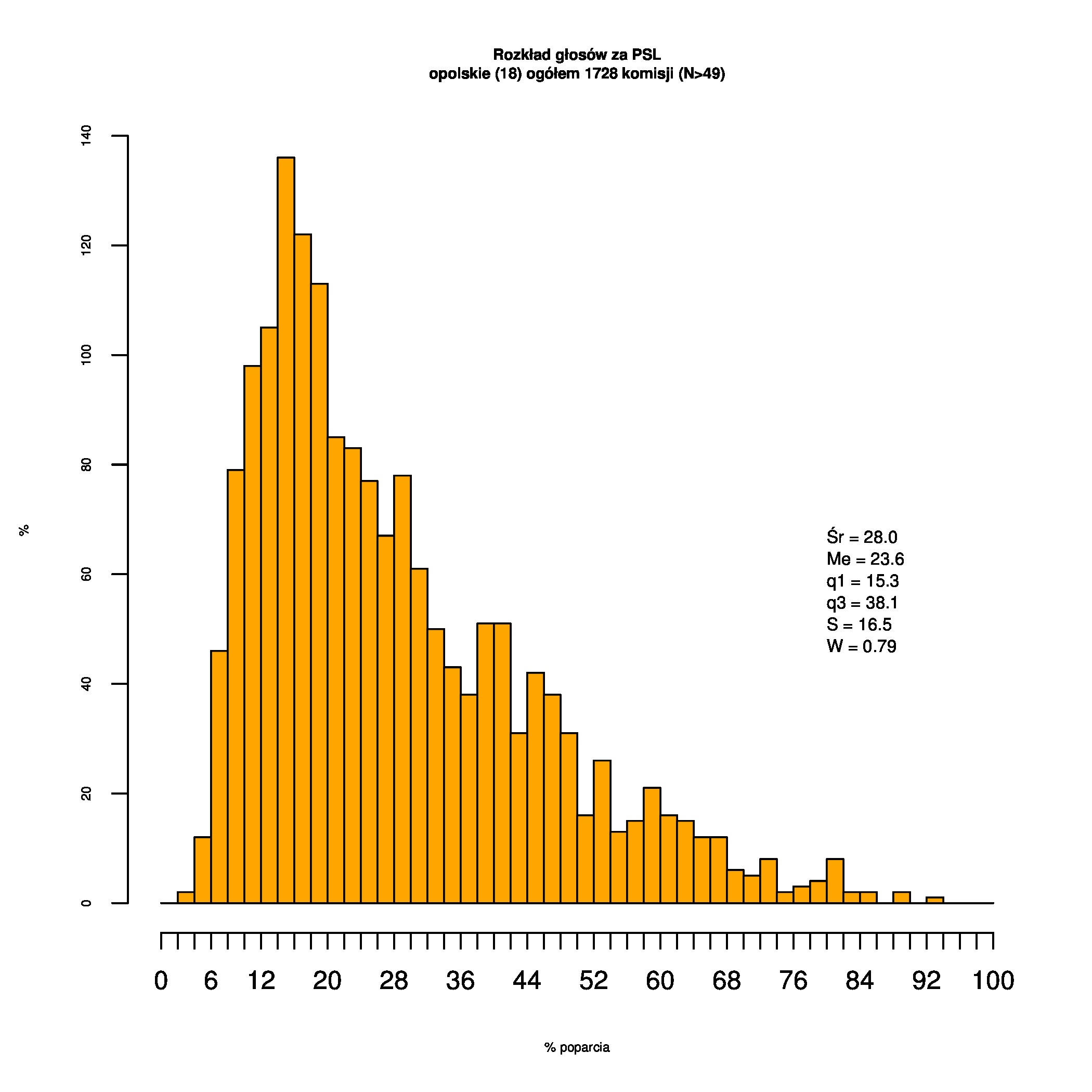
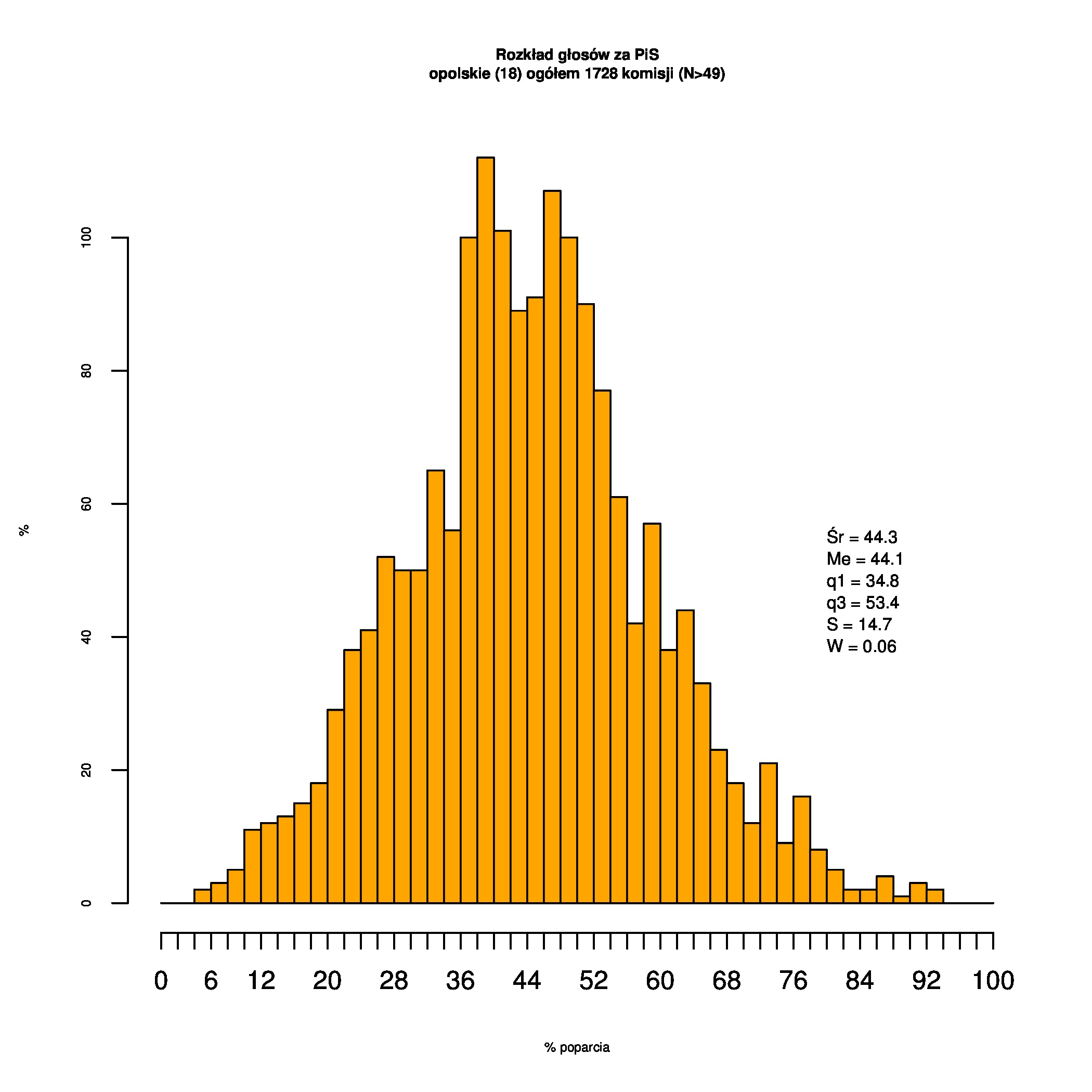
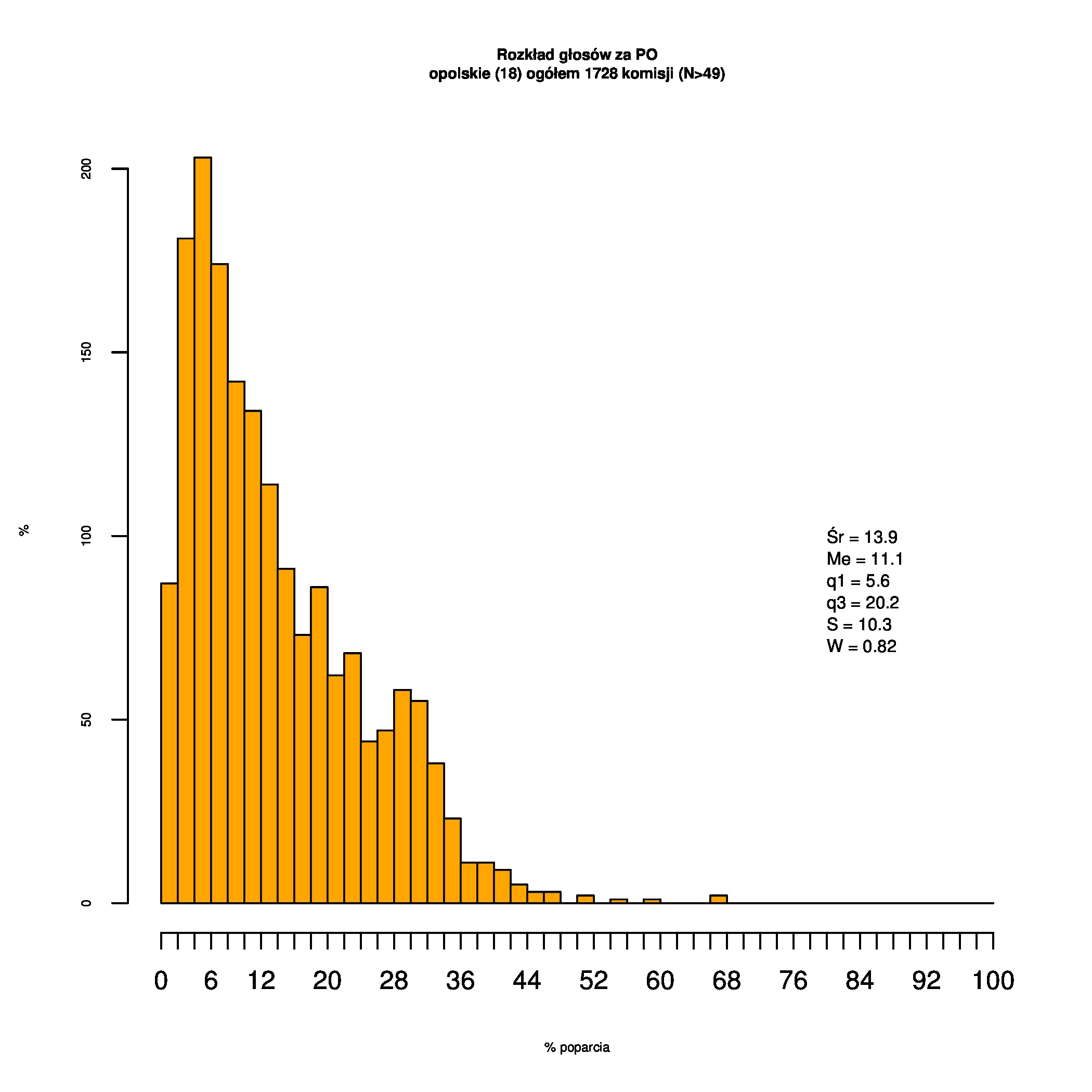
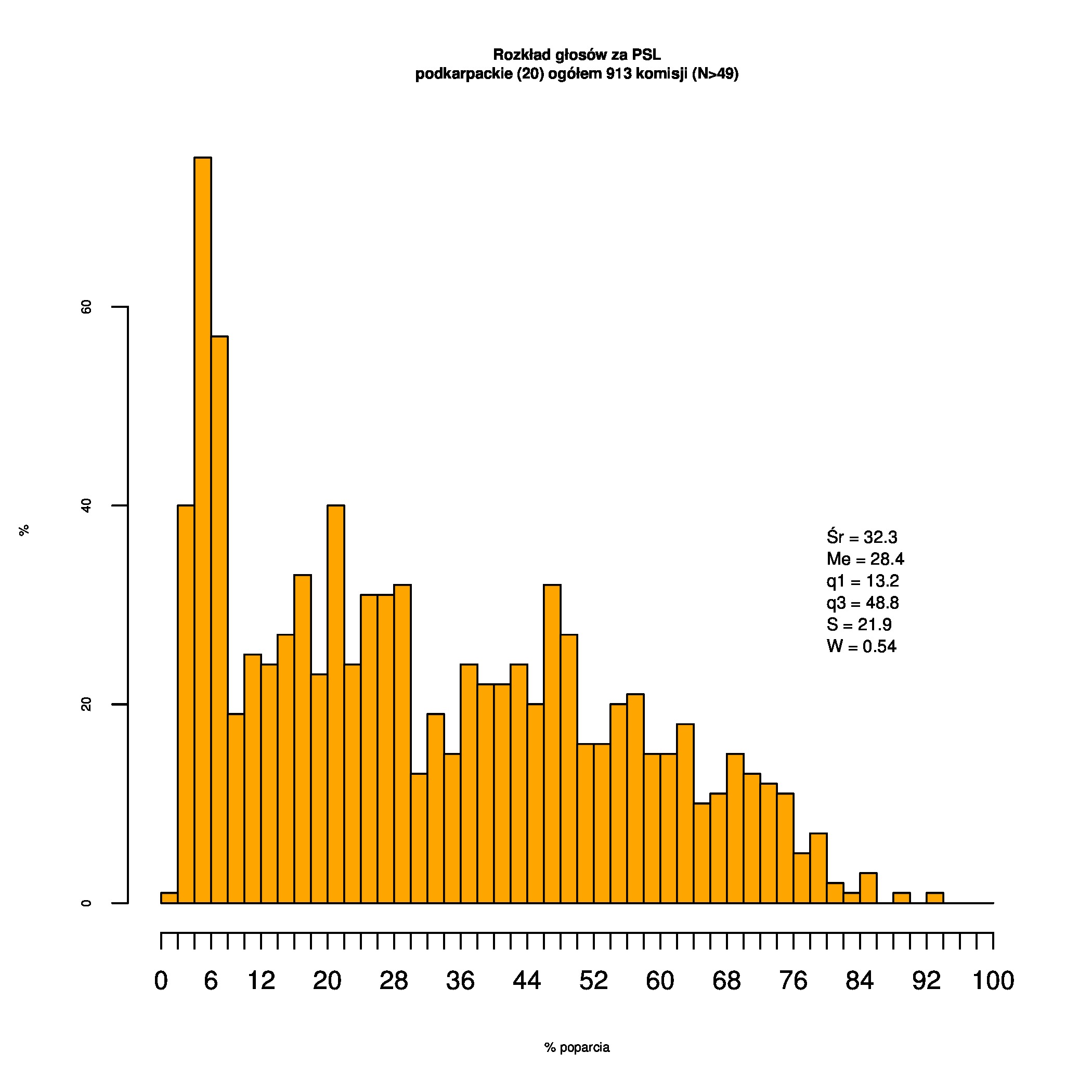
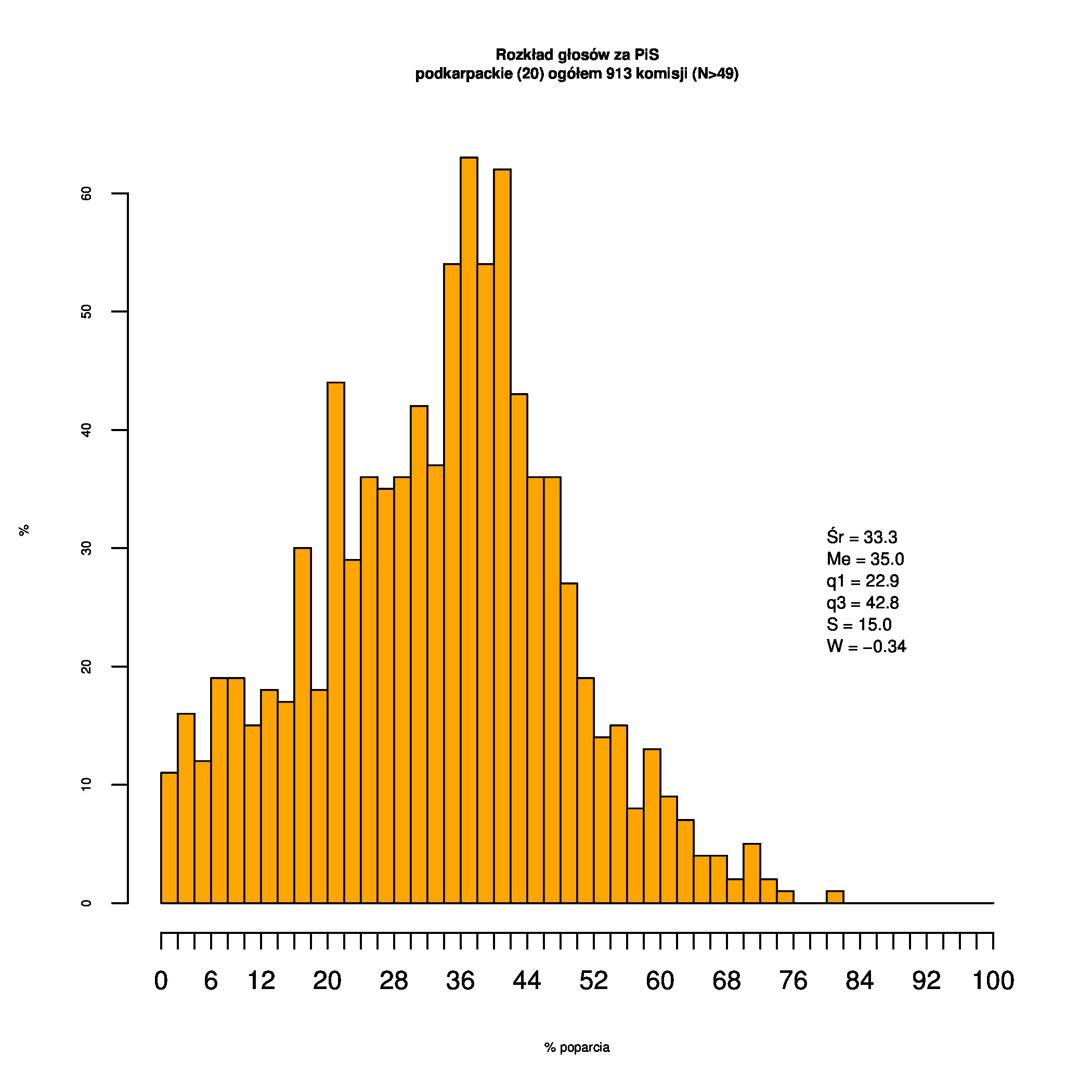
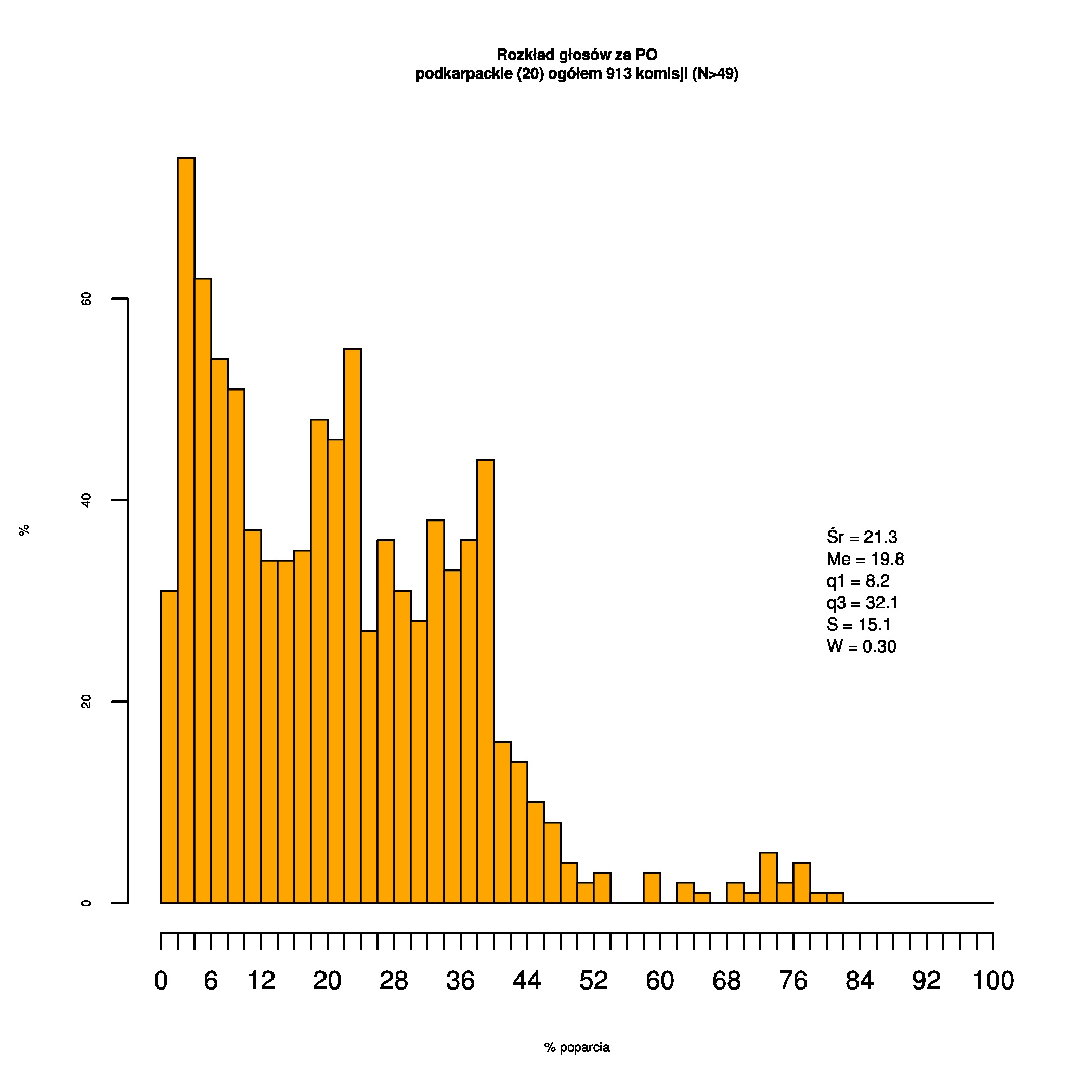
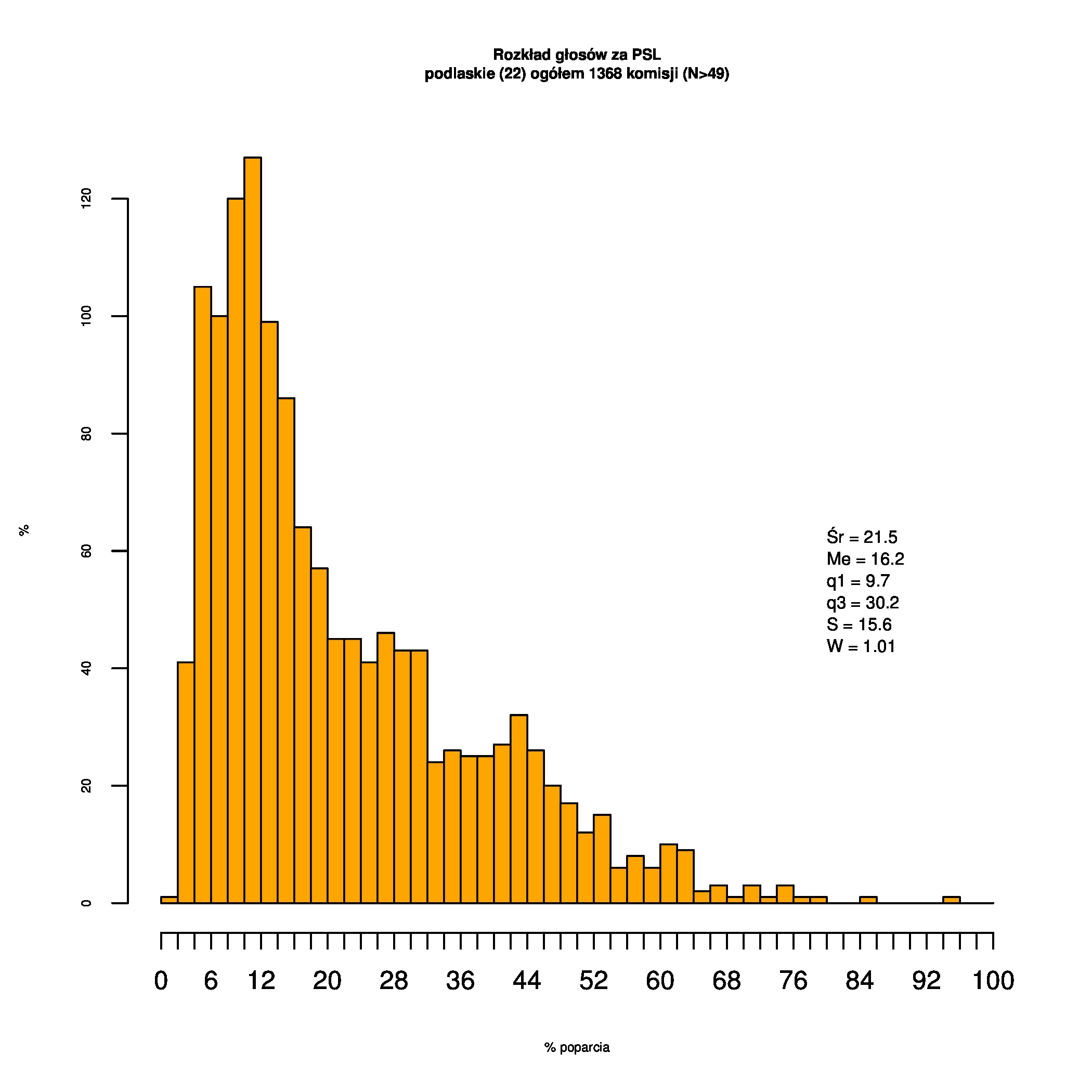
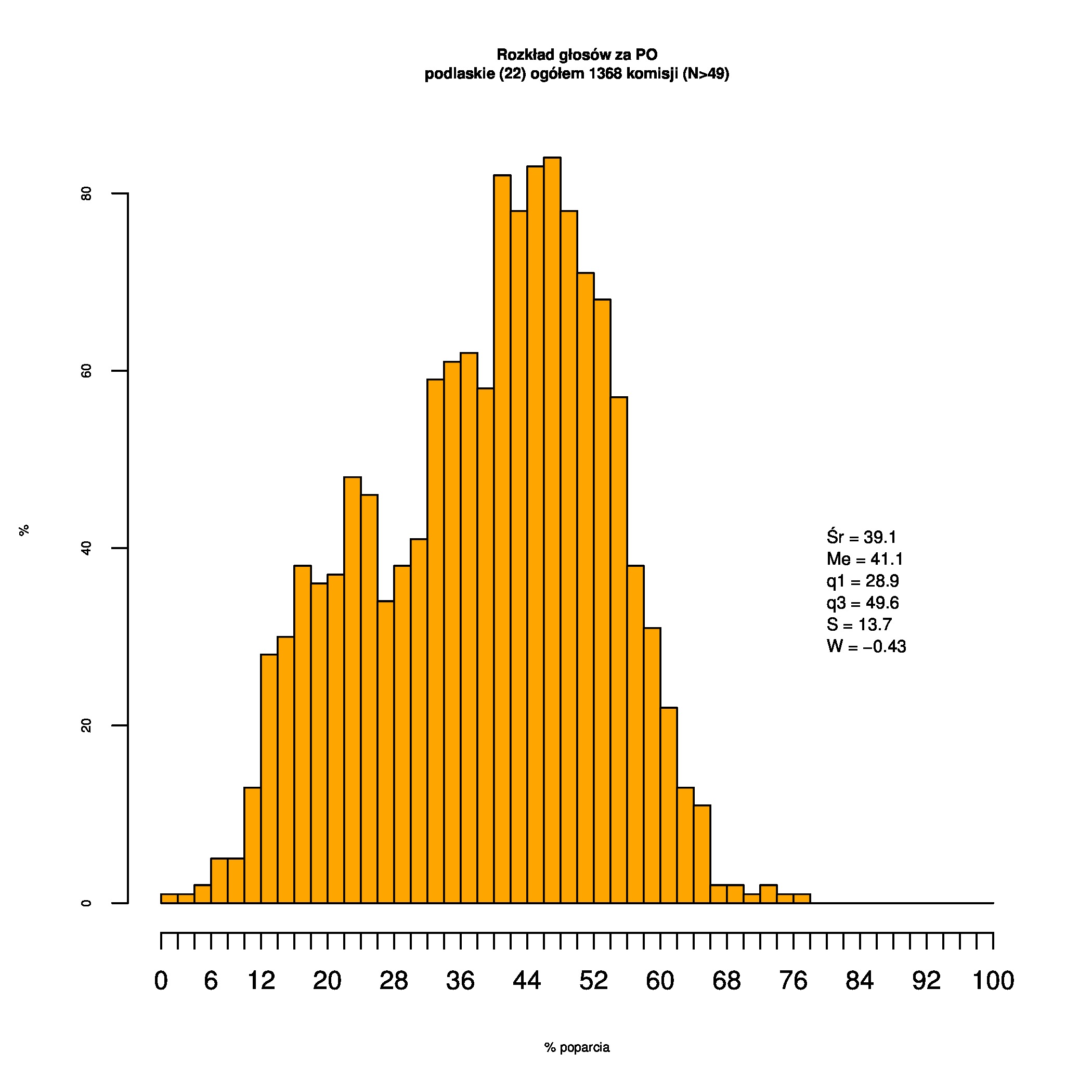
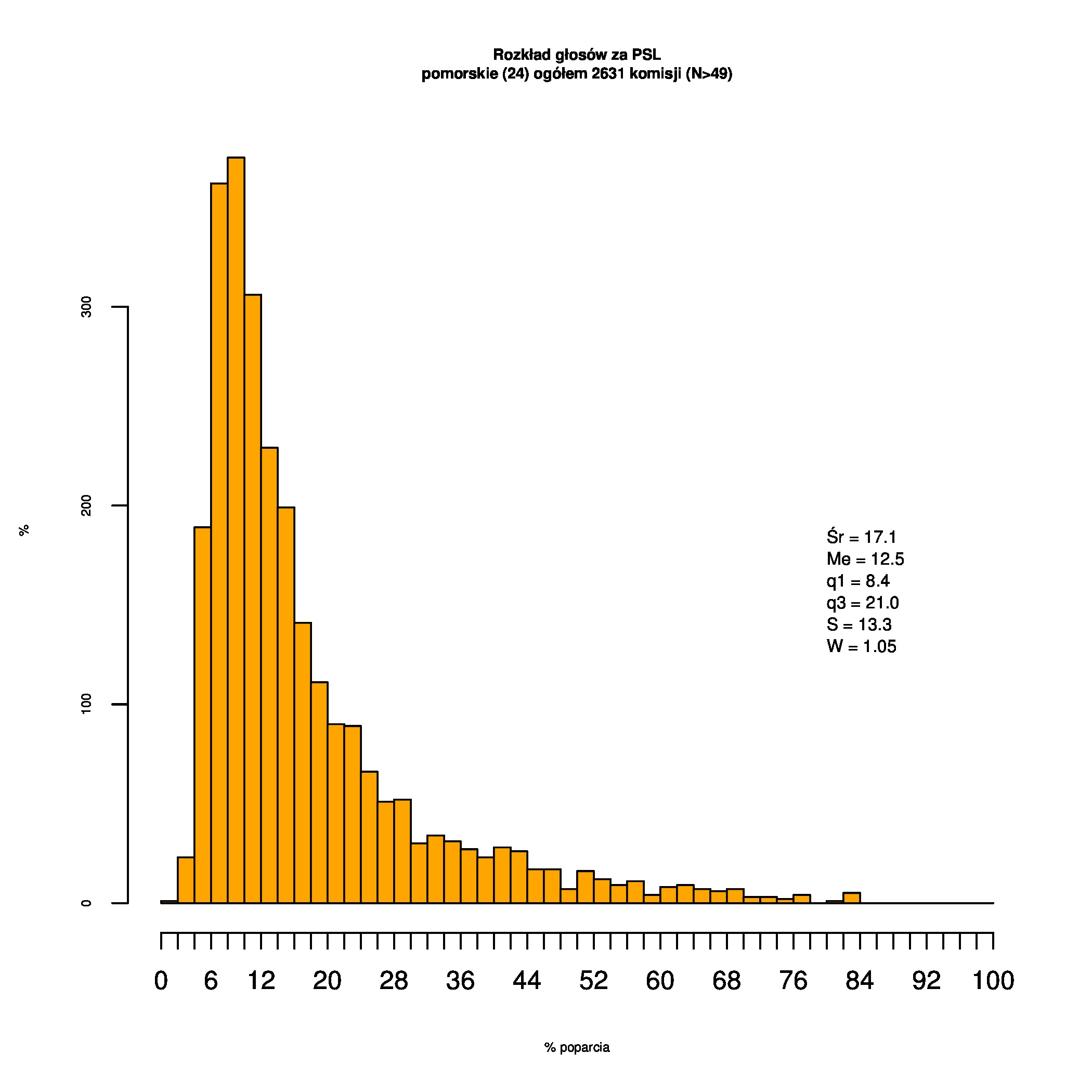
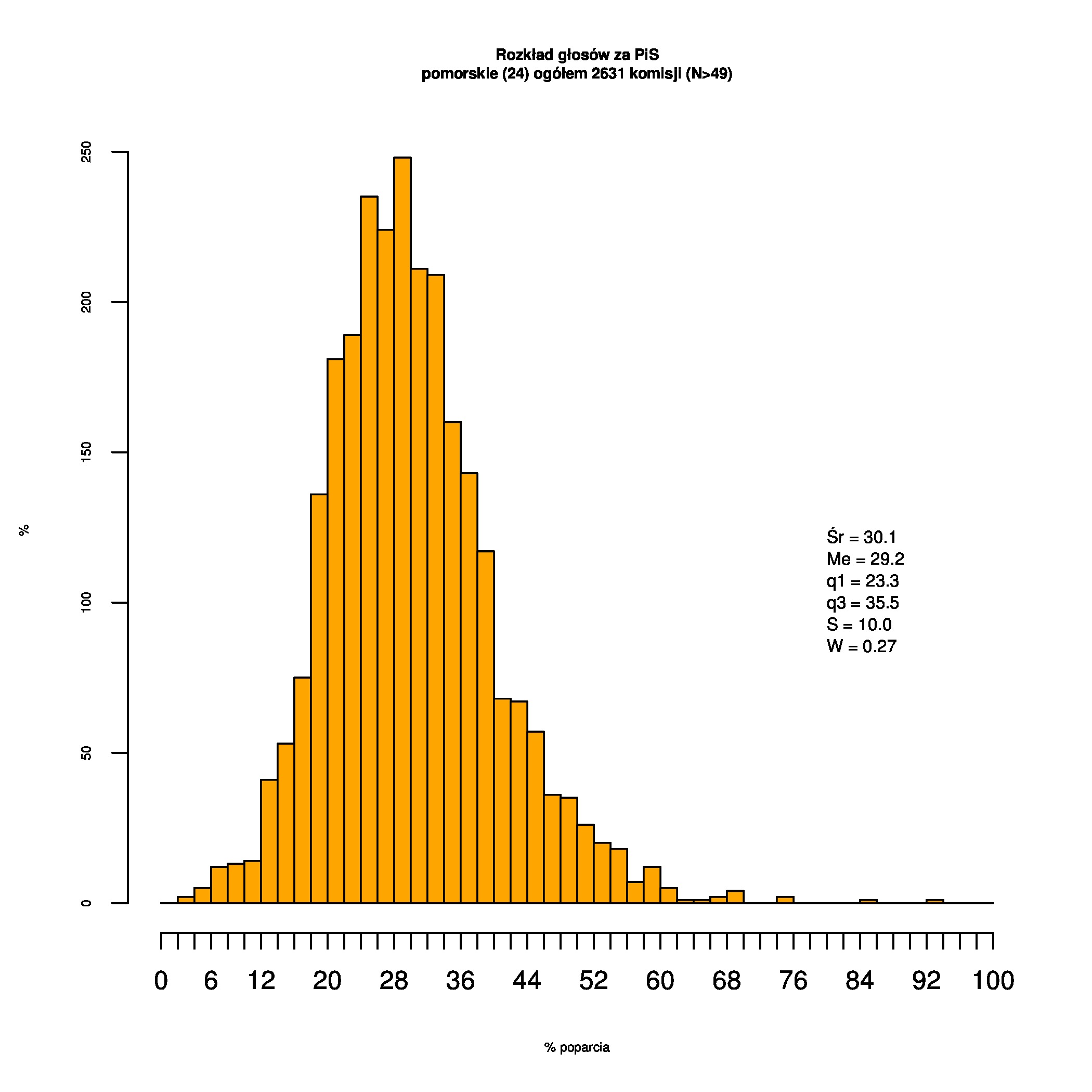
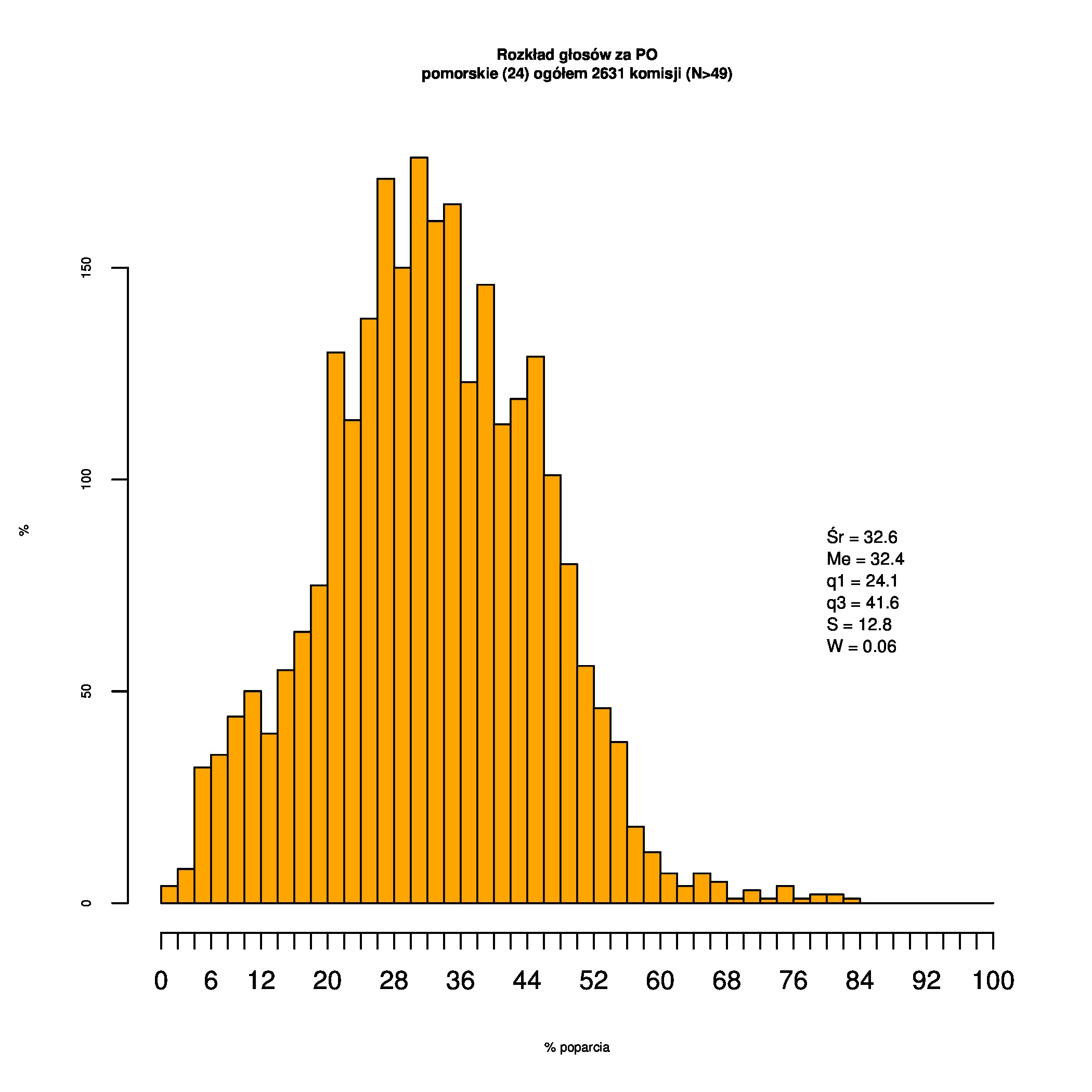
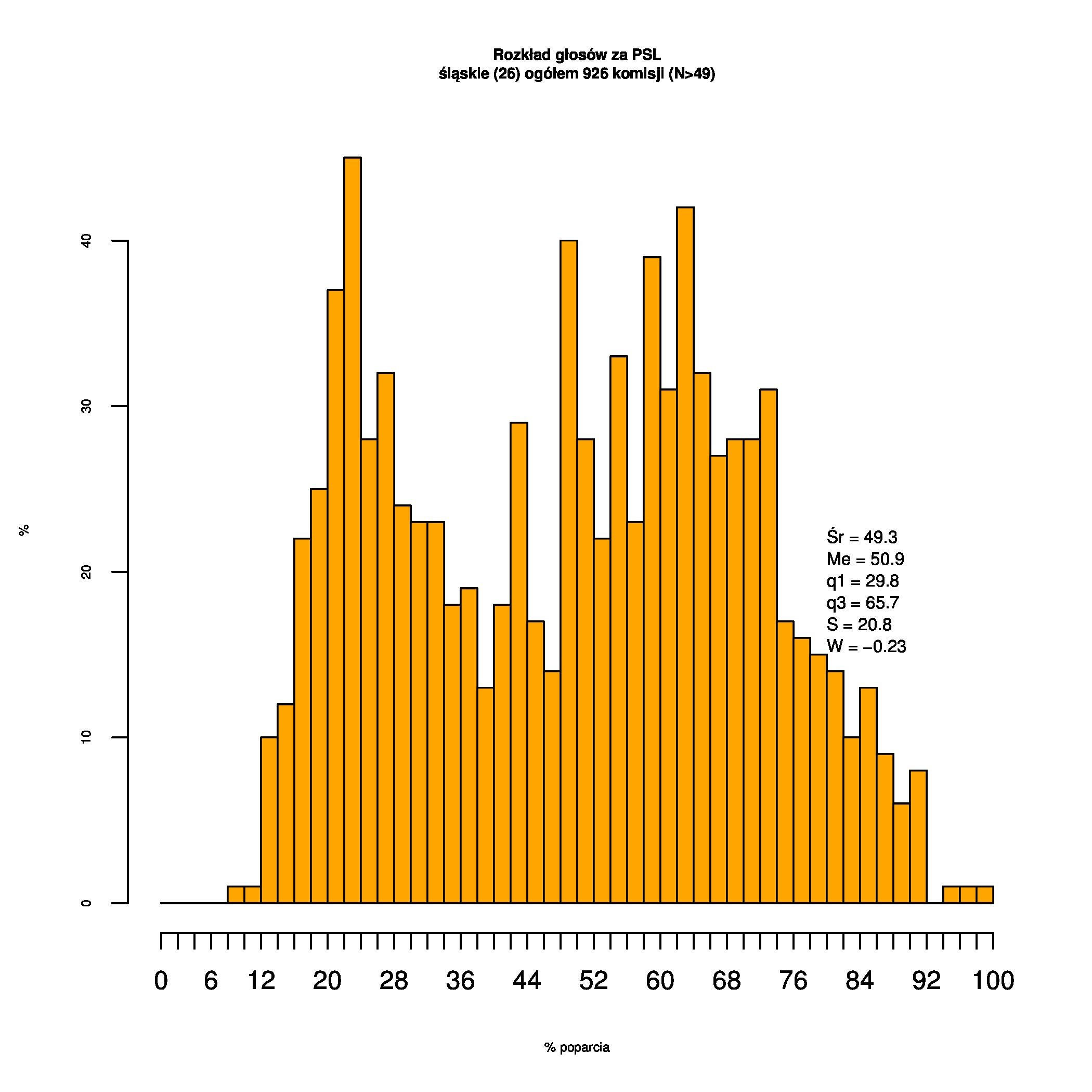
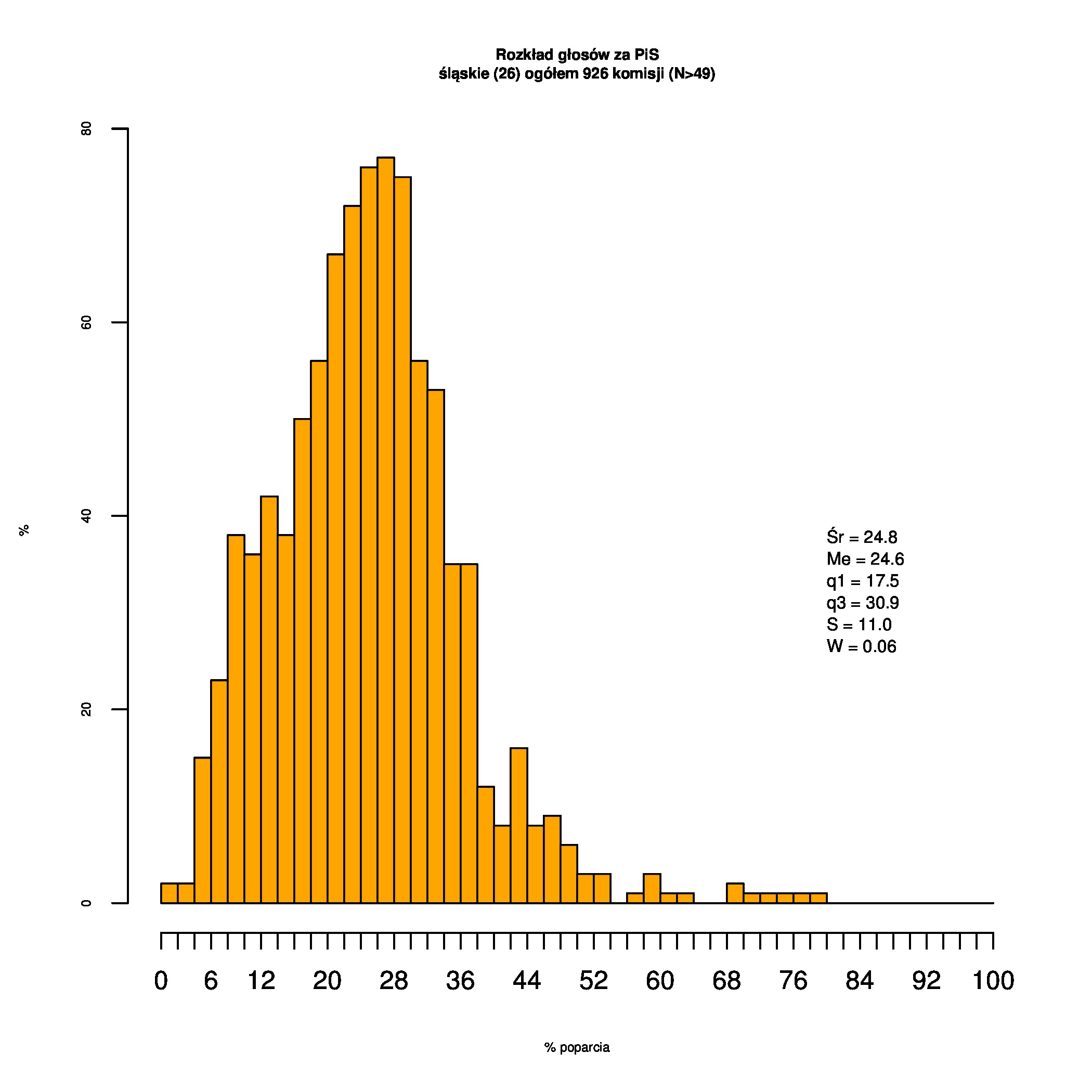
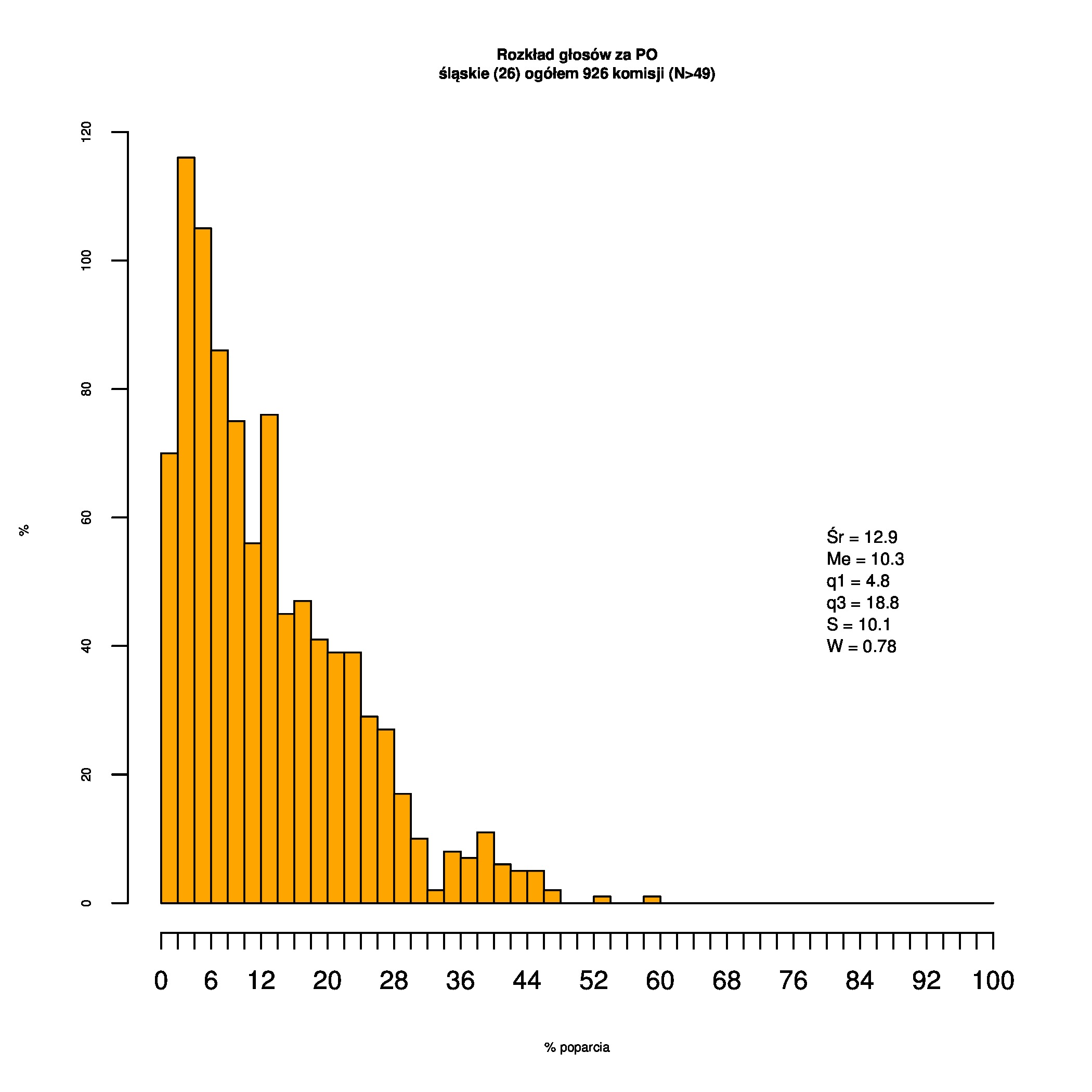
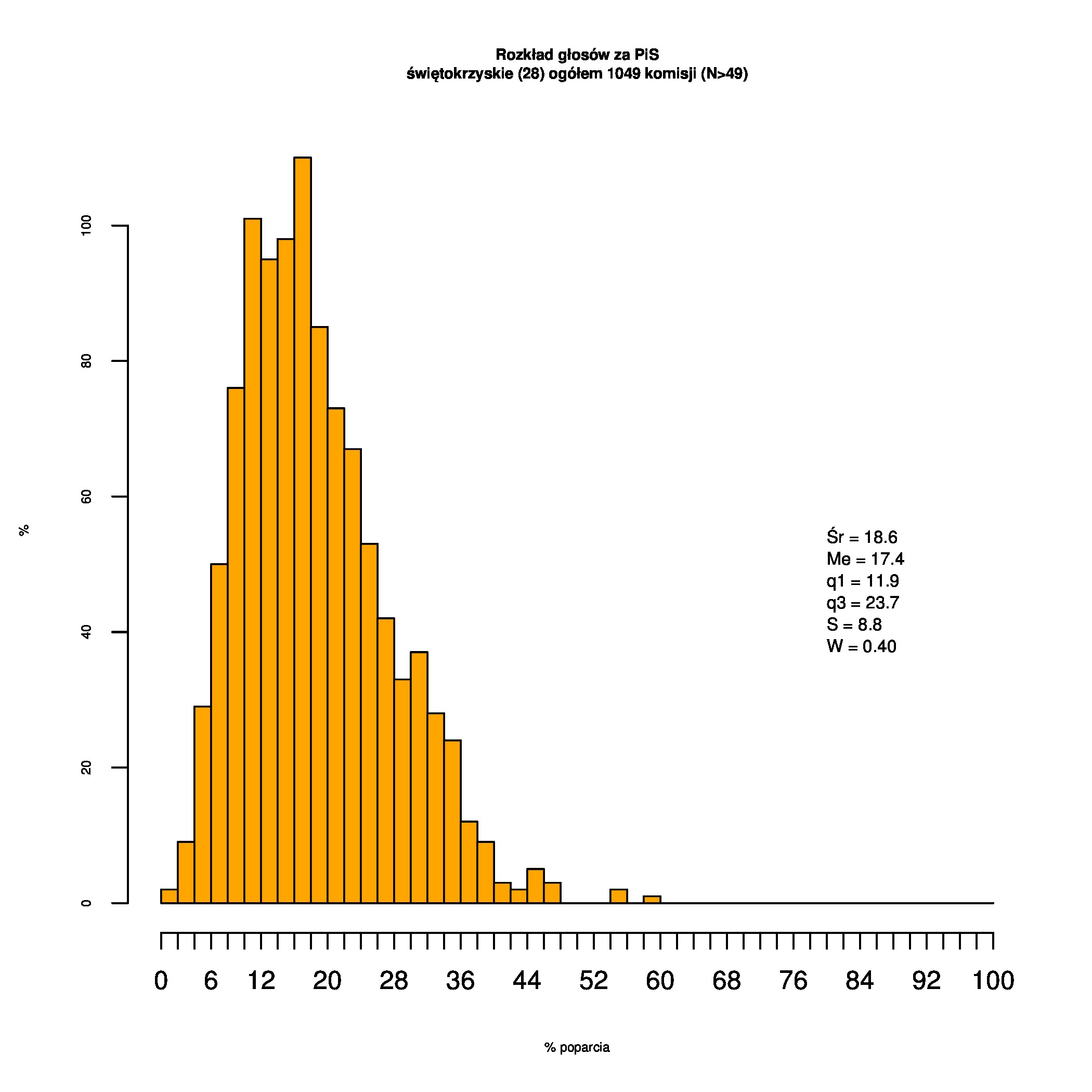
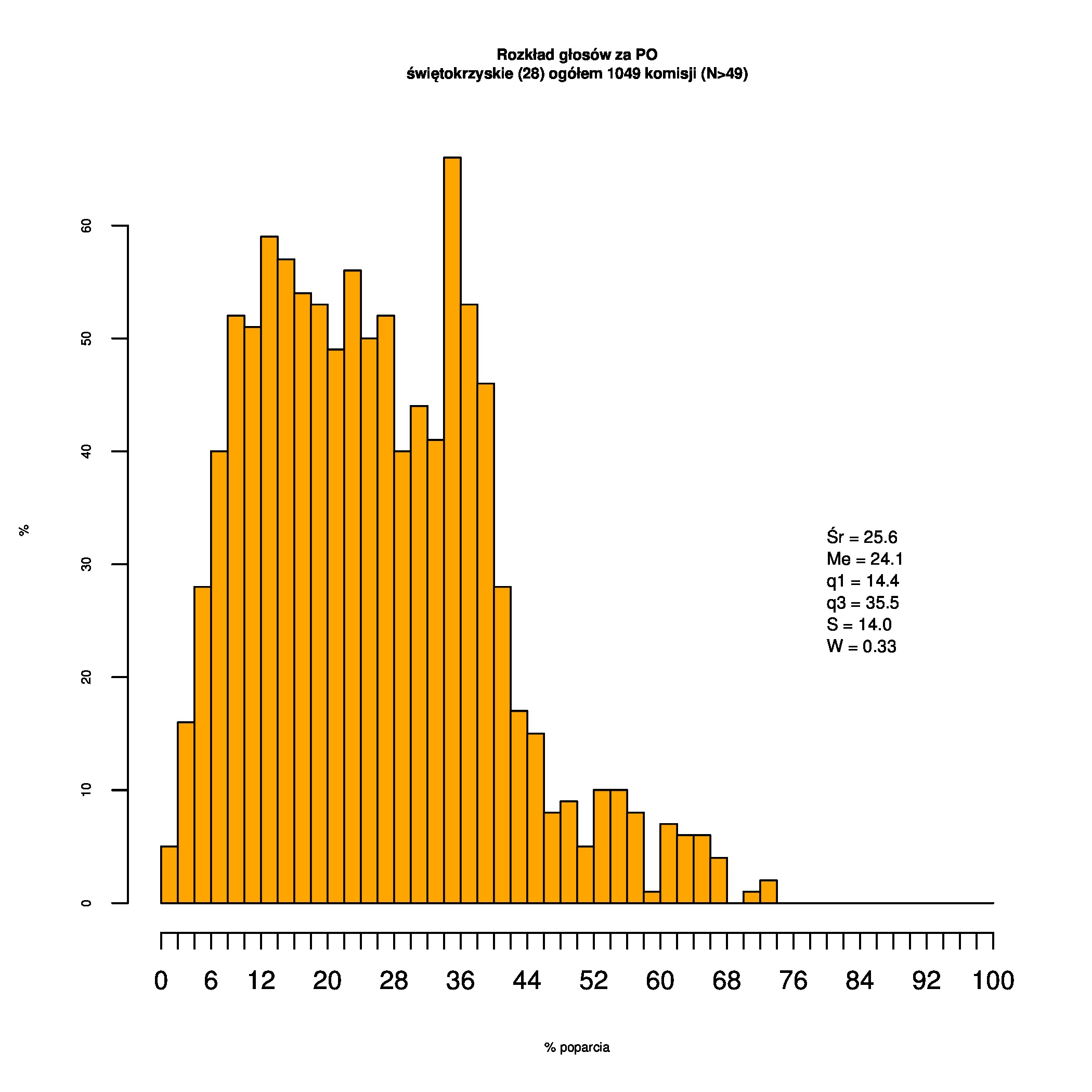
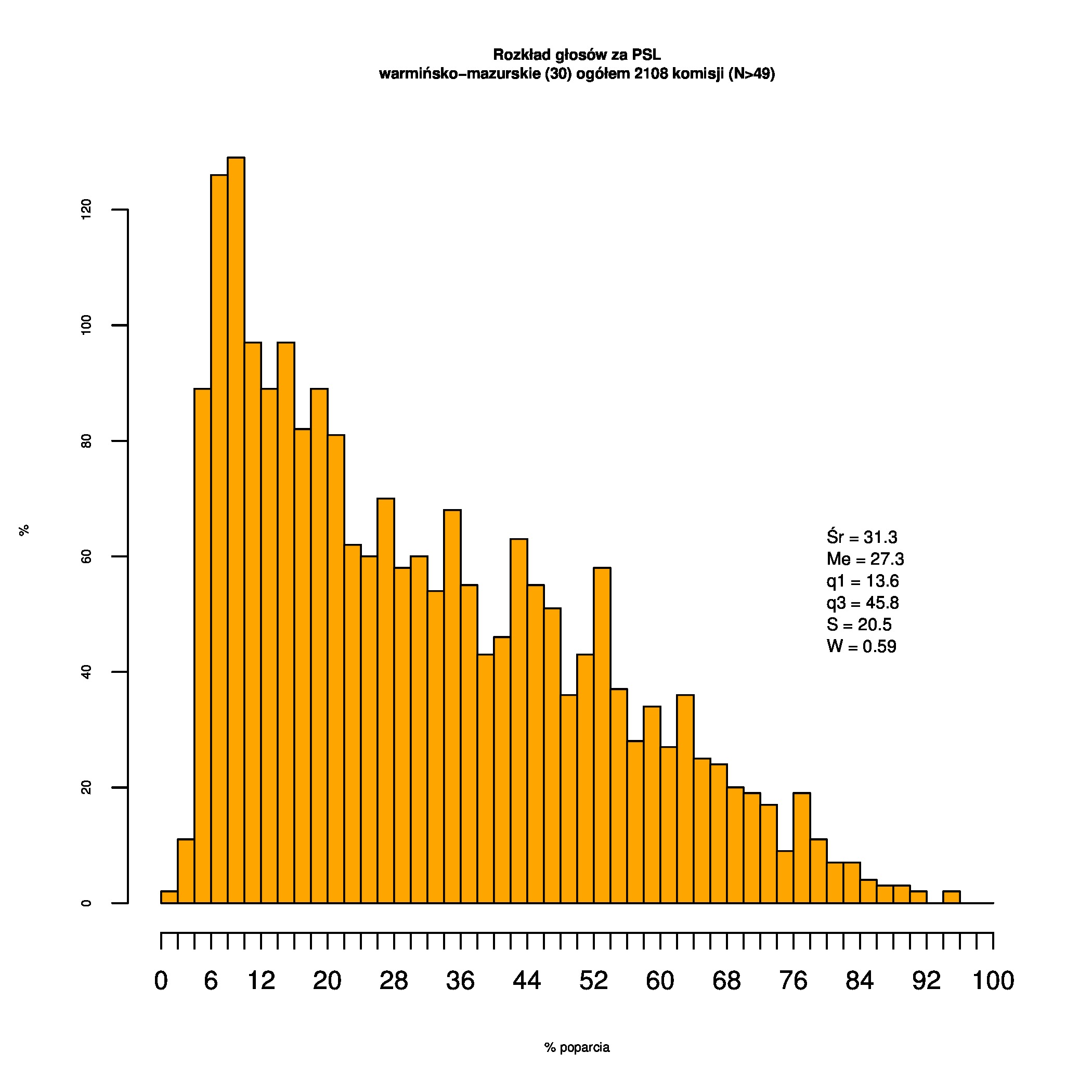
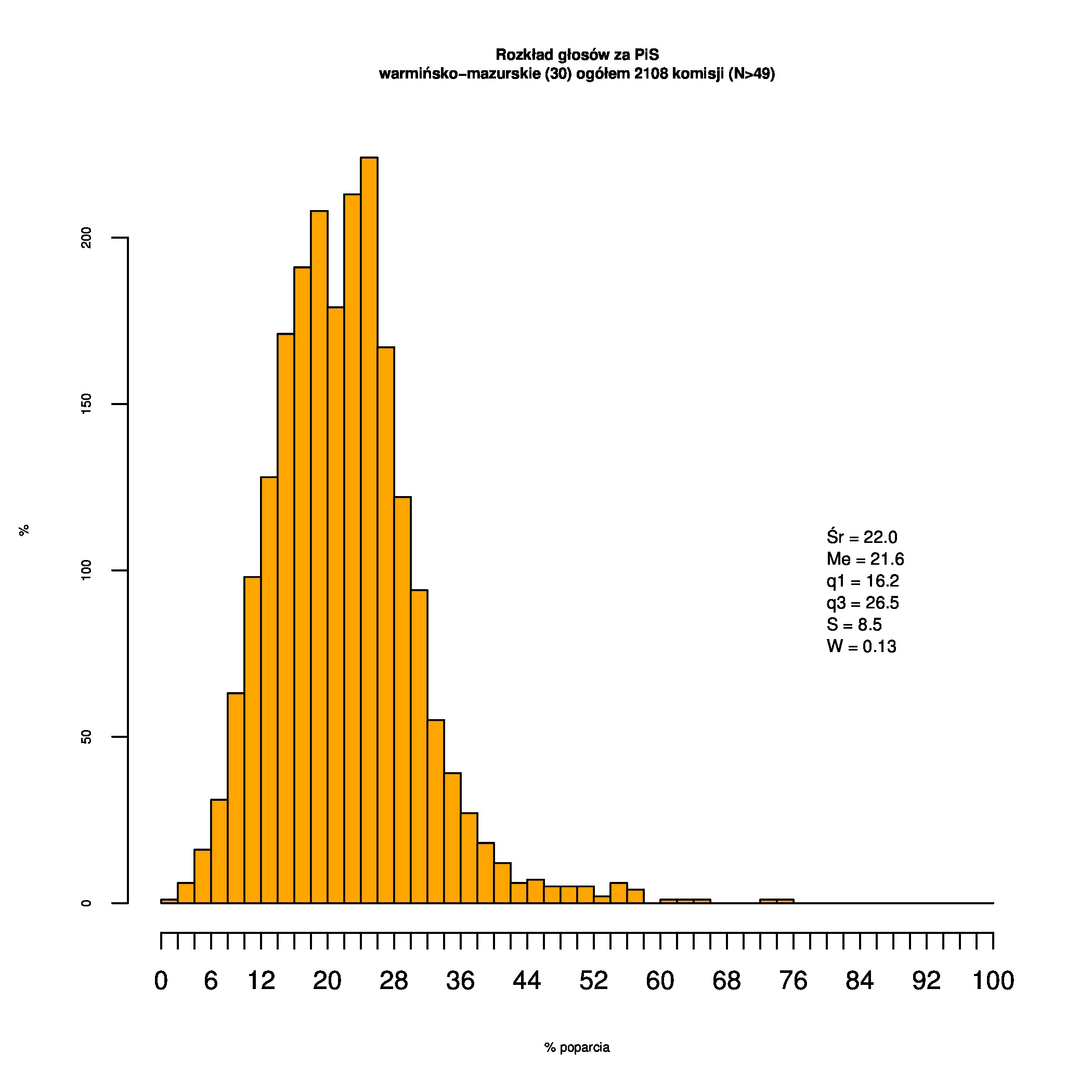
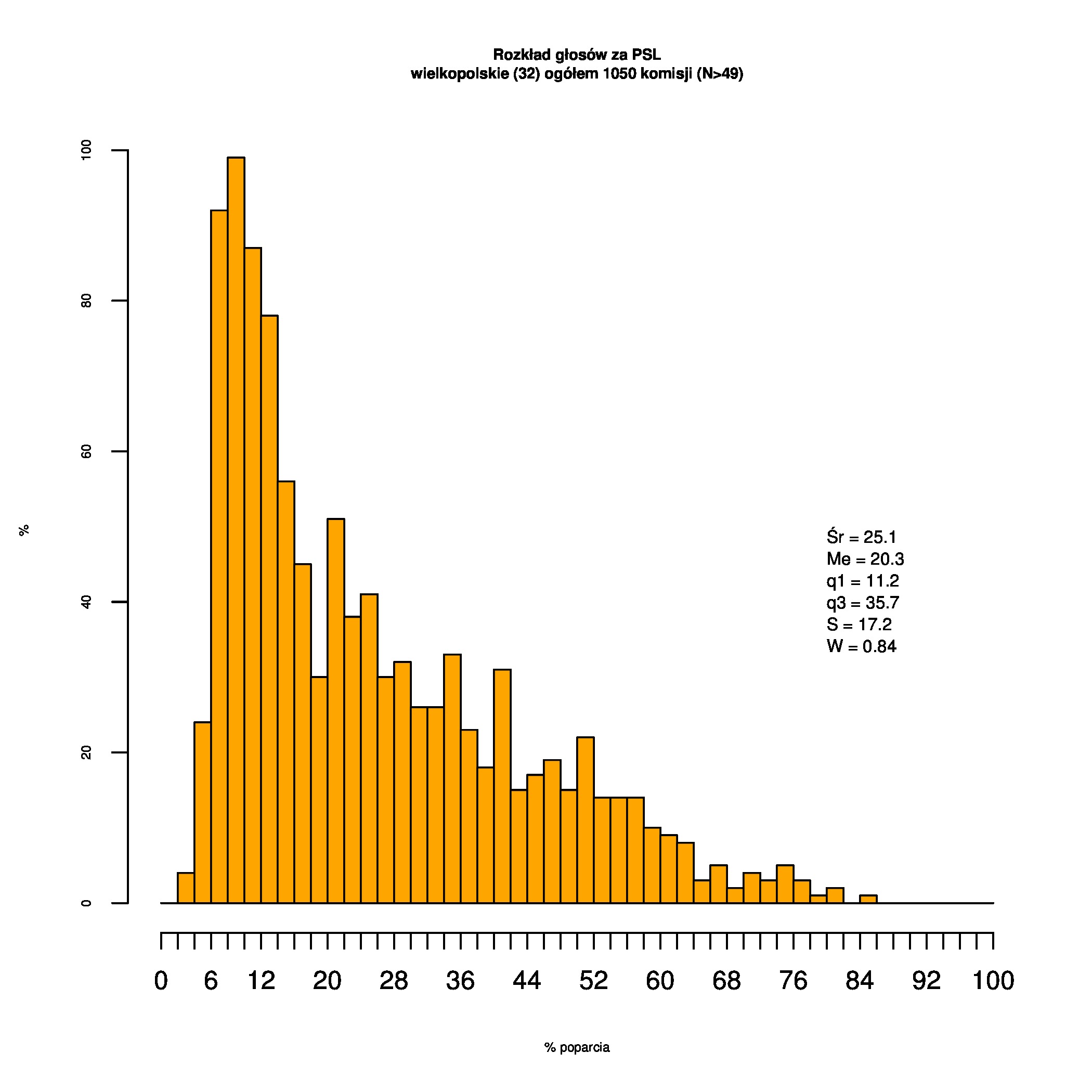
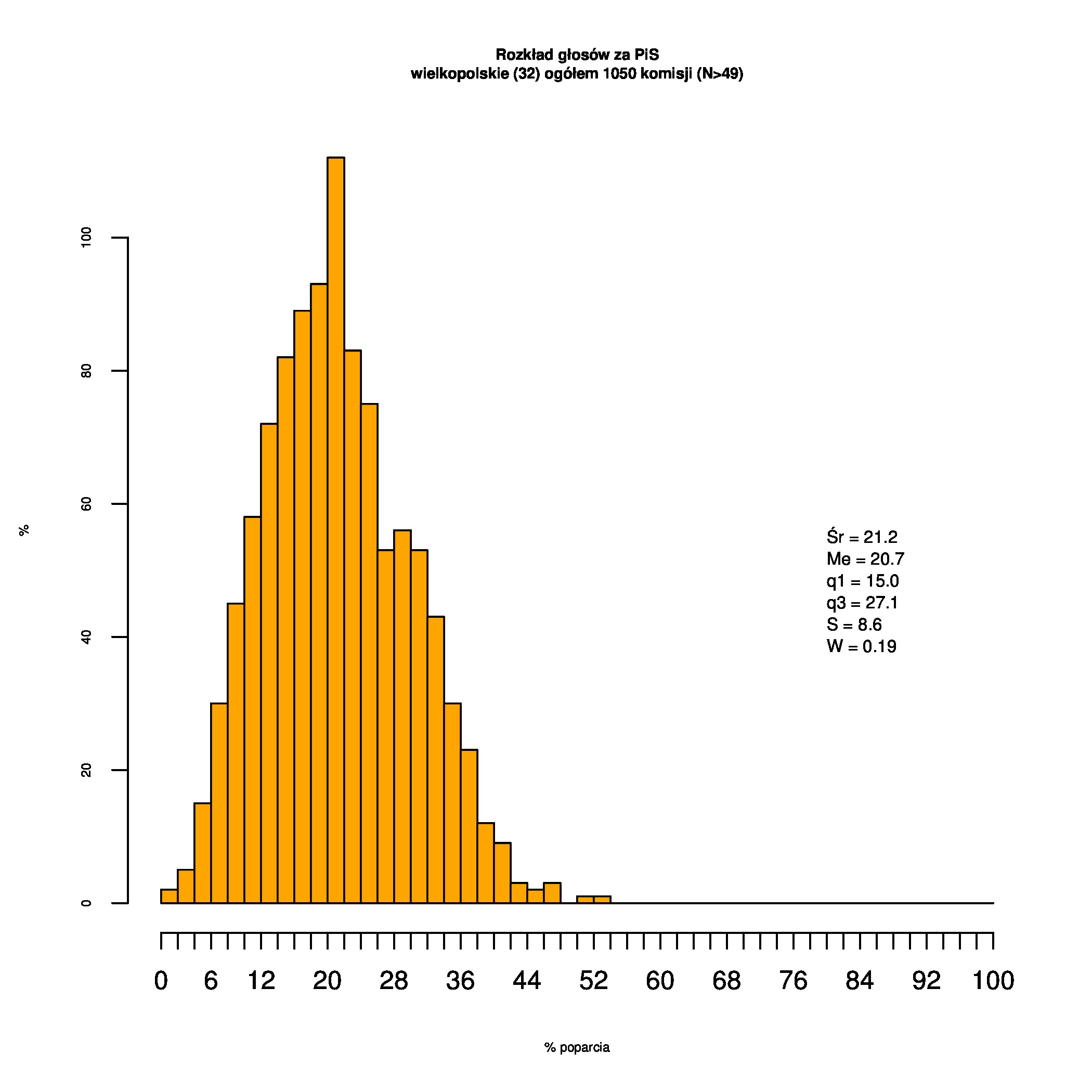
Rozkłady odsetka poparcia dla PSL/PiS/PO w wyborach samorządowych w 2014 w całej Polsce, w miastach/poza miastami oraz w poszczególnych województwach. Poniższy skrypt generuje łącznie 60 wykresów słupkowych:
#!/usr/bin/Rscript
# Skrypt wykreślna różnego rodzaju histogramy dla danych z pliku ws2014_komitety_by_komisja_T.csv
# (więcej: https://github.com/hrpunio/Data/tree/master/ws2014_pobranie_2018)
#
showVotes <- function(df, x, co, region, N, minN) {
## showVotes = wykreśla histogram dla województwa (region)
kN <- nrow(df)
sX <- summary(df[[x]], na.rm=TRUE);
sV <- sd(df[[x]], na.rm=TRUE)
## współczynnik skośności Pearsona
skewness <- 3 * (sX[["Mean"]] - sX[["Median"]])/sV
summary_label <- sprintf ("Śr = %.1f\nMe = %.1f\nq1 = %.1f\nq3 = %.1f\nS = %.1f\nW = %.2f",
sX[["Mean"]], sX[["Median"]],
sX[["1st Qu."]], sX[["3rd Qu."]], sV, skewness)
if (minN < 1) {
t <- sprintf("Rozkład głosów na %s\n%s ogółem %d komisji", co, region, kN ) }
else { t <- sprintf("Rozkład głosów za %s\n%s ogółem %d komisji (N>%d)", co, region, kN, minN ) }
h <- hist(df[[x]], breaks=kpN, freq=TRUE, col="orange", main=t,
ylab="%", xlab="% poparcia", labels=F, xaxt='n' )
axis(side=1, at=kpN, cex.axis=2, cex.lab=2)
## pozycja tekstu zawierającego statystyki opisowe
posX <- .5 * max(h$counts)
text(80, posX, summary_label, cex=1.4, adj=c(0,1))
}
## Wczytanie danych; obliczenie podst. statystyk:
komisje <- read.csv("ws2014_komitety_by_komisja_T.csv",
sep = ';', header=T, na.string="NA");
komisje$ogn <- komisje$glosyNiewazne / (komisje$glosy
+ komisje$glosyNiewazne) * 100;
summary(komisje$PSL); summary(komisje$PiS); summary(komisje$PO);
fivenum(komisje$PSLp); fivenum(komisje$PiSp); fivenum(komisje$POp);
## ## ###
par(ps=6,cex=1,cex.axis=1,cex.lab=1,cex.main=1.2)
kpN <- seq(0, 100, by=2);
kpX <- c(0, 10,20,30,40,50,60,70,80,90, 100);
kN <- nrow(komisje)
region <- "Polska"
minTurnout <- 0
## cała Polska:
showVotes(komisje, "PSLp", "PSL", region, kN, minTurnout);
showVotes(komisje, "PiSp", "PiS", region, kN, minTurnout);
showVotes(komisje, "POp", "PO", region, kN, minTurnout);
## Cała Polska (bez małych komisji):
## ( późniejszych analizach pomijane są małe komisje)
minTurnout <- 49
komisje <- subset (komisje, glosyLK > minTurnout);
kN <- nrow(komisje)
showVotes(komisje, "PSLp", "PSL", region, kN, minTurnout);
showVotes(komisje, "PiSp", "PiS", region, kN, minTurnout);
showVotes(komisje, "POp", "PO", region, kN, minTurnout);
## Typ gminy U/R (U=gmina miejska ; R=inna niż miejska)
komisjeW <- subset (komisje, typ == "U");
kN <- nrow(komisjeW)
region <- "Polska/g.miejskie"
showVotes(komisjeW, "PSLp", "PSL", region, kN, minTurnout);
showVotes(komisjeW, "PiSp", "PiS", region, kN, minTurnout);
showVotes(komisjeW, "POp", "PO", region, kN, minTurnout);
komisjeW <- subset (komisje, typ == "R");
kN <- nrow(komisjeW)
region <- "Polska/g.niemiejskie"
showVotes(komisjeW, "PSLp", "PSL", region, kN, minTurnout);
showVotes(komisjeW, "PiSp", "PiS", region, kN, minTurnout);
showVotes(komisjeW, "POp", "PO", region, kN, minTurnout);
## woj = dwucyfrowy kod teryt województwa:
komisje$woj <- substr(komisje$teryt, start=1, stop=2)
cN <- c("dolnośląskie", "dolnośląskie", "kujawsko-pomorskie",
"lubelskie", "lubuskie", "łódzkie", "małopolskie", "mazowieckie",
"opolskie", "podkarpackie", "podlaskie", "pomorskie", "śląskie",
"świętokrzyskie", "warmińsko-mazurskie", "wielkopolskie",
"zachodniopomorskie");
cW <- c("02", "04", "06", "08", "10", "12", "14", "16", "18",
"20", "22", "24", "26", "28", "30", "32");
## wszystkie województwa po kolei:
for (w in 1:16) {
wojS <- cW[w]
###region <- cN[w];
region <- sprintf ("%s (%s)", cN[w], wojS);
komisjeW <- subset (komisje, woj == wojS); ##
showVotes(komisjeW, "PSLp", "PSL", region, kN, minTurnout);
showVotes(komisjeW, "PiSp", "PiS", region, kN, minTurnout);
showVotes(komisjeW, "POp", "PO", region, kN, minTurnout);
}
## ## koniec
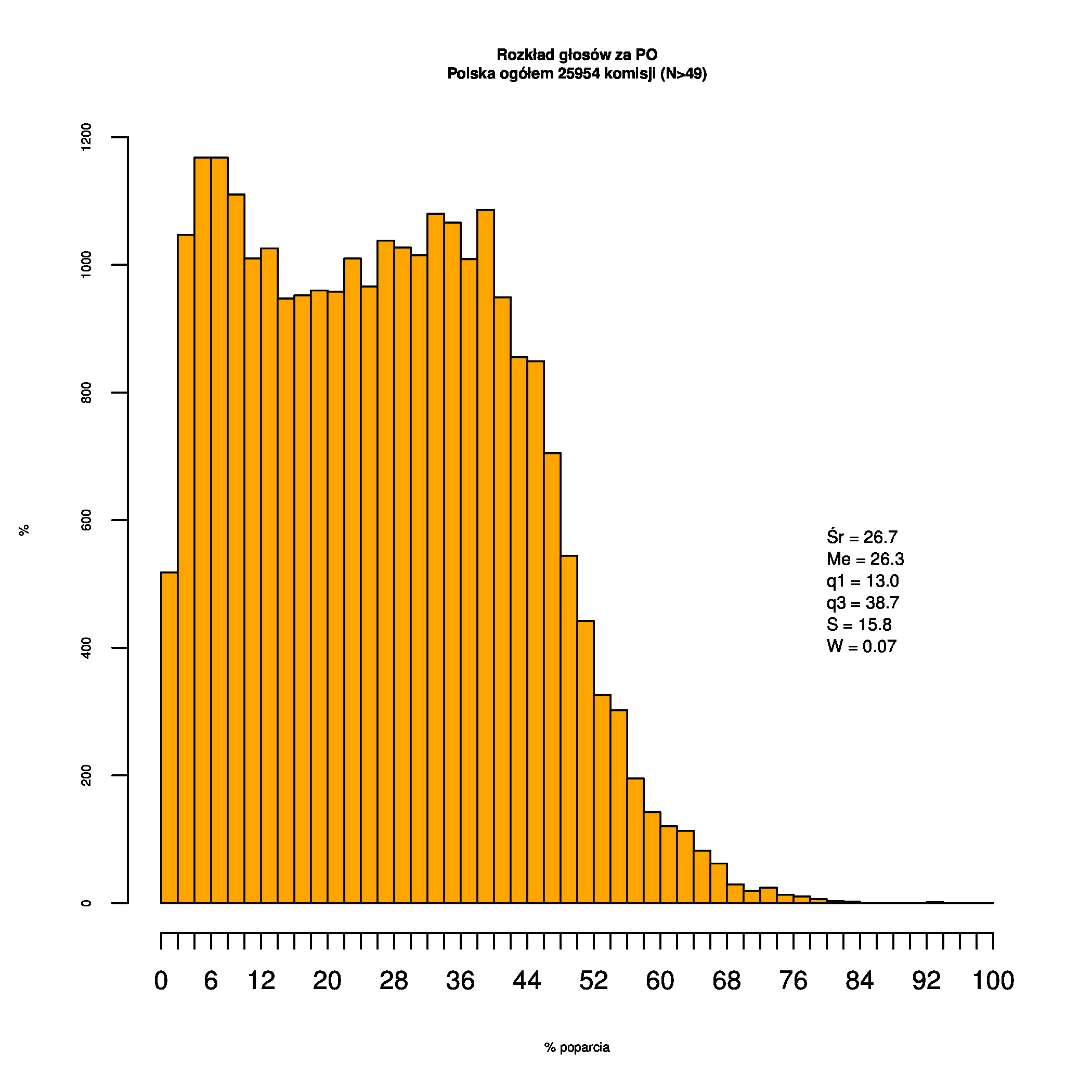
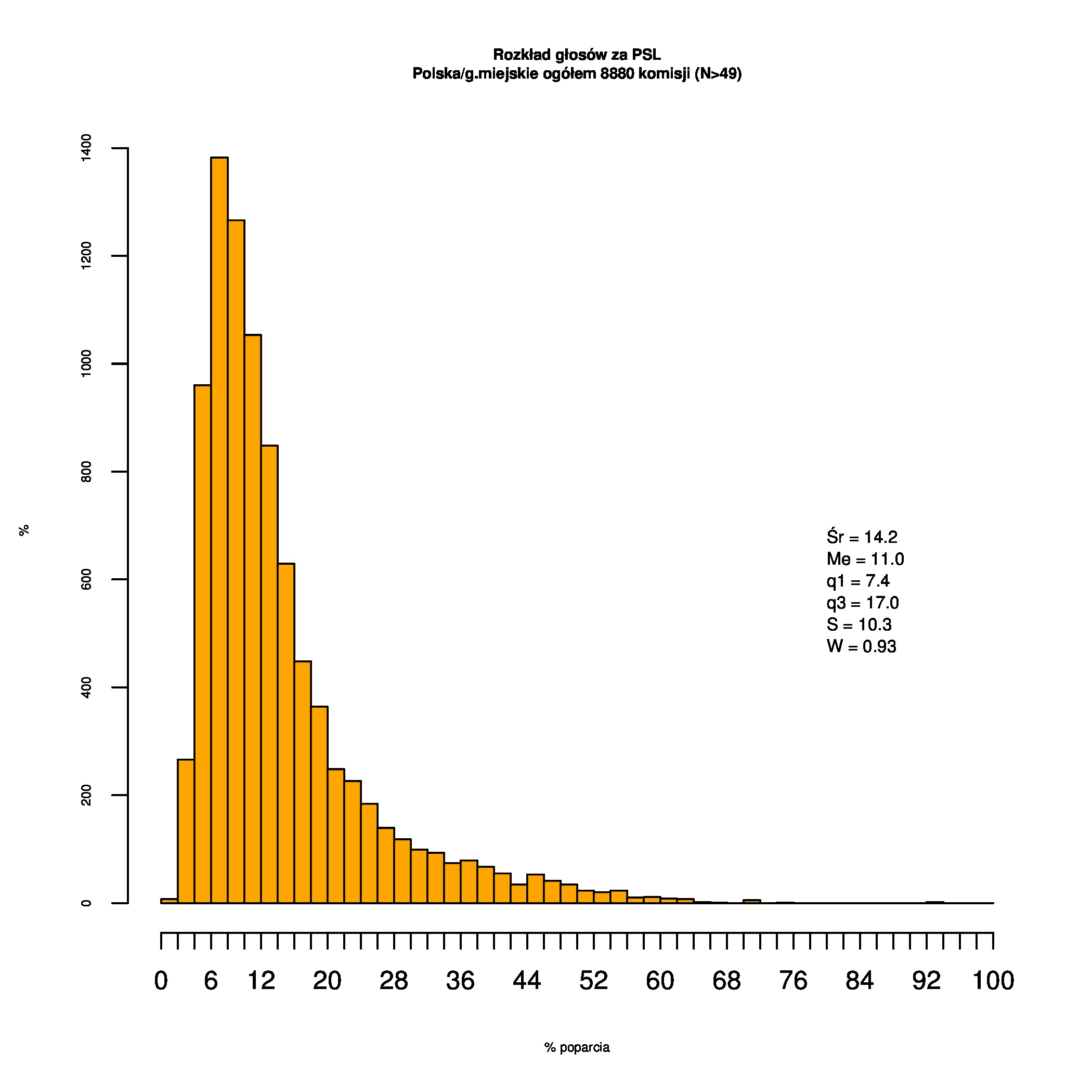
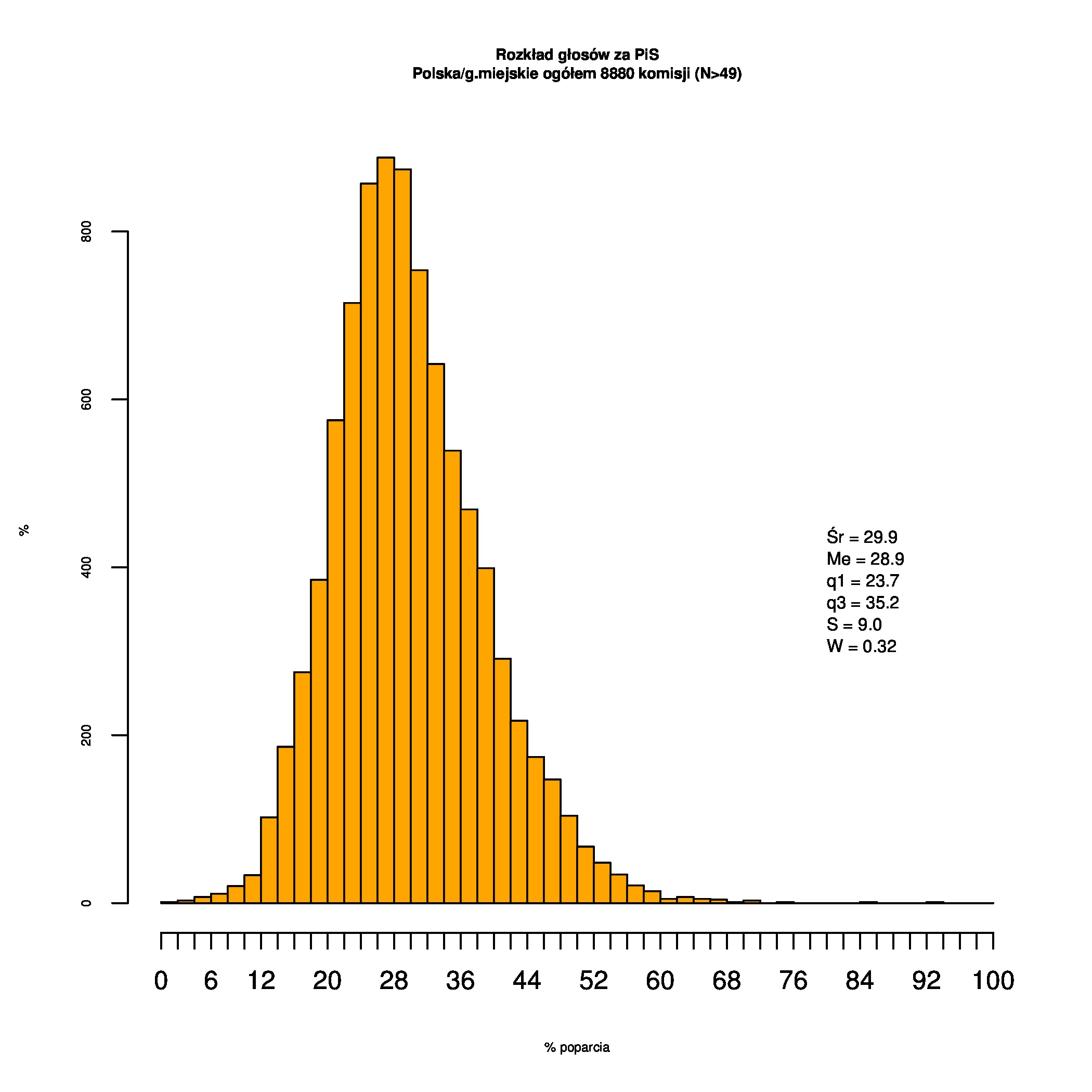
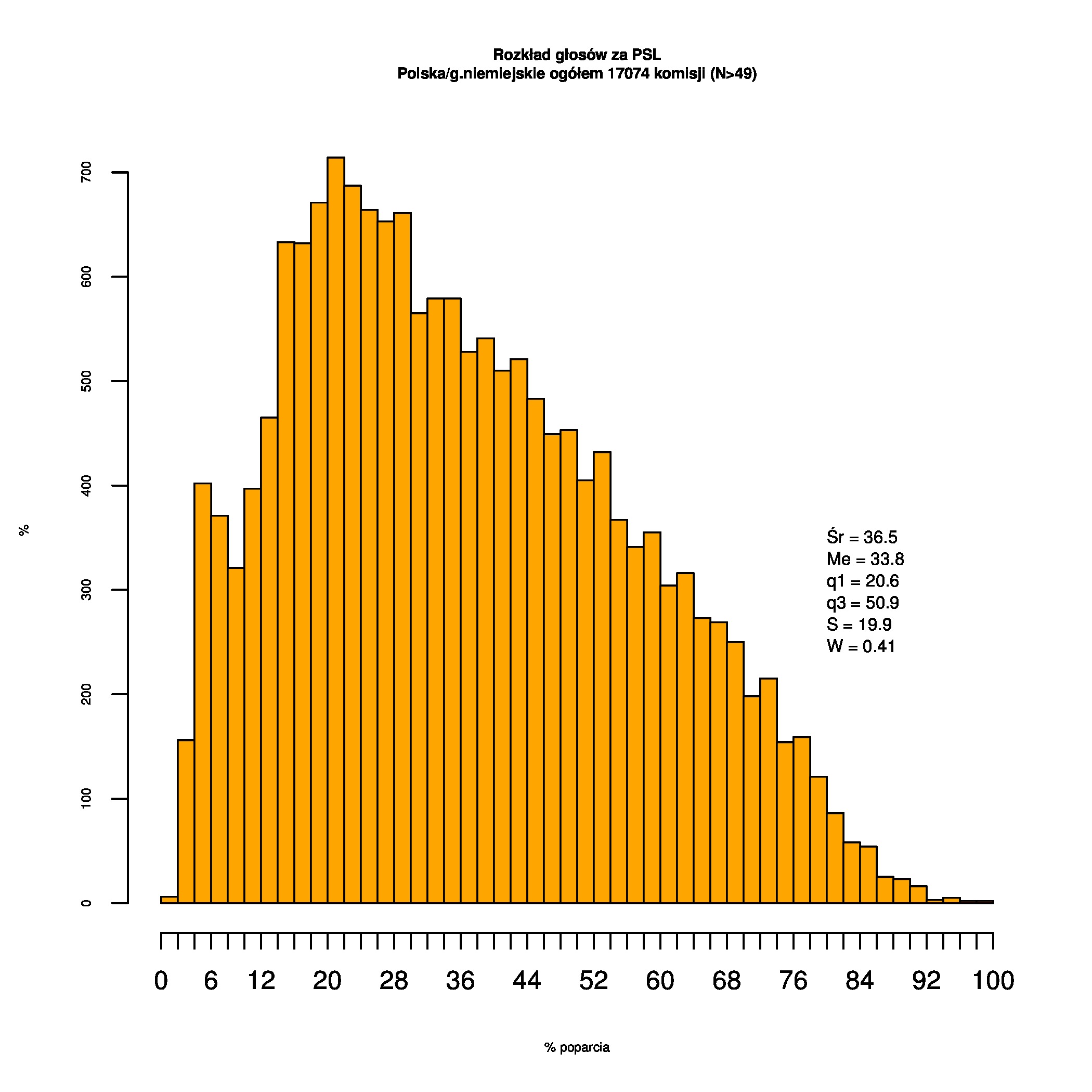
Dla całej Polski wyniki są następujące:
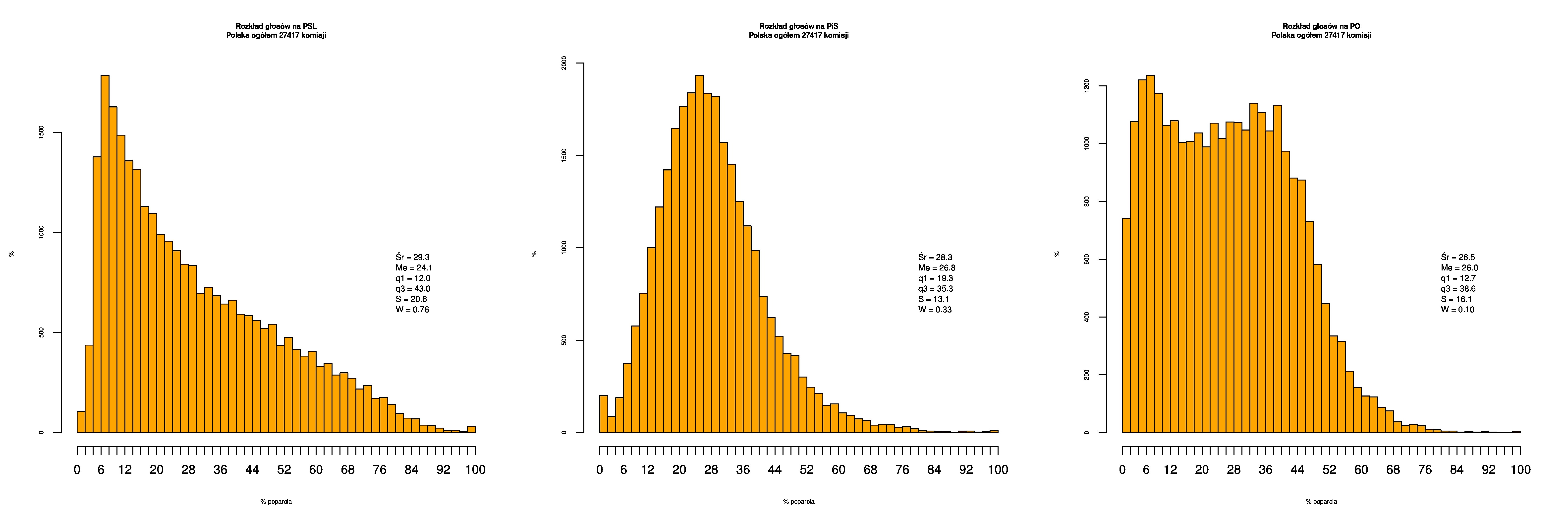
Indywidualne wykresy zaś tutaj: #01 #02 #03 #04 #05 #06 #07 #08 #09 #10 #11 #12 #13 #14 #15 #16 #17 #18 #19 #20 #21 #22 #23 #24 #25 #26 #27 #28 #29 #30 #31 #32 #33 #34 #35 #36 #37 #38 #39 #40 #41 #42 #43 #44 #45 #46 #47 #48 #49 #50 #51 #52 #53 #54 #55 #56 #57 #58 #59 #60):
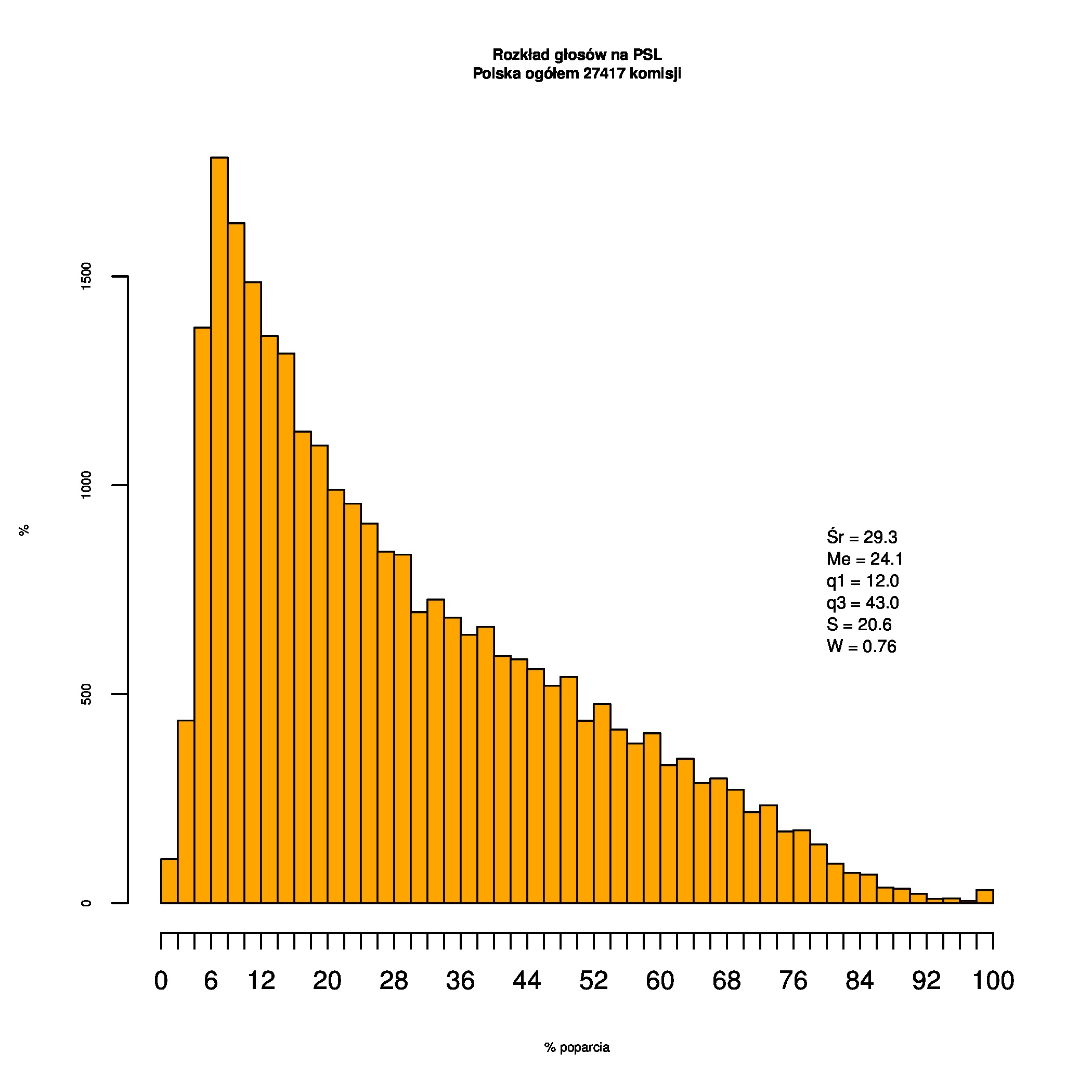{kind=link}
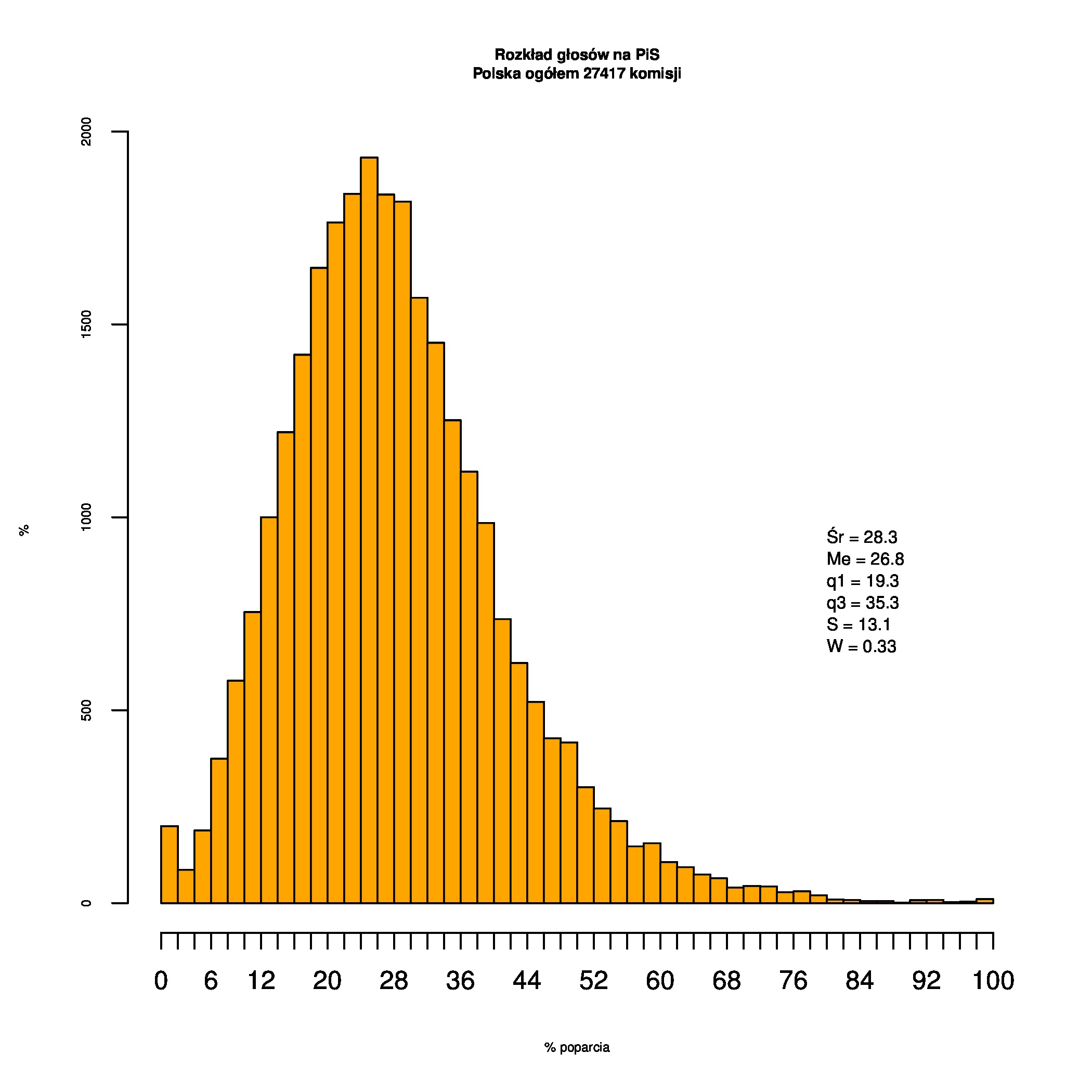{kind=link}
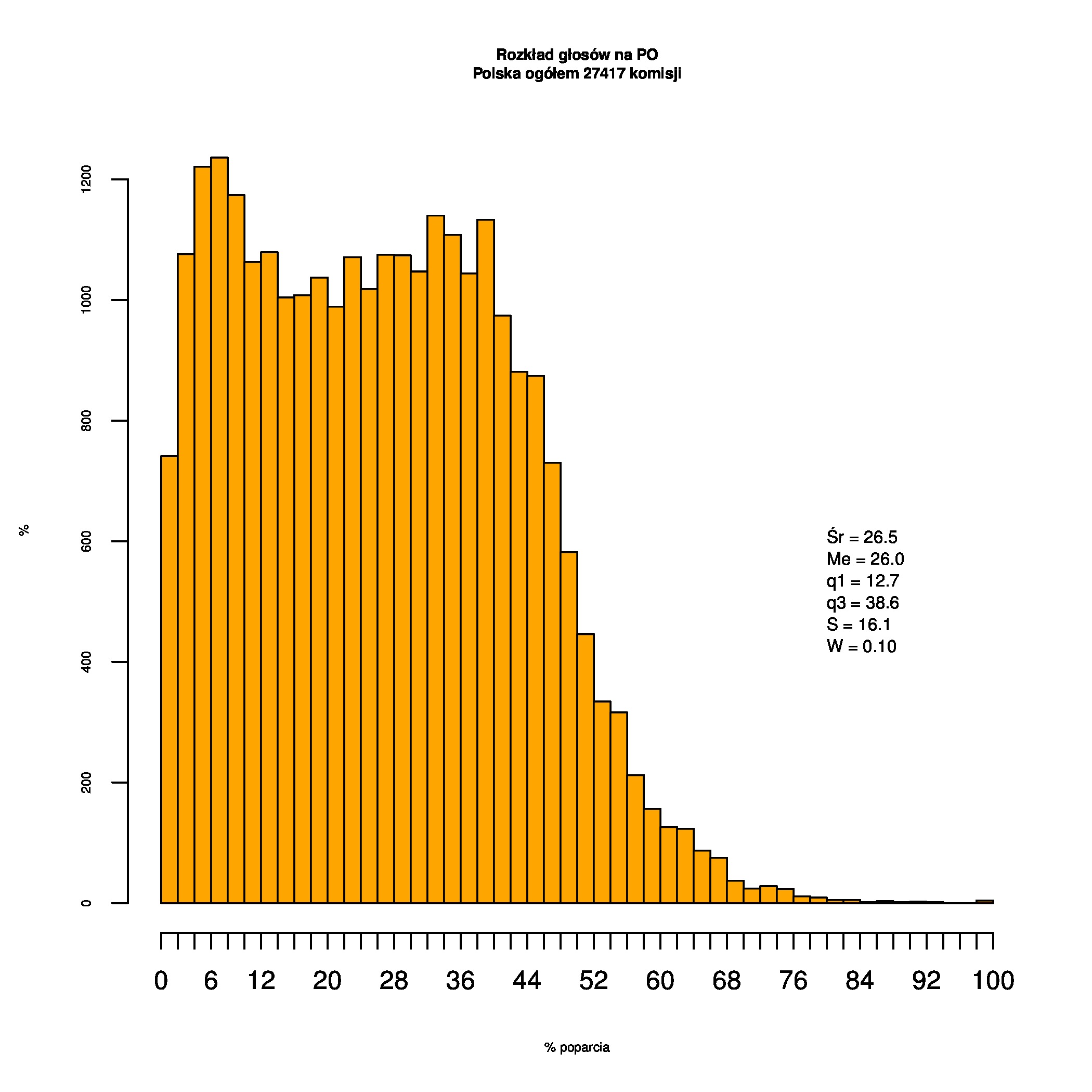{kind=link}
{kind=link}
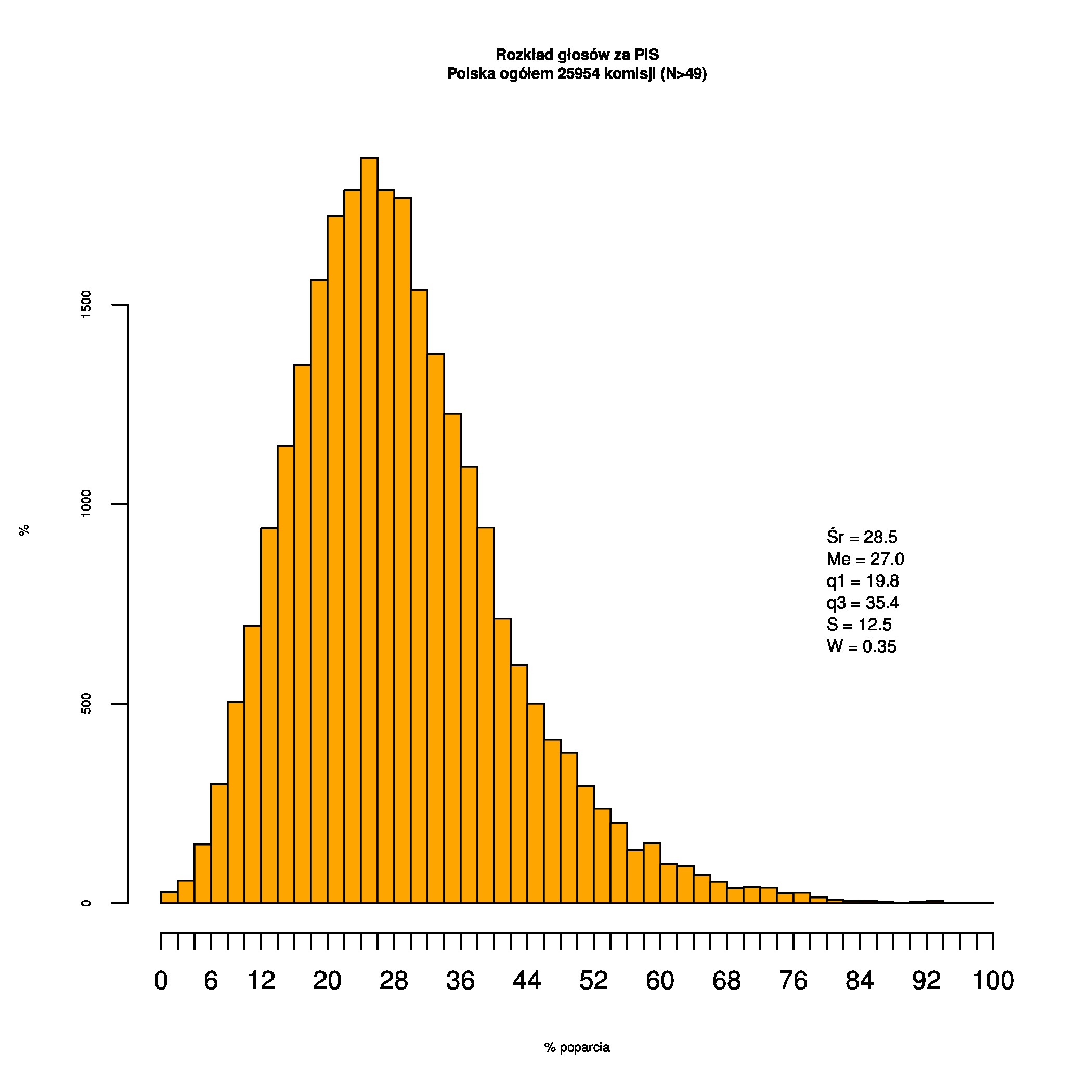{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
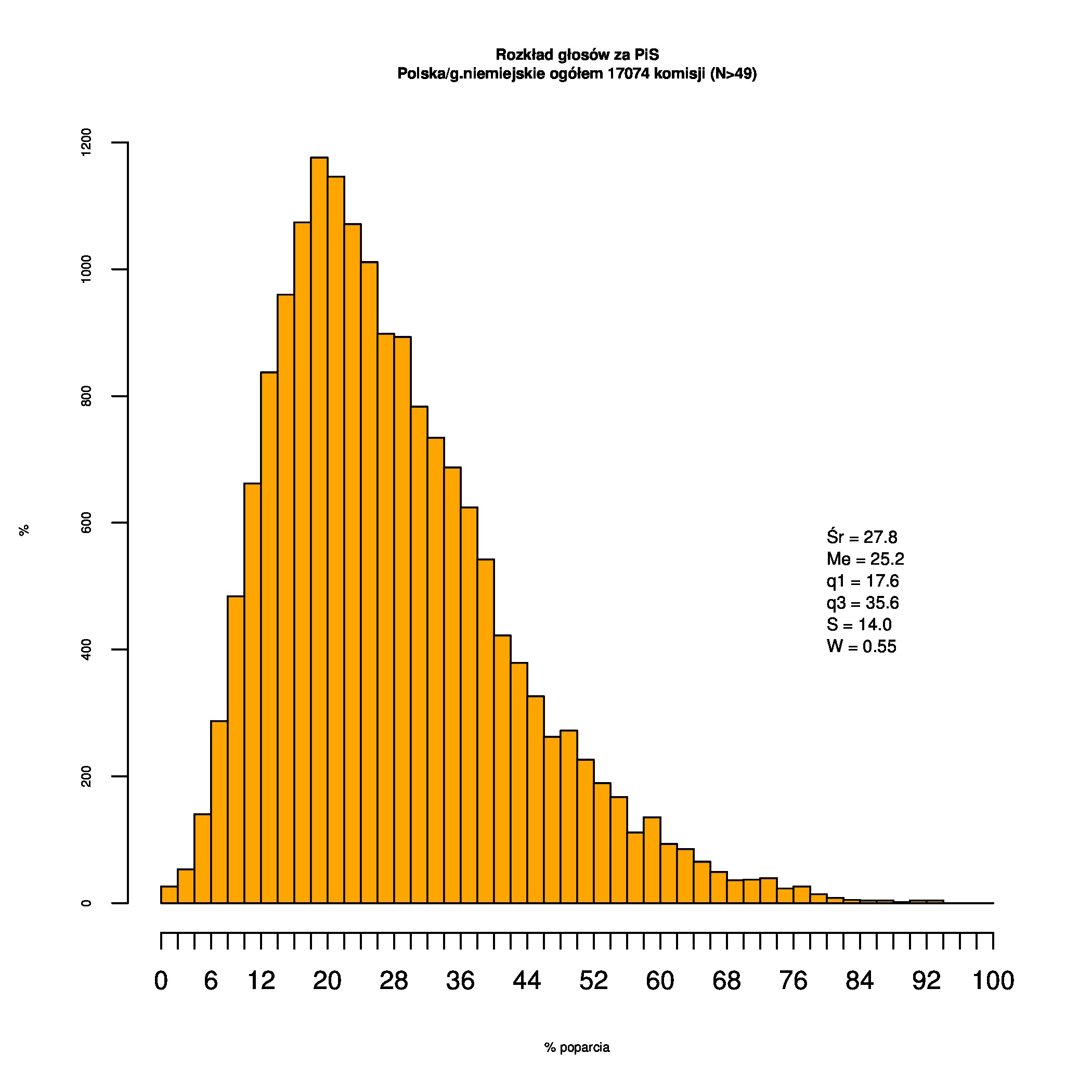{kind=link}
{kind=link}
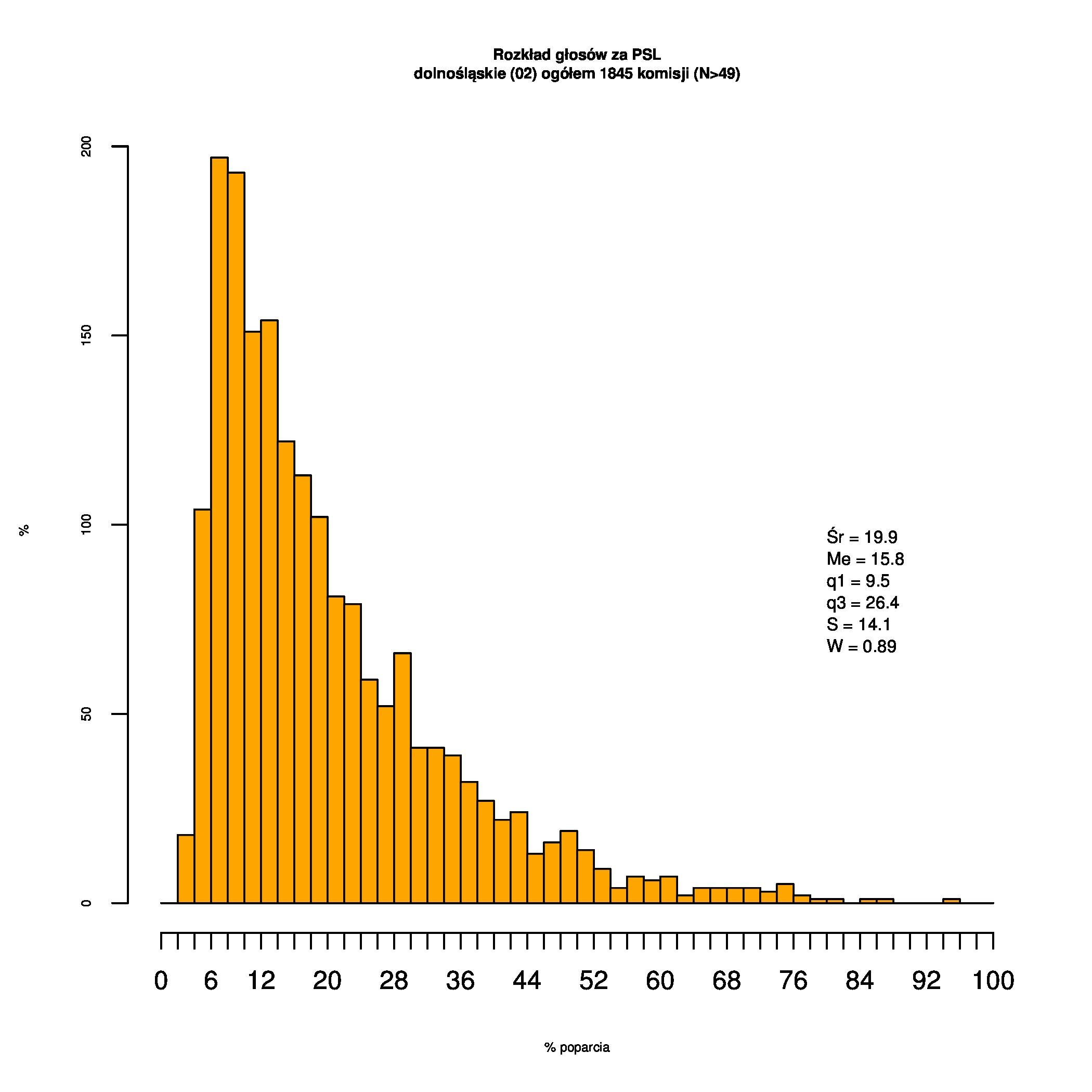{kind=link}
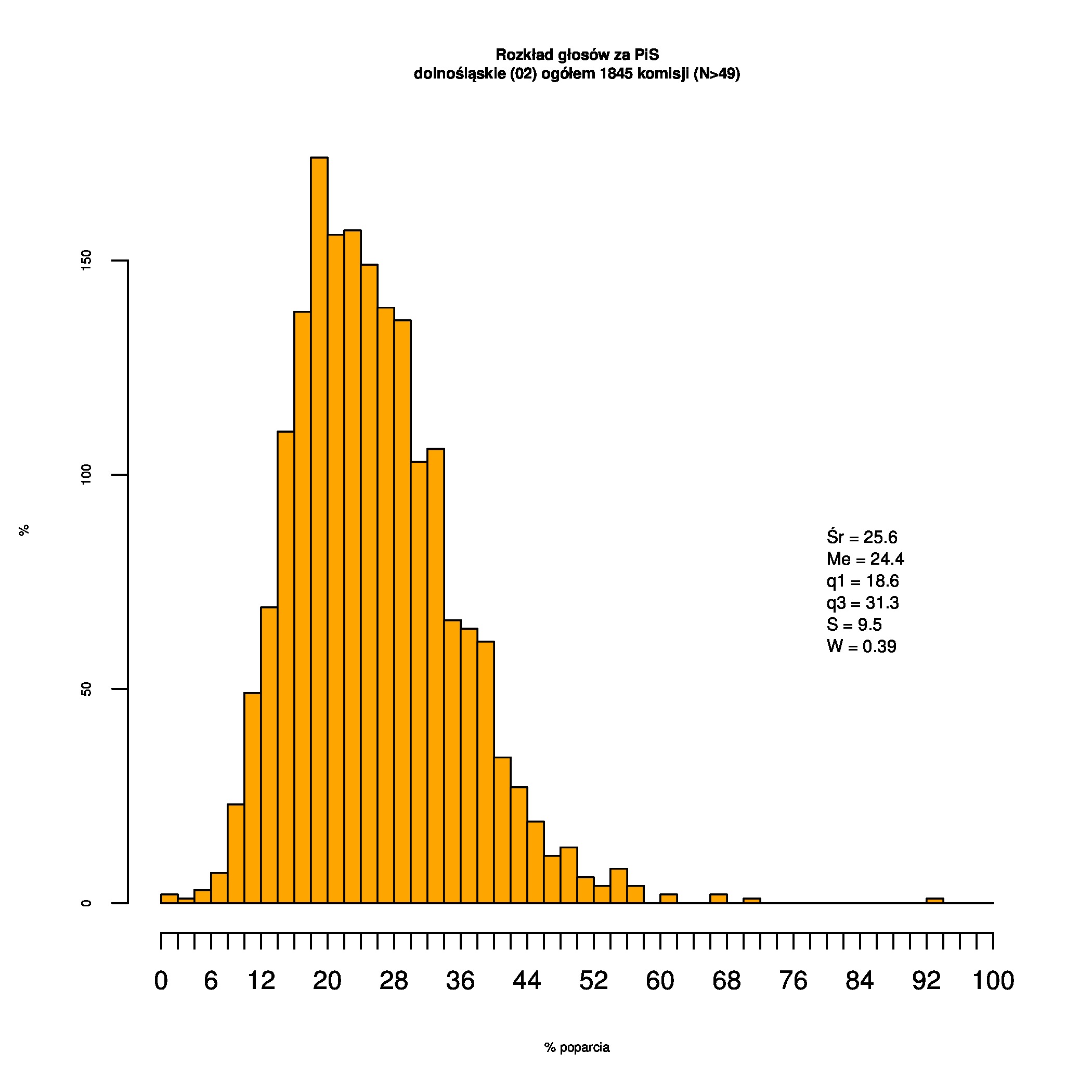{kind=link}
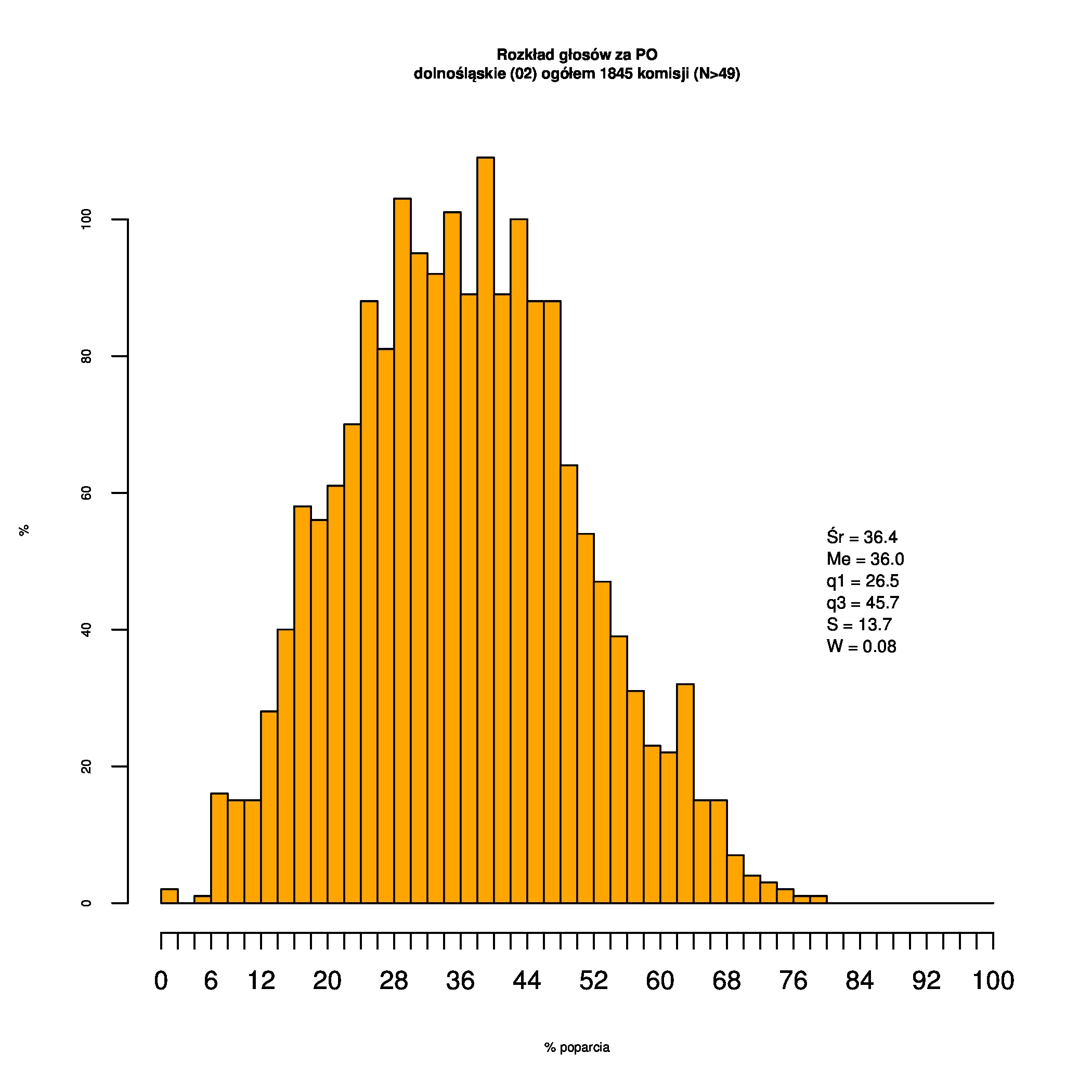{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Brak komentarzy:
Prześlij komentarz